Eureka-Audio: Triggering Audio Intelligence in Compact Language Models
作者: Dan Zhang, Yishu Lei, Jing Hu, Shuwei He, Songhe Deng, Xianlong Luo, Danxiang Zhu, Shikun Feng, Rui Liu, Jingzhou He, Yu Sun, Hua Wu, Haifeng Wang
分类: cs.SD, cs.AI
发布日期: 2026-02-15
备注: 23 pages, 4 figures
💡 一句话要点
Eureka-Audio:在紧凑型语言模型中激发音频智能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 轻量级模型 混合专家网络 数据增强 副语言理解
📋 核心要点
- 现有音频理解模型通常参数量巨大,计算成本高昂,难以在资源受限的场景中应用。
- Eureka-Audio通过轻量级语言骨干、Whisper音频编码器和MoE适配器,实现了紧凑高效的音频理解。
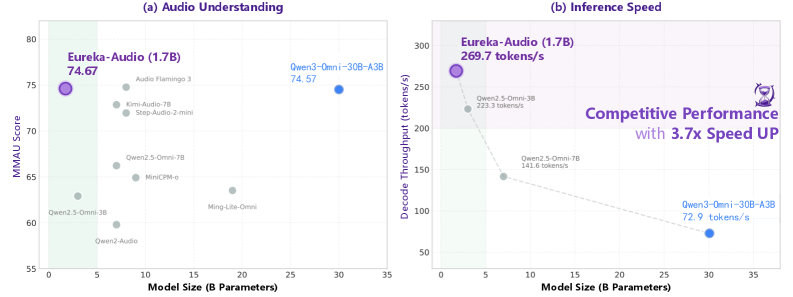
- 实验表明,Eureka-Audio在多个音频理解任务上超越了参数量更大的模型,同时降低了计算成本。
📝 摘要(中文)
本文提出了Eureka-Audio,一个紧凑但高性能的音频语言模型,在广泛的音频理解基准测试中,其性能与参数量大4到18倍的模型相比具有竞争力。尽管仅包含17亿参数,Eureka-Audio在自动语音识别(ASR)、音频理解和密集音频字幕方面表现出强大的性能,匹配或超过了多个70亿到300亿参数的音频和全模态基线模型。该模型采用统一的端到端架构,由轻量级语言骨干网络、基于Whisper的音频编码器和一个稀疏激活的混合专家(MoE)适配器组成,该适配器显式地考虑了音频异质性,并减轻了有限容量下的跨模态优化冲突。为了进一步增强副语言推理能力,我们引入了DataFlux,一个闭环音频指令数据合成和验证流程,从原始音频构建高质量、逻辑一致的监督信息。在ASR、知识推理、安全性、指令跟随和副语言基准测试中的广泛评估表明,Eureka-Audio在计算成本和性能之间实现了有效的平衡。这些结果确立了Eureka-Audio作为轻量级音频理解模型的强大且实用的基线。
🔬 方法详解
问题定义:现有音频理解模型通常参数量巨大,导致计算成本高昂,难以部署在资源受限的设备上。此外,跨模态优化存在冲突,影响模型性能。
核心思路:Eureka-Audio的核心思路是构建一个紧凑但高性能的音频语言模型,通过精心设计的模型架构和数据增强方法,在有限的参数量下实现强大的音频理解能力。该模型旨在平衡计算成本和性能,使其更适用于实际应用。
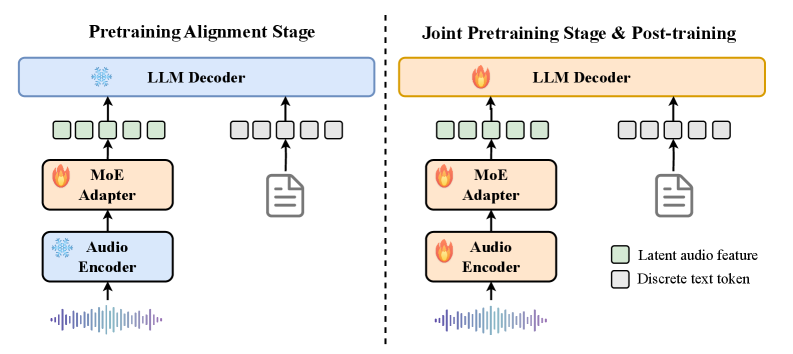
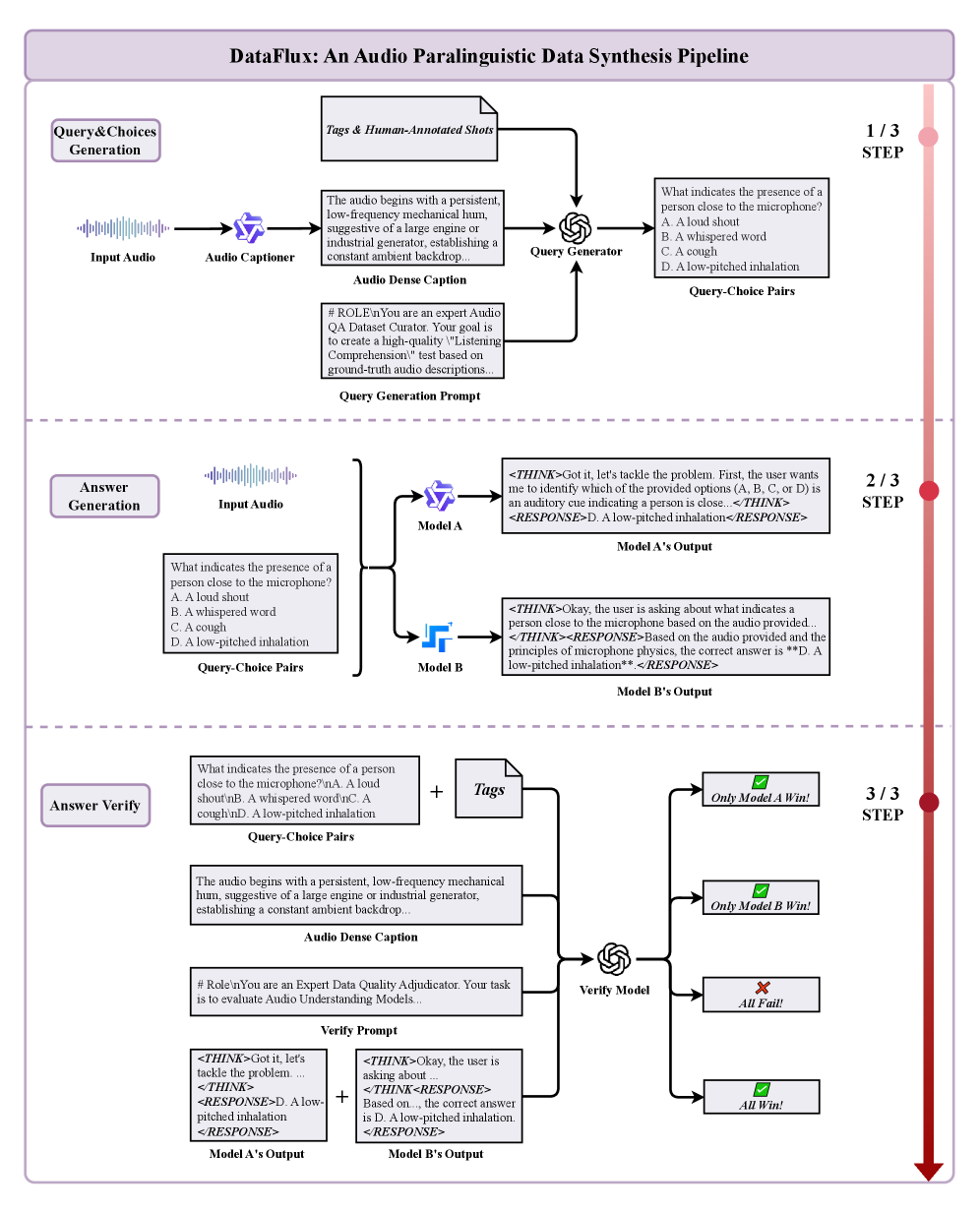
技术框架:Eureka-Audio采用端到端架构,包含以下主要模块:1) 轻量级语言骨干网络:用于处理文本信息。2) 基于Whisper的音频编码器:用于提取音频特征。3) 稀疏激活的混合专家(MoE)适配器:用于处理音频异质性,并缓解跨模态优化冲突。4) DataFlux:闭环音频指令数据合成和验证流程,用于增强副语言推理能力。
关键创新:Eureka-Audio的关键创新在于:1) 提出了一个紧凑的音频语言模型,在参数量较小的情况下实现了高性能。2) 引入了稀疏激活的MoE适配器,显式地考虑了音频异质性,并缓解了跨模态优化冲突。3) 提出了DataFlux数据增强方法,用于生成高质量的音频指令数据,从而增强了模型的副语言推理能力。
关键设计:MoE适配器采用稀疏激活机制,只有部分专家网络被激活,从而降低了计算成本。DataFlux通过闭环流程,迭代地合成和验证音频指令数据,确保数据的质量和逻辑一致性。模型采用交叉熵损失函数进行训练,并使用Adam优化器进行参数更新。
🖼️ 关键图片
📊 实验亮点
Eureka-Audio在自动语音识别(ASR)、音频理解和密集音频字幕等任务上取得了显著的成果。例如,在某些音频理解基准测试中,Eureka-Audio的性能与参数量大4到18倍的模型相比具有竞争力,甚至超过了多个70亿到300亿参数的音频和全模态基线模型。这些结果表明,Eureka-Audio在计算成本和性能之间实现了有效的平衡。
🎯 应用场景
Eureka-Audio具有广泛的应用前景,包括智能助手、语音搜索、音频内容分析、安全监控等领域。其轻量级的特性使其能够部署在移动设备、嵌入式系统等资源受限的平台上,为这些平台带来更强大的音频理解能力。未来,该模型可以进一步扩展到更多模态,实现更全面的多模态理解。
📄 摘要(原文)
We present Eureka-Audio, a compact yet high-performance audio language model that achieves competitive performance against models that are 4 to 18 times larger across a broad range of audio understanding benchmarks. Despite containing only 1.7B parameters, Eureka-Audio demonstrates strong performance on automatic speech recognition (ASR), audio understanding, and dense audio captioning, matching or surpassing multiple 7B to 30B audio and omni-modal baselines. The model adopts a unified end-to-end architecture composed of a lightweight language backbone, a Whisper-based audio encoder, and a sparsely activated Mixture-of-Experts (MoE) adapter that explicitly accounts for audio heterogeneity and alleviates cross-modal optimization conflicts under limited capacity. To further enhance paralinguistic reasoning, we introduce DataFlux, a closed loop audio instruction data synthesis and verification pipeline that constructs high quality, logically consistent supervision from raw audio. Extensive evaluations across ASR, knowledge reasoning, safety, instruction following, and paralinguistic benchmarks, demonstrate that Eureka-Audio achieves an efficient balance between computational cost and performance. These results establish Eureka Audio as a strong and practical baseline for lightweight audio understanding models.