Attention in Constant Time: Vashista Sparse Attention for Long-Context Decoding with Exponential Guarantees
作者: Vashista Nobaub
分类: cs.AI, cs.LG, stat.ML
发布日期: 2026-02-14
备注: 22 pages
💡 一句话要点
提出Vashista稀疏注意力以解决长上下文解码效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文解码 稀疏注意力 熵注意力 推理效率 自然语言处理
📋 核心要点
- 现有大型语言模型在长上下文推理中计算成本高,且注意力机制效率低下,导致性能瓶颈。
- 论文提出Vashista稀疏注意力机制,通过对关键向量的有效选择,减少不必要的计算,提升推理效率。
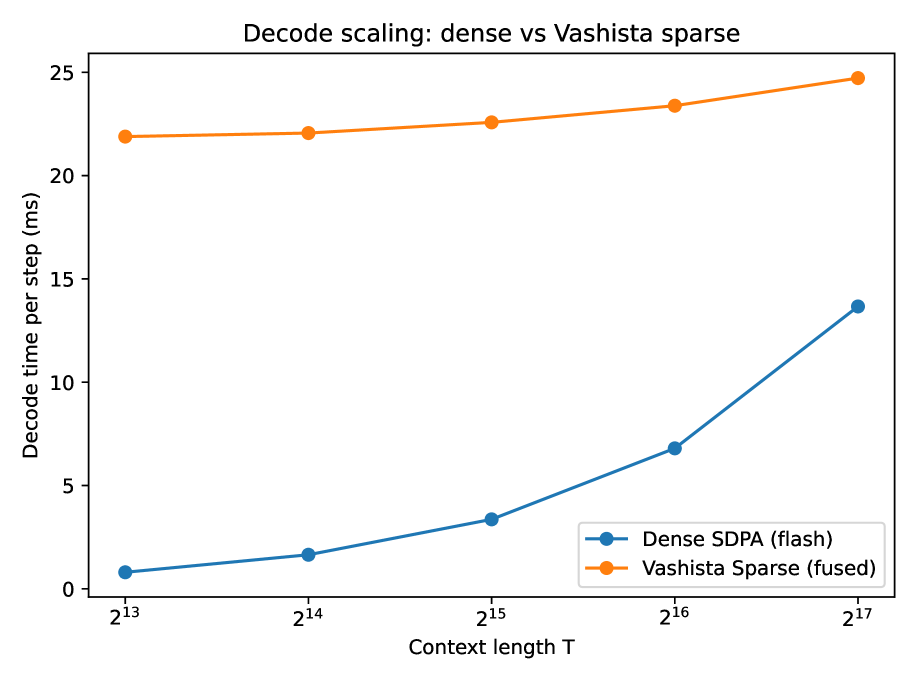
- 实验结果表明,该方法在长上下文评估中实现了稳定的有效支持和显著的速度提升,质量损失极小。
📝 摘要(中文)
大型语言模型在长上下文推理中大部分计算成本集中于注意力机制,但实证表明,只有少量token对每个查询有实质性贡献。本文通过将注意力建模为对关键向量的凸包投影,并分析其熵(类似softmax)松弛,提出了面稳定性定理,证明在严格互补边际下,熵注意力集中于常量大小的活跃面。基于这些理论保证,提出了Vashista稀疏注意力机制,采用分页式上下文选择策略,能够在长上下文评估中实现稳定的常量有效支持,显著加快推理速度,同时保持质量损失最小。最后,讨论了在隐私敏感和隔离环境中的部署影响。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在长上下文推理中注意力计算效率低的问题。现有方法在处理长上下文时,往往需要对所有token进行计算,导致计算成本高昂。
核心思路:论文提出的Vashista稀疏注意力机制通过建立在熵注意力理论基础上的面稳定性定理,确保注意力集中于常量大小的活跃面,从而减少对不活跃token的计算。
技术框架:该方法采用分页式上下文选择策略,首先为每个查询维护一个小的候选集,然后根据熵注意力的理论保证进行有效的token选择,最终实现高效的推理过程。
关键创新:最重要的创新在于提出了面稳定性定理,证明了在严格互补边际下,熵注意力能够有效集中于常量大小的活跃面,这与传统的全量注意力机制形成鲜明对比。
关键设计:在设计中,设置了严格的互补边际参数(Δ),并通过KKT乘子进行认证。同时,调整了温度/正则化参数(ε),以控制活跃面上的误差,从而实现精度与计算量之间的平衡。
🖼️ 关键图片
📊 实验亮点
实验结果显示,Vashista稀疏注意力机制在长上下文评估中实现了稳定的常量有效支持,推理速度提升显著,且在支持边际预测的范围内,质量损失保持在最低水平。具体而言,推理速度提升可达数倍,且在大多数情况下,生成质量与全量注意力相当。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的长文本生成、对话系统以及任何需要处理长上下文的任务。通过提高推理效率,Vashista稀疏注意力机制能够在资源受限的环境中实现更快的响应时间,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large language models spend most of their inference cost on attention over long contexts, yet empirical behavior suggests that only a small subset of tokens meaningfully contributes to each query. We formalize this phenomenon by modeling attention as a projection onto the convex hull of key vectors and analyzing its entropic (softmax-like) relaxation. Our main theoretical contribution is a face-stability theorem showing that, under a strict complementarity margin (a support gap (Δ) certified by KKT multipliers), entropic attention concentrates on a constant-size active face: the total mass assigned to inactive tokens decays exponentially as (\exp(-Ω(Δ/\varepsilon))), while the error on the active face scales linearly in the temperature/regularization parameter (\varepsilon). This yields a practical criterion for when sparse long-context decoding is safe and provides a principled knob to trade accuracy for compute. Building on these guarantees, we introduce Vashista Sparse Attention, a drop-in mechanism that maintains a small candidate set per query through a paging-style context selection strategy compatible with modern inference stacks. Across long-context evaluations, we observe stable constant-size effective support, strong wall-clock speedups, and minimal quality degradation in the regimes predicted by the support-gap diagnostics. Finally, we discuss deployment implications for privacy-sensitive and air-gapped settings, where interchangeable attention modules enable predictable latency and cost without external retrieval dependencies.