Cognitive Chunking for Soft Prompts: Accelerating Compressor Learning via Block-wise Causal Masking
作者: Guojie Liu, Yiqi Wang, Yanfeng Yang, Wenqi Fan, Songlei Jian, Jianfeng Zhang, Jie Yu
分类: cs.AI, cs.LG
发布日期: 2026-02-15
💡 一句话要点
提出并行迭代压缩PIC,通过分块因果掩码加速软提示压缩器学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软提示压缩 上下文压缩 分块机制 因果掩码 Transformer 大型语言模型 推理加速
📋 核心要点
- 现有软提示压缩方法难以捕获全局依赖,需要大量预训练数据,导致训练困难。
- 论文提出并行迭代压缩(PIC),通过分块因果掩码限制记忆token的感受野,降低训练难度。
- 实验表明,PIC在多个下游任务上优于基线,尤其在高压缩率下提升显著,并加速了训练过程。
📝 摘要(中文)
利用大型语言模型(LLM)能力的关键在于通过提示提供丰富的上下文信息。然而,冗长的上下文会显著增加推理延迟,因为自注意力机制的计算成本随序列长度呈二次方增长。为了缓解这个问题,上下文压缩,特别是软提示压缩,已成为一种广泛研究的解决方案,它通过训练压缩器将长上下文转换为更短的记忆嵌入。现有方法通常不加区分地将整个上下文压缩成一组记忆token,要求压缩器捕获全局依赖关系,并需要大量的预训练数据来学习有效的模式。受人类工作记忆中的分块机制以及记忆嵌入相对于原始token的空间专业化的经验观察的启发,我们提出了并行迭代压缩(PIC)。通过简单地修改Transformer的注意力掩码,PIC显式地将记忆token的感受野限制在连续的局部块中,从而降低了压缩器训练的难度。在多个下游任务上的实验表明,PIC始终优于具有竞争力的基线,尤其是在高压缩率的情况下表现出优越性(例如,在QA任务中,在64倍压缩率下,F1得分相对提高了29.8%,EM得分相对提高了40.7%)。此外,PIC显著加快了训练过程。具体而言,在训练16倍压缩器时,它超过了竞争基线的峰值性能,同时有效地将训练时间减少了约40%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中,长上下文带来的推理延迟问题。现有的软提示压缩方法通常将整个上下文无差别地压缩成一组记忆token,这要求压缩器学习全局依赖关系,需要大量的预训练数据,并且训练效率较低。
核心思路:论文的核心思路是借鉴人类工作记忆的分块机制,将长上下文分割成多个局部块,并让压缩器并行地处理这些块。通过限制记忆token的感受野,使其只关注局部块,从而降低压缩器学习的难度,提高训练效率。
技术框架:PIC的核心是修改Transformer的注意力掩码。具体来说,对于每个记忆token,其注意力范围被限制在输入序列的一个局部块内。多个记忆token并行地处理不同的局部块。通过迭代的方式,逐步压缩整个上下文。整体流程包括:输入长文本,分块,并行压缩各个块,迭代压缩,最终得到压缩后的软提示。
关键创新:PIC的关键创新在于引入了分块因果掩码,显式地限制了记忆token的感受野。这与现有方法中记忆token关注全局上下文的方式不同,降低了压缩器学习的难度,提高了训练效率。
关键设计:PIC的关键设计包括:1) 分块大小的选择:需要根据任务和模型大小进行调整。2) 迭代次数的选择:迭代次数越多,压缩效果越好,但计算成本也越高。3) 注意力掩码的具体实现:论文采用了一种高效的矩阵运算来实现分块因果掩码。
🖼️ 关键图片

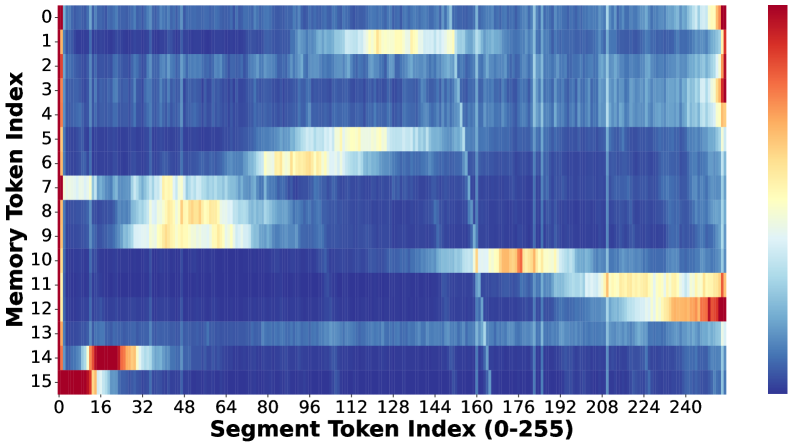
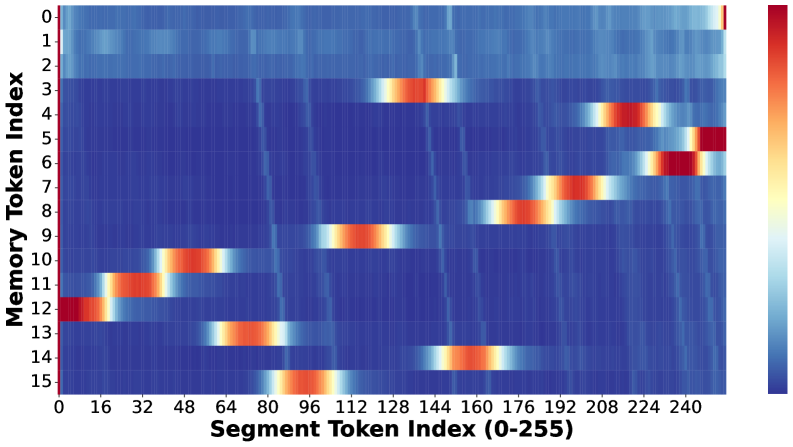
📊 实验亮点
实验结果表明,PIC在多个下游任务上优于竞争基线,尤其在高压缩率下表现突出。例如,在QA任务中,在64倍压缩率下,PIC的F1得分相对提高了29.8%,EM得分相对提高了40.7%。此外,PIC还显著加快了训练过程,在训练16倍压缩器时,训练时间减少了约40%。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的场景,例如问答系统、文本摘要、机器翻译等。通过压缩上下文,可以显著降低推理延迟,提高用户体验。此外,该方法还可以用于训练更高效的语言模型,降低计算成本,促进大型语言模型在资源受限环境中的应用。
📄 摘要(原文)
Providing extensive context via prompting is vital for leveraging the capabilities of Large Language Models (LLMs). However, lengthy contexts significantly increase inference latency, as the computational cost of self-attention grows quadratically with sequence length. To mitigate this issue, context compression-particularly soft prompt compressio-has emerged as a widely studied solution, which converts long contexts into shorter memory embeddings via a trained compressor. Existing methods typically compress the entire context indiscriminately into a set of memory tokens, requiring the compressor to capture global dependencies and necessitating extensive pre-training data to learn effective patterns. Inspired by the chunking mechanism in human working memory and empirical observations of the spatial specialization of memory embeddings relative to original tokens, we propose Parallelized Iterative Compression (PIC). By simply modifying the Transformer's attention mask, PIC explicitly restricts the receptive field of memory tokens to sequential local chunks, thereby lowering the difficulty of compressor training. Experiments across multiple downstream tasks demonstrate that PIC consistently outperforms competitive baselines, with superiority being particularly pronounced in high compression scenarios (e.g., achieving relative improvements of 29.8\% in F1 score and 40.7\% in EM score on QA tasks at the $64\times$ compression ratio). Furthermore, PIC significantly expedites the training process. Specifically, when training the 16$\times$ compressor, it surpasses the peak performance of the competitive baseline while effectively reducing the training time by approximately 40\%.