GSRM: Generative Speech Reward Model for Speech RLHF
作者: Maohao Shen, Tejas Jayashankar, Osama Hanna, Naoyuki Kanda, Yancheng Wang, Kateřina Žmolíková, Ruiming Xie, Niko Moritz, Anfeng Xu, Yashesh Gaur, Gregory Wornell, Qing He, Jilong Wu
分类: cs.SD, cs.AI
发布日期: 2026-02-14
💡 一句话要点
提出GSRM:一种用于语音RLHF的生成式语音奖励模型,提升语音自然度评估与生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音合成 自然度评估 生成式奖励模型 链式思考 强化学习 语音LLM RLHF
📋 核心要点
- 现有语音自然度评估器通常将原始音频回归到标量分数,缺乏可解释性,且难以泛化到不同类型的语音。
- GSRM通过生成式奖励建模,将语音自然度评估分解为可解释的声学特征提取和链式思考推理,提供可解释的判断。
- 实验表明,GSRM在自然度预测方面优于现有方法,并能作为RLHF的验证器,提升语音LLM生成的自然度。
📝 摘要(中文)
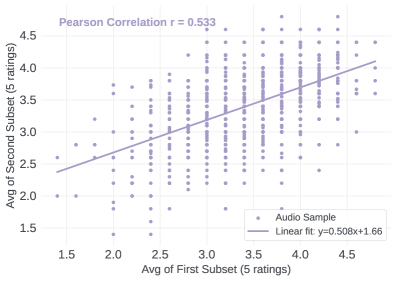
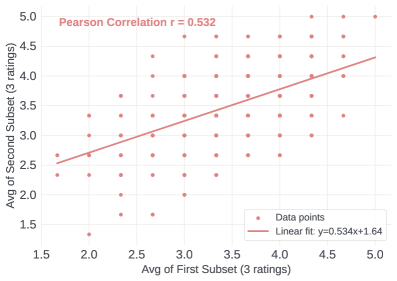
本文提出了一种生成式语音奖励模型(GSRM),专门用于提升语音的自然度。GSRM将语音自然度评估分解为可解释的声学特征提取阶段,然后进行基于特征的链式思考推理,从而实现可解释的判断。为此,作者构建了一个大规模的人工反馈数据集,包含31k个专家评分以及真实世界用户-助手语音交互的领域外基准。实验表明,GSRM显著优于现有的语音自然度预测器,其自然度评分预测的模型-人类相关性接近人类评分者之间的一致性。此外,GSRM可以作为在线RLHF的有效验证器,从而提高语音LLM生成的自然度。
🔬 方法详解
问题定义:论文旨在解决语音合成领域中,现有语音自然度评估方法缺乏可解释性和泛化能力的问题。现有方法通常直接将原始音频映射到标量自然度评分,无法提供评估过程的解释,并且在面对不同类型的语音时表现不佳。这使得难以针对性地改进语音合成模型,尤其是难以利用强化学习从人类反馈中学习(RLHF)。
核心思路:论文的核心思路是将语音自然度评估分解为两个阶段:首先提取可解释的声学特征,然后基于这些特征进行链式思考推理,最终给出自然度评分。这种分解使得评估过程更加透明,并且可以针对性地改进特征提取和推理过程。此外,生成式奖励模型能够更好地捕捉人类对语音自然度的细微偏好。
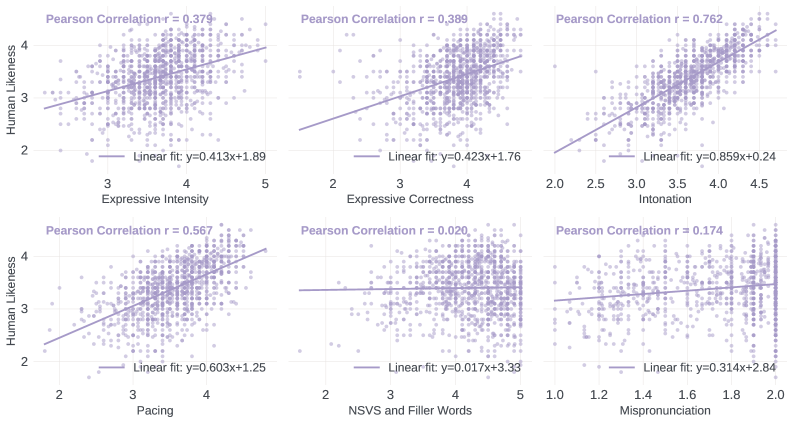
技术框架:GSRM的整体框架包含两个主要模块:声学特征提取模块和链式思考推理模块。声学特征提取模块负责从输入的语音信号中提取相关的声学特征,例如梅尔频谱系数(MFCC)、音高、能量等。链式思考推理模块则基于这些特征,通过一系列的推理步骤,最终生成一个自然度评分。该模块通常采用Transformer架构,并经过训练以模拟人类专家对语音自然度的判断过程。
关键创新:GSRM的关键创新在于其将语音自然度评估分解为可解释的特征提取和链式思考推理两个阶段。与现有方法直接回归标量评分不同,GSRM能够提供评估过程的解释,并且可以针对性地改进特征提取和推理过程。此外,GSRM采用了生成式奖励建模的思想,能够更好地捕捉人类对语音自然度的细微偏好。
关键设计:GSRM的关键设计包括:1) 精心设计的声学特征集,能够捕捉语音的各种重要属性;2) 基于Transformer的链式思考推理模块,能够模拟人类专家的推理过程;3) 大规模的人工反馈数据集,用于训练和评估GSRM的性能;4) 特定的损失函数,用于优化GSRM的特征提取和推理能力。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
GSRM在语音自然度预测方面取得了显著的成果,其模型-人类相关性接近人类评分者之间的一致性,表明GSRM能够很好地模拟人类对语音自然度的判断。此外,GSRM还可以作为在线RLHF的有效验证器,从而提高语音LLM生成的自然度。具体提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
GSRM可应用于语音合成、语音助手、语音交互等领域。它可以作为语音合成模型的评估指标,指导模型的训练和优化,提高合成语音的自然度。在语音助手中,GSRM可以用于评估用户语音的质量,并根据评估结果调整助手的响应策略。此外,GSRM还可以用于开发更自然、更人性化的语音交互系统,提升用户体验。
📄 摘要(原文)
Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.