OneLatent: Single-Token Compression for Visual Latent Reasoning
作者: Bo Lv, Yasheng Sun, Junjie Wang, Haoxiang Shi
分类: cs.AI
发布日期: 2026-02-14
💡 一句话要点
OneLatent:通过单token压缩视觉潜在推理,降低CoT推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉推理 链式思考 单Token压缩 知识蒸馏 OCR 长链推理 模型压缩
📋 核心要点
- CoT推理虽能提升模型推理能力,但显著增加了推理成本,成为实际应用的瓶颈。
- OneLatent将中间推理步骤压缩为单个潜在token,通过视觉渲染和OCR隐藏状态进行监督,实现高效推理。
- 实验表明,OneLatent在保证准确率的同时,大幅降低了输出长度,提高了token利用率,尤其在长链推理中表现出色。
📝 摘要(中文)
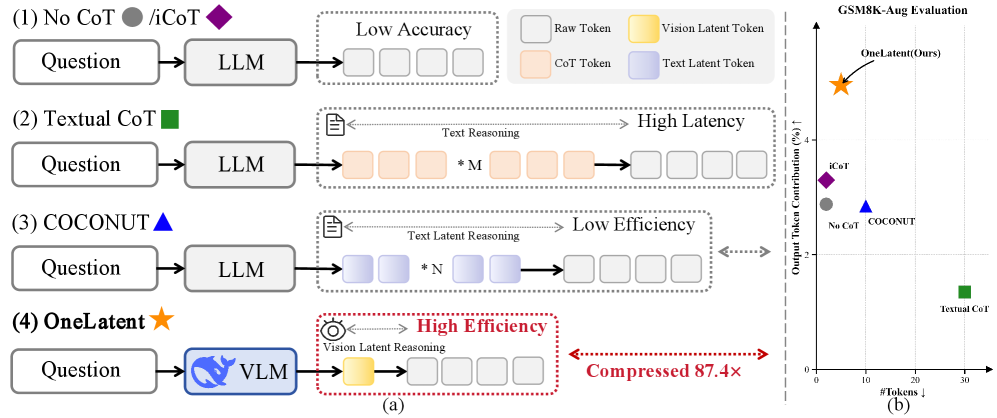
本文提出了一种名为OneLatent的框架,旨在压缩中间推理过程为一个单独的潜在token,从而降低Chain-of-Thought (CoT) 推理的计算成本。OneLatent通过渲染CoT图像和DeepSeek-OCR的隐藏状态进行监督学习,将文本步骤转化为图像,获得可检查和审计的确定性监督信号,无需模型输出冗长的文本解释。实验结果表明,OneLatent在多个基准测试中,平均输出长度减少了11倍,而准确率仅下降了2.21%,同时输出token贡献度(OTC)提高了6.8倍。在长链逻辑推理任务中,OneLatent使用单个潜在token在ProntoQA上达到了99.80%的准确率,在ProsQA上达到了97.80%的准确率,压缩率高达87.4倍,支持压缩约束下的泛化。
🔬 方法详解
问题定义:现有Chain-of-Thought (CoT) 推理方法虽然能够提升模型在复杂任务上的表现,但由于需要生成大量的中间推理步骤,导致推理成本显著增加,限制了其在资源受限场景下的应用。现有方法的痛点在于推理过程冗长,计算复杂度高,难以进行高效部署。
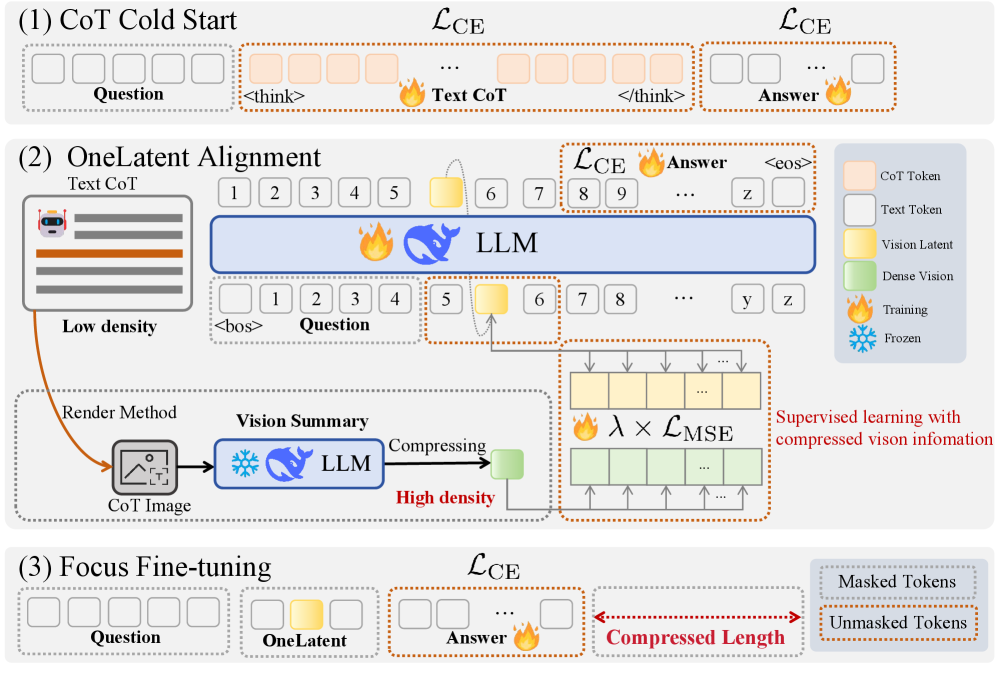
核心思路:OneLatent的核心思路是将CoT推理过程中的多个中间步骤压缩成一个单独的潜在token。通过这种方式,模型只需要处理和生成一个token,从而显著降低推理成本。为了保证压缩后的潜在token能够有效编码推理信息,论文利用视觉渲染和OCR隐藏状态作为监督信号。
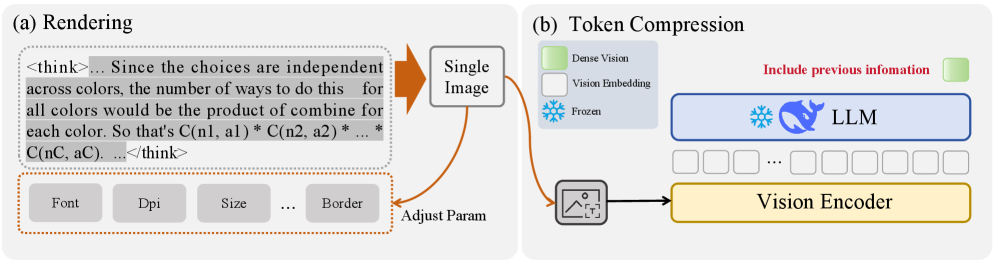
技术框架:OneLatent框架主要包含以下几个阶段:1) 使用CoT生成中间推理步骤;2) 将文本形式的推理步骤渲染成图像;3) 使用DeepSeek-OCR提取图像的隐藏状态;4) 训练模型将输入问题和OCR隐藏状态编码成一个潜在token;5) 使用该潜在token进行最终答案的预测。整个框架通过视觉渲染和OCR技术,将文本推理过程转化为视觉信息,从而实现更有效的压缩和监督。
关键创新:OneLatent最重要的技术创新点在于使用视觉渲染和OCR隐藏状态作为监督信号,将文本推理过程转化为视觉信息。这种方法避免了直接对文本进行压缩可能带来的信息损失,同时利用了视觉信息的丰富性和可解释性。与传统的文本压缩方法相比,OneLatent能够更好地保留推理过程中的关键信息,从而保证压缩后的模型仍然具有较高的推理能力。
关键设计:OneLatent的关键设计包括:1) 使用高质量的文本渲染引擎将文本推理步骤转化为清晰的图像;2) 利用DeepSeek-OCR提取图像的隐藏状态,作为监督信号;3) 设计合适的损失函数,鼓励模型将输入问题和OCR隐藏状态编码成一个信息丰富的潜在token;4) 探索不同的模型架构,以实现最佳的压缩和推理性能。具体的参数设置和网络结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
OneLatent在多个基准测试中表现出色。相较于传统的文本CoT方法,OneLatent平均输出长度减少了11倍,而准确率仅下降了2.21%,同时输出token贡献度(OTC)提高了6.8倍。在长链逻辑推理任务中,OneLatent使用单个潜在token在ProntoQA上达到了99.80%的准确率,在ProsQA上达到了97.80%的准确率,压缩率高达87.4倍。
🎯 应用场景
OneLatent具有广泛的应用前景,尤其适用于资源受限的场景,例如移动设备、嵌入式系统和边缘计算。它可以应用于各种需要复杂推理的任务,如问答系统、逻辑推理和决策支持。通过降低推理成本,OneLatent有望推动CoT推理在实际应用中的普及,并为开发更高效、更智能的AI系统提供新的思路。
📄 摘要(原文)
Chain-of-thought (CoT) prompting improves reasoning but often increases inference cost by one to two orders of magnitude. To address these challenges, we present \textbf{OneLatent}, a framework that compresses intermediate reasoning into a single latent token via supervision from rendered CoT images and DeepSeek-OCR hidden states. By rendering textual steps into images, we obtain a deterministic supervision signal that can be inspected and audited without requiring the model to output verbose textual rationales. Across benchmarks, OneLatent reduces average output length by $11\times$ with only a $2.21\%$ average accuracy drop relative to textual CoT, while improving output token contribution (OTC) by $6.8\times$. On long-chain logical reasoning, OneLatent reaches $99.80\%$ on ProntoQA and $97.80\%$ on ProsQA with one latent token, with compression up to $87.4\times$, supporting compression-constrained generalization.