HyMem: Hybrid Memory Architecture with Dynamic Retrieval Scheduling
作者: Xiaochen Zhao, Kaikai Wang, Xiaowen Zhang, Chen Yao, Aili Wang
分类: cs.AI
发布日期: 2026-02-15
💡 一句话要点
HyMem:一种基于动态检索调度的混合记忆架构,提升LLM Agent长时记忆效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长时记忆 LLM Agent 混合记忆架构 动态检索调度 认知经济
📋 核心要点
- 现有LLM Agent在长时对话中面临记忆管理效率瓶颈,无法兼顾信息压缩和复杂推理需求。
- HyMem提出一种混合记忆架构,通过多粒度表示和动态检索调度,模拟人类认知经济原则。
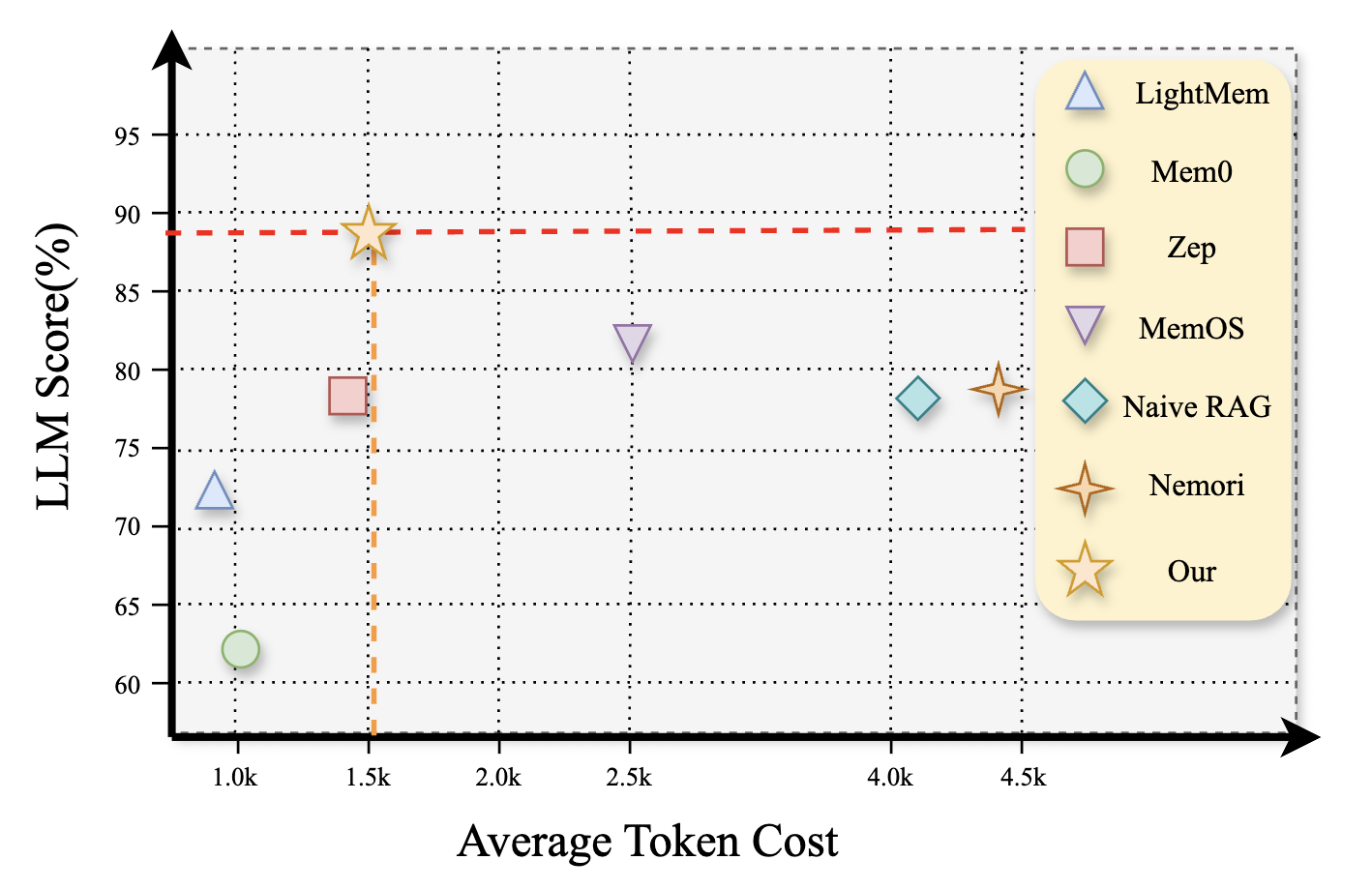
- 实验结果表明,HyMem在性能上优于全上下文方法,同时显著降低了计算成本,提升了效率。
📝 摘要(中文)
大型语言模型(LLM)Agent在短文本环境中表现出色,但在扩展对话中由于记忆管理效率低下而表现不佳。现有方法面临效率和有效性之间的根本权衡:记忆压缩可能丢失复杂推理所需的关键细节,而保留原始文本会为简单查询引入不必要的计算开销。问题的关键在于单一记忆表示和静态检索机制的局限性,这些机制无法模仿人类灵活和主动的记忆调度能力,因此难以适应不同的问题场景。受认知经济原则的启发,我们提出了HyMem,一种混合记忆架构,通过多粒度记忆表示实现动态按需调度。HyMem采用双粒度存储方案,并结合动态双层检索系统:轻量级模块构建摘要级上下文以实现高效的响应生成,而基于LLM的深度模块仅在复杂查询时选择性激活,并通过反射机制进行迭代推理细化。实验表明,HyMem在LOCOMO和LongMemEval基准测试中均表现出色,优于全上下文方法,同时将计算成本降低了92.6%,从而在长期记忆管理中建立了效率和性能之间的最新平衡。
🔬 方法详解
问题定义:现有LLM Agent在处理长时对话时,面临着记忆效率和信息完整性之间的矛盾。简单压缩记忆可能丢失关键细节,影响复杂推理;而保留全部原始文本则会增加计算负担,降低响应速度。因此,如何设计一种既能高效存储信息,又能支持复杂推理的记忆管理机制是亟待解决的问题。
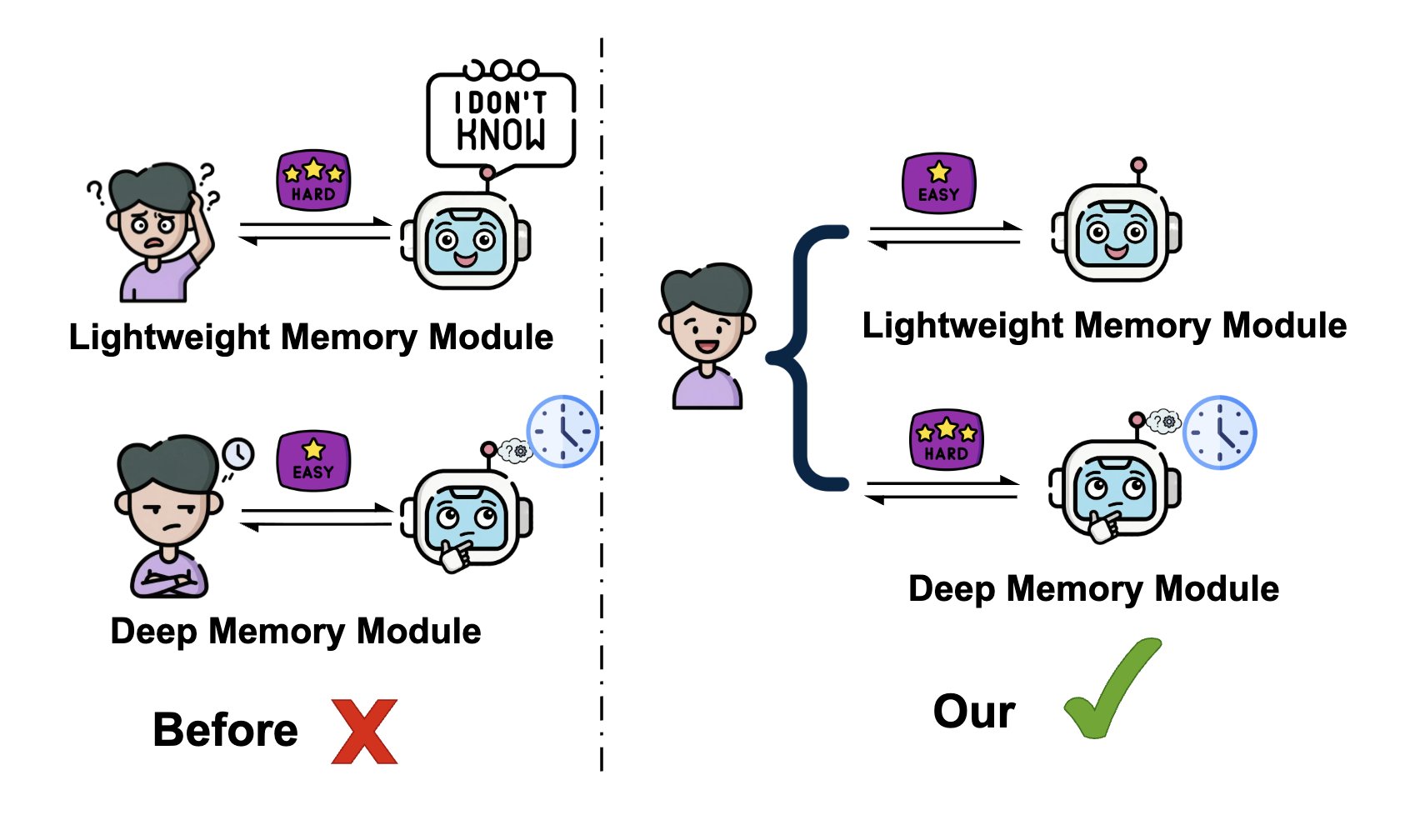
核心思路:HyMem的核心思路是借鉴人类认知经济原则,采用多粒度记忆表示和动态检索调度。通过轻量级模块处理简单查询,深度模块处理复杂查询,从而在效率和性能之间取得平衡。这种按需调度的机制能够有效降低计算成本,同时保证推理的准确性。
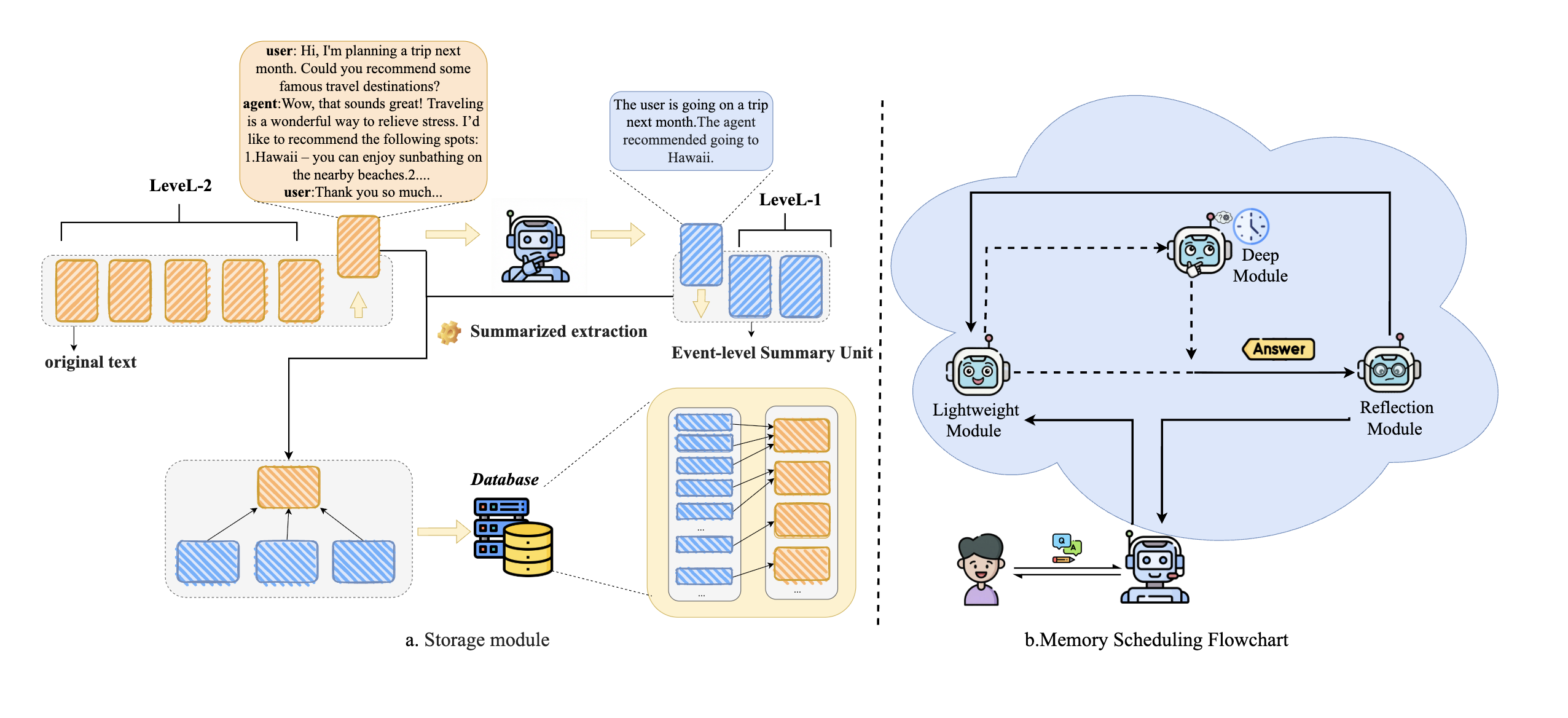
技术框架:HyMem的整体架构包含双粒度存储和动态双层检索两个主要部分。双粒度存储包括摘要级上下文和原始文本。动态双层检索系统包含一个轻量级模块和一个基于LLM的深度模块。对于简单查询,轻量级模块直接利用摘要级上下文生成响应;对于复杂查询,则激活深度模块,并结合反射机制进行迭代推理细化。
关键创新:HyMem的关键创新在于其混合记忆架构和动态检索调度机制。与传统的单一记忆表示方法不同,HyMem采用多粒度表示,能够根据查询的复杂程度选择合适的记忆粒度。动态检索调度机制则能够按需激活不同的模块,从而避免了不必要的计算开销。
关键设计:HyMem的关键设计包括摘要级上下文的构建方法、深度模块的激活策略以及反射机制的实现方式。摘要级上下文可以通过关键词提取、文本摘要等方法生成。深度模块的激活策略可以基于查询的复杂度和历史对话信息进行判断。反射机制则可以通过LLM进行自我评估和修正,从而提高推理的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HyMem在LOCOMO和LongMemEval基准测试中均表现出色,优于全上下文方法。同时,HyMem将计算成本降低了92.6%,在长期记忆管理中实现了效率和性能之间的最佳平衡。这些结果验证了HyMem架构的有效性和优越性。
🎯 应用场景
HyMem架构可应用于各种需要长期记忆和复杂推理的LLM Agent场景,例如智能客服、对话式问答系统、智能助手等。该研究成果有助于提升LLM Agent在复杂任务中的表现,并降低计算成本,推动LLM Agent在实际应用中的普及。
📄 摘要(原文)
Large language model (LLM) agents demonstrate strong performance in short-text contexts but often underperform in extended dialogues due to inefficient memory management. Existing approaches face a fundamental trade-off between efficiency and effectiveness: memory compression risks losing critical details required for complex reasoning, while retaining raw text introduces unnecessary computational overhead for simple queries. The crux lies in the limitations of monolithic memory representations and static retrieval mechanisms, which fail to emulate the flexible and proactive memory scheduling capabilities observed in humans, thus struggling to adapt to diverse problem scenarios. Inspired by the principle of cognitive economy, we propose HyMem, a hybrid memory architecture that enables dynamic on-demand scheduling through multi-granular memory representations. HyMem adopts a dual-granular storage scheme paired with a dynamic two-tier retrieval system: a lightweight module constructs summary-level context for efficient response generation, while an LLM-based deep module is selectively activated only for complex queries, augmented by a reflection mechanism for iterative reasoning refinement. Experiments show that HyMem achieves strong performance on both the LOCOMO and LongMemEval benchmarks, outperforming full-context while reducing computational cost by 92.6\%, establishing a state-of-the-art balance between efficiency and performance in long-term memory management.