PhGPO: Pheromone-Guided Policy Optimization for Long-Horizon Tool Planning
作者: Yu Li, Guangfeng Cai, Shengtian Yang, Han Luo, Shuo Han, Xu He, Dong Li, Lei Feng
分类: cs.AI
发布日期: 2026-02-14
💡 一句话要点
提出PhGPO,利用信息素引导策略优化,解决长时程工具规划问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具规划 策略优化 强化学习 信息素 长时程任务
📋 核心要点
- 长时程工具规划因组合爆炸导致探索空间巨大,难以有效学习。
- PhGPO借鉴蚁群优化思想,学习历史成功轨迹中的工具转移模式(信息素)以指导策略优化。
- 实验结果表明,PhGPO能够有效提升长时程工具规划的性能。
📝 摘要(中文)
大型语言模型(LLM)Agent在通过工具使用执行复杂任务方面表现出强大的能力。然而,长时程多步骤工具规划面临挑战,因为探索空间存在组合爆炸。在这种情况下,即使找到正确的工具使用路径,通常也只被认为是当前训练的即时奖励,而不会为后续训练提供任何可重用的信息。本文提出信息素引导策略优化(PhGPO),它从历史轨迹中学习基于轨迹的转移模式(即信息素),然后使用学习到的信息素来指导策略优化。这种学习到的信息素提供了明确且可重用的指导,引导策略优化朝着历史上成功的工具转移方向发展,从而改进长时程工具规划。综合实验结果证明了所提出的PhGPO的有效性。
🔬 方法详解
问题定义:论文旨在解决长时程多步骤工具规划问题。现有方法在面对组合爆炸的探索空间时,难以有效学习和利用历史经验。即使找到成功的工具使用路径,也往往只作为当前训练的即时奖励,缺乏对后续训练的可重用性。这导致训练效率低下,难以泛化到更复杂的任务中。
核心思路:论文的核心思路是借鉴蚁群优化算法中的信息素概念,将历史成功的工具转移路径编码为一种可重用的“信息素”。这种信息素可以显式地指导策略优化,使其朝着历史上成功的工具转移方向发展,从而提高学习效率和泛化能力。
技术框架:PhGPO的整体框架包含以下几个主要模块:1) 历史轨迹存储模块,用于存储历史训练过程中产生的成功轨迹;2) 信息素学习模块,从历史轨迹中提取工具转移模式,并将其编码为信息素;3) 策略优化模块,利用学习到的信息素作为指导信号,优化策略网络,使其更有可能选择历史上成功的工具转移;4) 环境交互模块,策略网络与环境交互,执行工具规划任务,并收集新的训练数据。
关键创新:PhGPO的关键创新在于引入了信息素的概念来指导策略优化。与传统的强化学习方法相比,PhGPO能够显式地利用历史经验,避免了从零开始探索,从而提高了学习效率和泛化能力。此外,PhGPO的信息素是基于轨迹的,能够捕捉到更复杂的工具转移模式,而不仅仅是单个工具的选择。
关键设计:论文中信息素的具体表示形式未知,但可以推测其可能是一个工具转移概率矩阵,表示从一个工具转移到另一个工具的概率。策略优化模块可能使用强化学习算法,如PPO或TRPO,并结合信息素作为额外的奖励或指导信号。损失函数的设计需要考虑信息素的引导作用,例如,可以设计一个损失函数,鼓励策略网络选择具有较高信息素值的工具转移。
🖼️ 关键图片
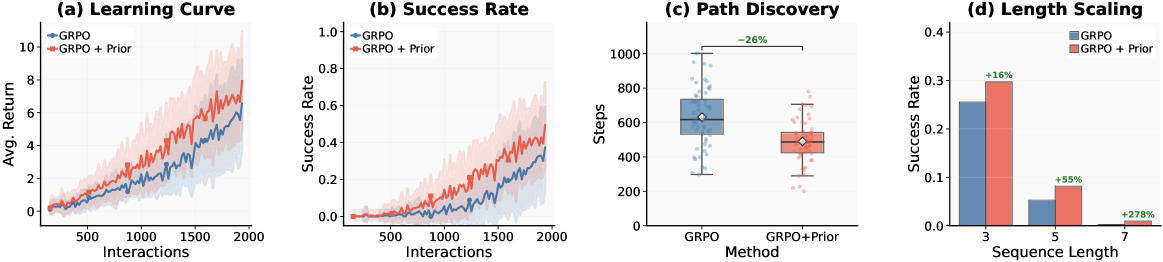
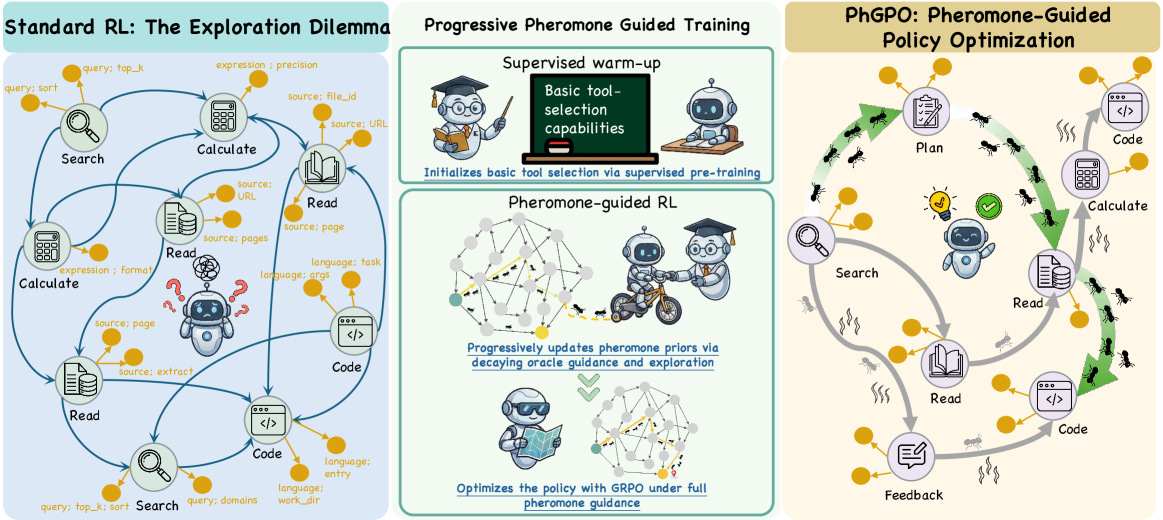
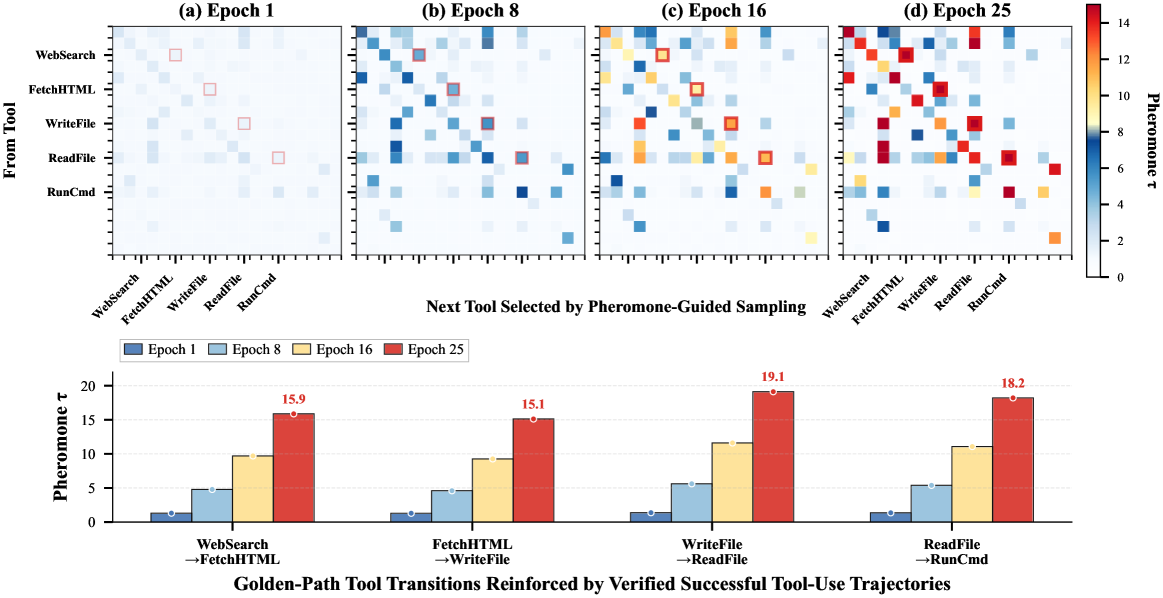
📊 实验亮点
论文通过综合实验验证了PhGPO的有效性,但具体的性能数据、对比基线和提升幅度未知。可以推测,PhGPO在长时程工具规划任务上,相比于传统的强化学习方法,能够显著提高任务完成率和学习效率。
🎯 应用场景
PhGPO具有广泛的应用前景,例如智能家居控制、机器人流程自动化、软件开发辅助等。它可以帮助Agent自动规划和执行复杂的任务,提高工作效率和智能化水平。未来,PhGPO可以进一步扩展到更复杂的环境和任务中,例如多Agent协作、人机协作等。
📄 摘要(原文)
Recent advancements in Large Language Model (LLM) agents have demonstrated strong capabilities in executing complex tasks through tool use. However, long-horizon multi-step tool planning is challenging, because the exploration space suffers from a combinatorial explosion. In this scenario, even when a correct tool-use path is found, it is usually considered an immediate reward for current training, which would not provide any reusable information for subsequent training. In this paper, we argue that historically successful trajectories contain reusable tool-transition patterns, which can be leveraged throughout the whole training process. Inspired by ant colony optimization where historically successful paths can be reflected by the pheromone, we propose Pheromone-Guided Policy Optimization (PhGPO), which learns a trajectory-based transition pattern (i.e., pheromone) from historical trajectories and then uses the learned pheromone to guide policy optimization. This learned pheromone provides explicit and reusable guidance that steers policy optimization toward historically successful tool transitions, thereby improving long-horizon tool planning. Comprehensive experimental results demonstrate the effectiveness of our proposed PhGPO.