AuTAgent: A Reinforcement Learning Framework for Tool-Augmented Audio Reasoning
作者: Siqian Tong, Xuan Li, Yiwei Wang, Baolong Bi, Yujun Cai, Shenghua Liu, Yuchen He, Chengpeng Hao
分类: cs.SD, cs.AI
发布日期: 2026-02-14
💡 一句话要点
AuTAgent:强化学习驱动的工具增强音频推理框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 音频语言模型 强化学习 工具增强 音频推理 外部知识 差分奖励 上下文学习
📋 核心要点
- 大型音频语言模型在复杂音频推理中面临挑战,尤其是在需要精确声学测量时,现有方法难以有效利用外部工具。
- AuTAgent通过强化学习框架,学习何时以及调用哪些外部工具,避免信息过载,提升模型推理能力。
- 实验结果表明,AuTAgent显著提升了音频推理的准确率,在MMAU和MMAR基准测试中分别提升了4.20%/6.20%和9.80%/8.00%。
📝 摘要(中文)
大型音频语言模型(LALMs)在感知方面表现出色,但在需要精确声学测量的复杂推理方面存在困难。外部工具可以提取精确的特征,如准确的节奏或音高,但有效集成仍然具有挑战性:简单地使用所有工具会导致信息过载,而基于提示的选择无法评估上下文相关的效用。为了解决这个问题,我们提出了AuTAgent(音频工具代理),一个强化学习框架,用于学习何时以及调用哪些工具。通过采用具有新颖差分奖励机制的稀疏反馈训练策略,该代理学会过滤掉不相关的工具,并且仅当外部辅助能够产生超过基础模型的净性能增益时才调用它。实验结果证实,AuTAgent通过提供可验证的声学证据来弥补LALM的表示瓶颈。在MMAU Test-mini和MMAR基准测试中,开源和闭源骨干网络的准确率分别提高了4.20%/6.20%和9.80%/8.00%。此外,进一步的实验证明了卓越的可迁移性。我们强调了外部工具在增强音频模型推理中的互补作用。
🔬 方法详解
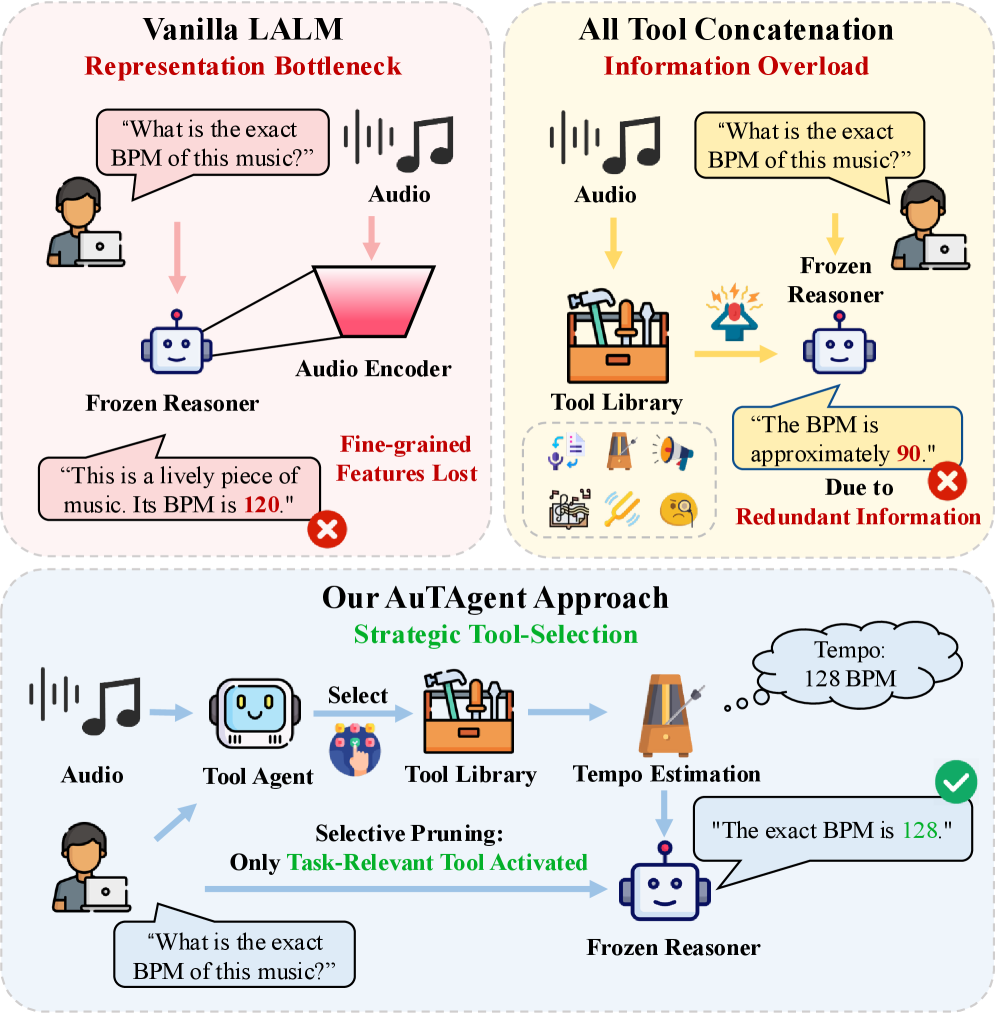
问题定义:大型音频语言模型(LALMs)虽然在音频感知方面表现出色,但在需要精确声学测量的复杂推理任务中表现不佳。现有的方法,如简单地使用所有工具或基于提示的选择,存在信息过载或无法有效评估上下文相关效用的问题,导致推理性能受限。
核心思路:AuTAgent的核心思路是利用强化学习训练一个代理,使其能够根据当前音频上下文,智能地选择合适的外部工具进行辅助推理。通过学习何时以及调用哪些工具,AuTAgent旨在弥补LALMs的表示瓶颈,并提供可验证的声学证据,从而提高推理准确性。
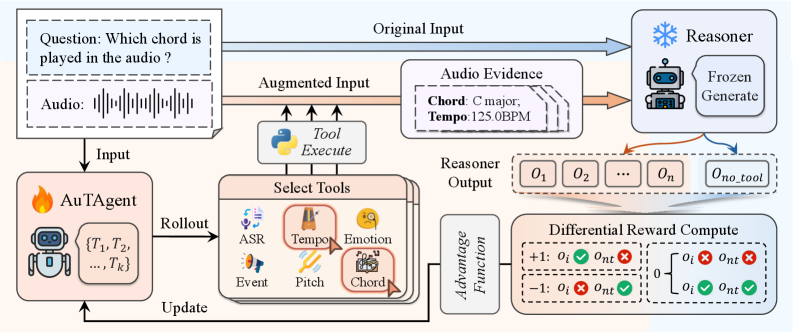
技术框架:AuTAgent框架包含以下主要模块:1) 音频语言模型(LALM):作为基础模型,负责音频特征提取和初步推理;2) 外部工具集:提供各种声学特征提取工具,如音高、节奏等;3) 强化学习代理:负责根据LALM的输出和当前音频上下文,决定是否调用外部工具以及调用哪个工具;4) 奖励函数:用于评估代理的行为,并指导其学习。整体流程是,LALM首先对音频进行初步推理,然后代理根据LALM的输出和音频上下文,决定是否调用外部工具。如果调用,则将工具的输出与LALM的输出结合,进行最终推理。
关键创新:AuTAgent的关键创新在于使用强化学习来动态选择外部工具。与现有方法相比,AuTAgent能够根据上下文自适应地选择工具,避免了信息过载,并提高了工具的利用效率。此外,论文还提出了一个新颖的差分奖励机制,鼓励代理仅在调用工具能够带来性能提升时才调用工具。
关键设计:AuTAgent使用稀疏反馈训练策略,只在最终推理结果正确或错误时才提供奖励。差分奖励机制的设计是关键,它计算了使用工具后的性能提升,并以此作为奖励信号。代理的网络结构采用标准的强化学习结构,如Actor-Critic网络。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AuTAgent在MMAU Test-mini和MMAR基准测试中,分别提升了开源和闭源骨干网络的准确率4.20%/6.20%和9.80%/8.00%。这证明了AuTAgent能够有效利用外部工具,弥补LALM的表示瓶颈。此外,实验还验证了AuTAgent的卓越可迁移性,表明其具有广泛的应用潜力。
🎯 应用场景
AuTAgent框架可应用于各种音频理解和推理任务,例如音乐分析、语音识别、环境声音分类等。通过智能地利用外部工具,AuTAgent可以提高音频模型的准确性和可靠性,为音频智能应用提供更强大的支持。该研究的未来影响在于推动音频语言模型与外部知识的有效融合,实现更智能、更精准的音频处理。
📄 摘要(原文)
Large Audio Language Models (LALMs) excel at perception but struggle with complex reasoning requiring precise acoustic measurements. While external tools can extract fine-grained features like exact tempo or pitch, effective integration remains challenging: naively using all tools causes information overload, while prompt-based selection fails to assess context-dependent utility. To address this, we propose AuTAgent (Audio Tool Agent), a reinforcement learning framework that learns when and which tools to invoke. By employing a sparse-feedback training strategy with a novel Differential Reward mechanism, the agent learns to filter out irrelevant tools and invokes external assistance only when it yields a net performance gain over the base model. Experimental results confirm that AuTAgent complements the representation bottleneck of LALMs by providing verifiable acoustic evidence. It improves accuracy by 4.20% / 6.20% and 9.80% / 8.00% for open-source and closed-source backbones on the MMAU Test-mini and the MMAR benchmarks, respectively. In addition, further experiments demonstrate exceptional transferability. We highlight the complementary role of external tools in augmenting audio model reasoning.