AllMem: A Memory-centric Recipe for Efficient Long-context Modeling
作者: Ziming Wang, Xiang Wang, Kailong Peng, Lang Qin, Juan Gabriel Kostelec, Christos Sourmpis, Axel Laborieux, Qinghai Guo
分类: cs.AI, cs.CL
发布日期: 2026-02-14
💡 一句话要点
AllMem:一种以内存为中心的方案,用于高效的长文本建模。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 滑动窗口注意力 记忆网络 高效计算 大型语言模型
📋 核心要点
- 长文本建模面临自注意力机制带来的计算和内存瓶颈,限制了LLM在长序列任务中的应用。
- AllMem结合滑动窗口注意力和非线性记忆网络,在降低计算成本的同时,有效处理超长上下文。
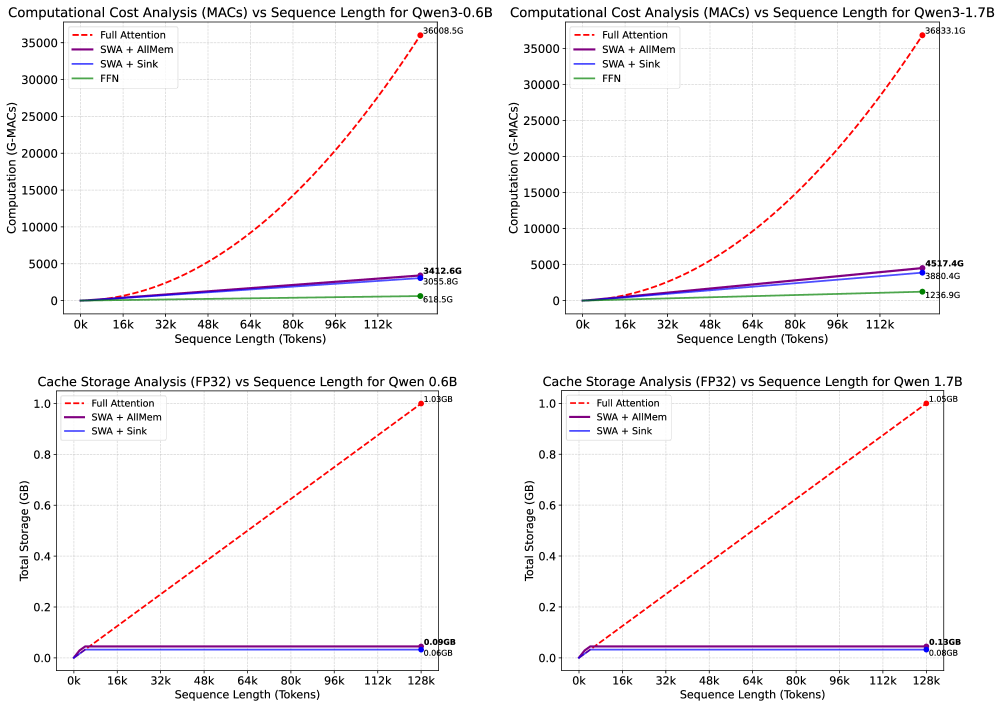
- 实验表明,AllMem在长文本基准测试中表现出色,甚至超越了全局注意力,同时显著降低了资源消耗。
📝 摘要(中文)
大型语言模型(LLMs)在长序列任务中面临显著的性能瓶颈,这主要是由于自注意力机制固有的计算复杂性和内存开销。为了解决这些挑战,我们提出了一种新颖而高效的混合架构 extsc{AllMem},它集成了滑动窗口注意力(SWA)与非线性测试时训练(TTT)记忆网络。 extsc{AllMem}使模型能够有效地扩展到超长上下文,同时减轻灾难性遗忘。这种方法不仅克服了线性记忆模型典型的表示约束,而且显著降低了长序列推理期间的计算和内存占用。此外,我们实施了一种内存高效的微调策略,用内存增强的滑动窗口层替换预训练模型中的标准注意力层。该框架有助于将任何现成的预训练LLM高效地转换为基于 extsc{AllMem}的架构。经验评估证实,我们的4k窗口模型在37k LongBench上实现了接近无损的性能,与完全注意力相比,仅有0.83的轻微下降。此外,在128k上下文的InfiniteBench上,我们的8k窗口变体优于完全注意力,这验证了我们的参数化内存在减轻噪声和保持鲁棒的长程建模方面的有效性,而无需全局注意力的高昂成本。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理长序列时,由于自注意力机制的计算复杂度和内存占用过高而导致的性能瓶颈问题。现有方法,如全局注意力,计算成本高昂;而线性记忆模型则存在表示能力不足的局限性。
核心思路:论文的核心思路是结合滑动窗口注意力(SWA)和非线性测试时训练(TTT)记忆网络,构建一种混合架构AllMem。SWA降低了计算复杂度,而TTT记忆网络则增强了模型的表示能力,从而在长序列建模中实现效率和性能的平衡。
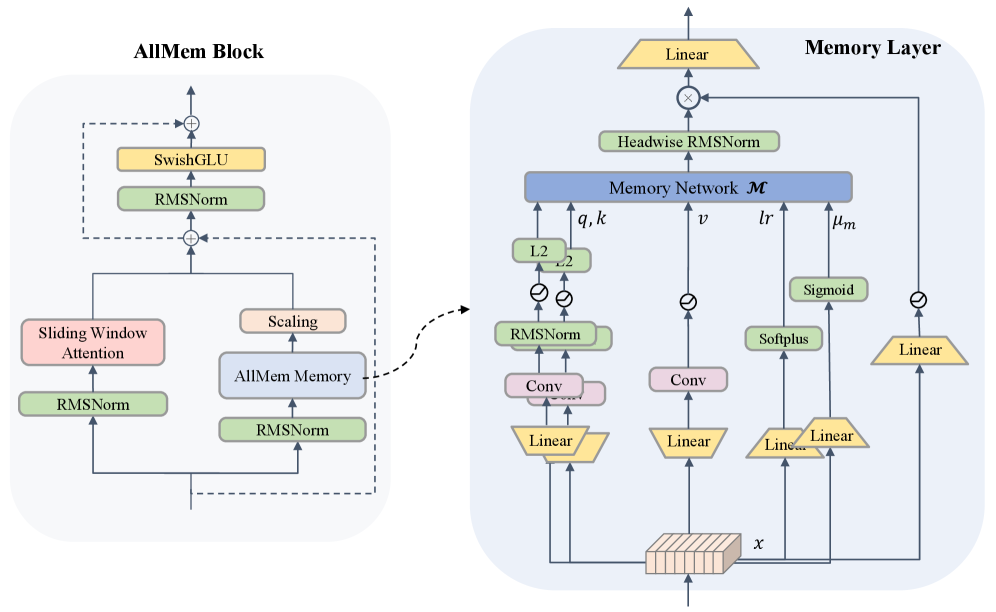
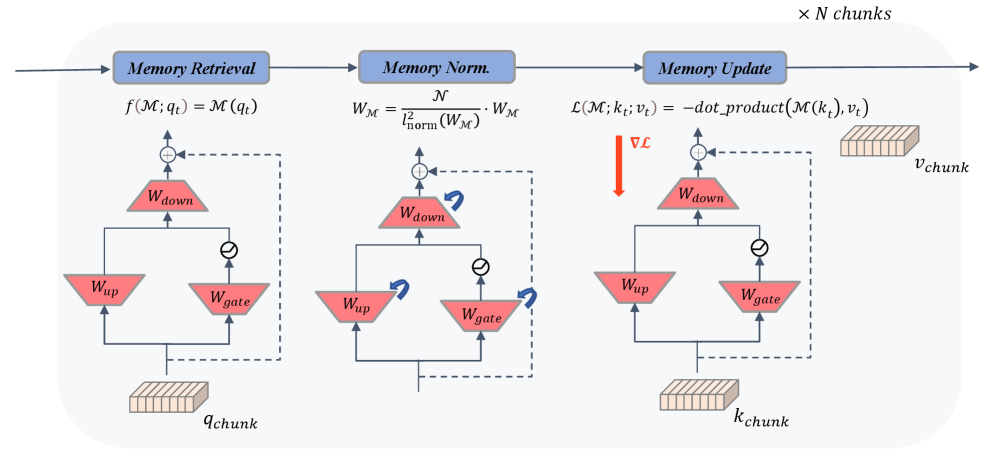
技术框架:AllMem架构包含以下主要模块:1) 滑动窗口注意力层:用于局部上下文建模,降低计算复杂度。2) 非线性记忆网络:用于存储和检索全局信息,增强模型对长程依赖的建模能力。3) 内存高效微调策略:将预训练模型的标准注意力层替换为内存增强的滑动窗口层,实现高效的模型迁移。整体流程是:首先使用SWA处理局部信息,然后利用TTT记忆网络存储和检索全局信息,最后通过微调策略将模型应用于特定任务。
关键创新:AllMem的关键创新在于将滑动窗口注意力和非线性记忆网络相结合,克服了各自的局限性。与传统的线性记忆模型相比,非线性记忆网络具有更强的表示能力,能够更好地捕捉长程依赖关系。此外,内存高效微调策略使得AllMem能够方便地应用于各种预训练模型。
关键设计:论文的关键设计包括:1) 滑动窗口大小的选择:需要根据任务的上下文长度和计算资源进行权衡。2) 非线性记忆网络的结构:论文采用了具体的非线性函数(具体形式未知)来增强记忆网络的表示能力。3) 内存高效微调策略的实现细节:如何有效地将预训练模型的注意力层替换为内存增强的滑动窗口层,并保持模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AllMem在LongBench和InfiniteBench等长文本基准测试中表现出色。在37k LongBench上,4k窗口模型实现了接近无损的性能,与全局注意力相比,仅有0.83的轻微下降。在128k上下文的InfiniteBench上,8k窗口变体甚至优于全局注意力,验证了AllMem在长文本建模方面的有效性。
🎯 应用场景
AllMem适用于需要处理长文本序列的各种应用场景,例如:长文档摘要、问答系统、机器翻译、代码生成等。该研究成果有助于降低长文本建模的计算成本和内存需求,使得LLM能够更好地应用于资源受限的环境,并提升长文本处理的效率和质量。未来,AllMem有望推动LLM在更多实际场景中的应用。
📄 摘要(原文)
Large Language Models (LLMs) encounter significant performance bottlenecks in long-sequence tasks due to the computational complexity and memory overhead inherent in the self-attention mechanism. To address these challenges, we introduce \textsc{AllMem}, a novel and efficient hybrid architecture that integrates Sliding Window Attention (SWA) with non-linear Test-Time Training (TTT) memory networks. \textsc{AllMem} enables models to effectively scale to ultra-long contexts while mitigating catastrophic forgetting. This approach not only overcomes the representation constraints typical of linear memory models but also significantly reduces the computational and memory footprint during long-sequence inference. Furthermore, we implement a Memory-Efficient Fine-Tuning strategy to replace standard attention layers in pre-trained models with memory-augmented sliding window layers. This framework facilitates the efficient transformation of any off-the-shelf pre-trained LLM into an \textsc{AllMem}-based architecture. Empirical evaluations confirm that our 4k window model achieves near-lossless performance on 37k LongBench with a marginal 0.83 drop compared to full attention. Furthermore, on InfiniteBench at a 128k context, our 8k window variant outperforms full attention, which validates the effectiveness of our parameterized memory in mitigating noise and maintaining robust long-range modeling without the prohibitive costs of global attention.