Enabling Option Learning in Sparse Rewards with Hindsight Experience Replay
作者: Gabriel Romio, Mateus Begnini Melchiades, Bruno Castro da Silva, Gabriel de Oliveira Ramos
分类: cs.AI, cs.LG, cs.RO
发布日期: 2026-02-14
💡 一句话要点
提出MOC-2HER,通过双目标逆向经验回放解决稀疏奖励下的机械臂操作学习问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 逆向经验回放 稀疏奖励 机器人操作 多目标学习
📋 核心要点
- 传统分层强化学习在稀疏奖励多目标任务中,难以将动作与远期结果关联,导致学习效率低下。
- 提出双目标逆向经验回放(2HER),同时考虑物体最终状态和代理执行器位置,生成双重虚拟目标。
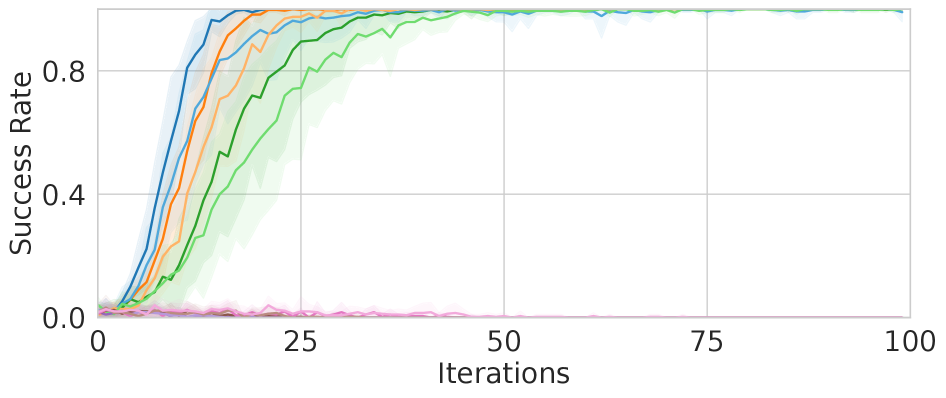
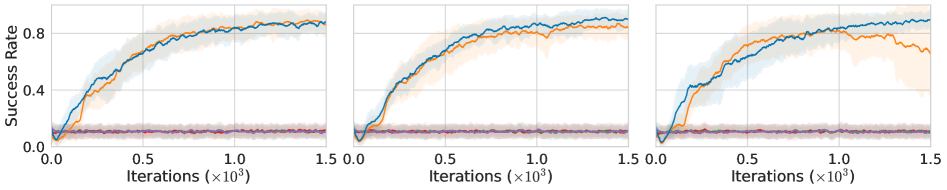
- 实验表明,MOC-2HER在机械臂操作任务中成功率高达90%,显著优于MOC和MOC-HER。
📝 摘要(中文)
分层强化学习框架,如Option-Critic (OC)和Multi-updates Option Critic (MOC),在学习可复用选项方面取得了显著进展。然而,这些方法在具有稀疏奖励的多目标环境中表现不佳,因为在这些环境中,动作必须与时间上遥远的结果相关联。为了解决这个限制,我们首先提出了MOC-HER,它将逆向经验回放(HER)机制集成到MOC框架中。通过从已实现的结果中重新标记目标,MOC-HER可以解决原始MOC难以处理的稀疏奖励环境。然而,这种方法对于物体操作任务来说是不够的,因为在物体操作任务中,奖励取决于物体是否到达目标,而不是代理的直接交互。这使得HRL代理极难发现如何与这些物体交互。为了克服这个问题,我们引入了双目标逆向经验回放(2HER),这是一个新颖的扩展,它创建了两组虚拟目标。除了基于物体的最终状态重新标记目标(标准HER)之外,2HER还从代理的末端执行器位置生成目标,奖励代理与物体的交互和完成任务。在机器人操作环境中的实验结果表明,MOC-2HER的成功率高达90%,而MOC和MOC-HER的成功率均低于11%。这些结果突出了我们的双目标重标记策略在稀疏奖励、多目标任务中的有效性。
🔬 方法详解
问题定义:论文旨在解决稀疏奖励环境下,机器人操作任务中,传统分层强化学习方法难以有效学习的问题。现有方法,如MOC,在奖励稀疏时,难以探索到有效动作序列。即使引入HER,也难以解决奖励依赖于物体状态而非代理直接交互的问题。
核心思路:核心思路是引入双目标逆向经验回放(2HER),通过同时考虑物体最终状态和代理的末端执行器位置,生成两组虚拟目标。这样,即使物体没有到达最终目标,代理也能因为与物体的交互而获得奖励,从而引导探索。
技术框架:整体框架基于MOC,并集成了HER和2HER。MOC负责学习选项策略和值函数,HER负责基于已实现的目标重新标记轨迹,2HER则进一步生成基于代理执行器位置的虚拟目标。训练过程中,代理与环境交互,收集经验数据,然后使用MOC、HER和2HER更新策略和值函数。
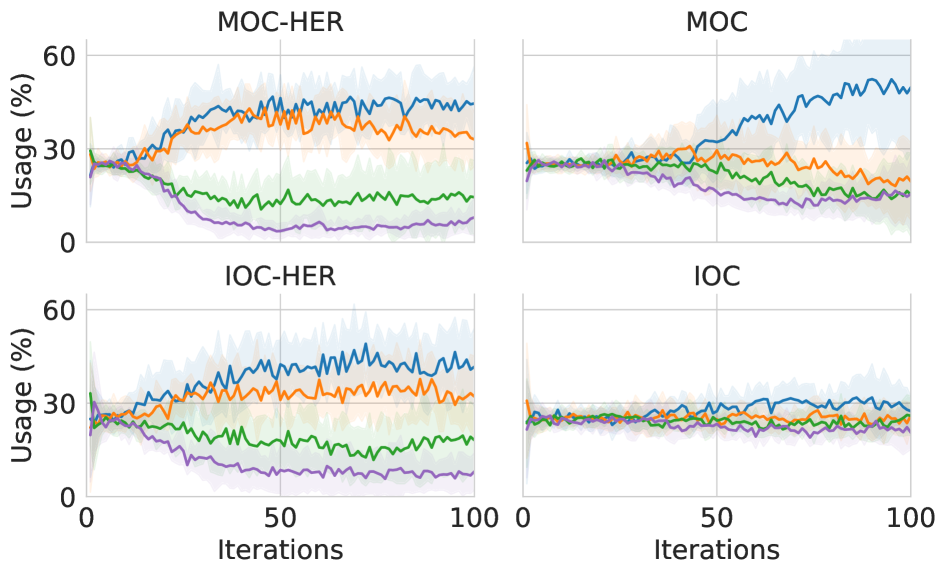
关键创新:关键创新在于2HER的双目标重标记策略。与传统的HER只关注最终目标状态不同,2HER同时关注代理与物体的交互过程,通过奖励代理的交互行为,克服了奖励稀疏和奖励依赖于物体状态的难题。
关键设计:2HER的关键设计在于如何生成基于代理执行器位置的虚拟目标。具体实现方式未知,但推测可能是随机选择代理在轨迹中的某个执行器位置作为虚拟目标,并计算相应的奖励。损失函数方面,可能需要对两个目标的奖励进行加权,以平衡最终目标和交互行为的重要性。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在机器人操作环境中,MOC-2HER的成功率高达90%,而MOC和MOC-HER的成功率均低于11%。这表明,双目标逆向经验回放(2HER)能够显著提高分层强化学习在稀疏奖励环境下的学习效率和性能,为解决复杂的机器人操作任务提供了新的思路。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,尤其是在奖励稀疏、任务复杂的环境中,例如:自动装配、物流分拣、医疗手术等。通过学习可复用的选项,机器人可以更高效地完成任务,并具备更强的泛化能力,从而降低开发成本,提高生产效率。
📄 摘要(原文)
Hierarchical Reinforcement Learning (HRL) frameworks like Option-Critic (OC) and Multi-updates Option Critic (MOC) have introduced significant advancements in learning reusable options. However, these methods underperform in multi-goal environments with sparse rewards, where actions must be linked to temporally distant outcomes. To address this limitation, we first propose MOC-HER, which integrates the Hindsight Experience Replay (HER) mechanism into the MOC framework. By relabeling goals from achieved outcomes, MOC-HER can solve sparse reward environments that are intractable for the original MOC. However, this approach is insufficient for object manipulation tasks, where the reward depends on the object reaching the goal rather than on the agent's direct interaction. This makes it extremely difficult for HRL agents to discover how to interact with these objects. To overcome this issue, we introduce Dual Objectives Hindsight Experience Replay (2HER), a novel extension that creates two sets of virtual goals. In addition to relabeling goals based on the object's final state (standard HER), 2HER also generates goals from the agent's effector positions, rewarding the agent for both interacting with the object and completing the task. Experimental results in robotic manipulation environments show that MOC-2HER achieves success rates of up to 90%, compared to less than 11% for both MOC and MOC-HER. These results highlight the effectiveness of our dual objective relabeling strategy in sparse reward, multi-goal tasks.