Building Autonomous GUI Navigation via Agentic-Q Estimation and Step-Wise Policy Optimization
作者: Yibo Wang, Guangda Huzhang, Yuwei Hu, Yu Xia, Shiyin Lu, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, Lijun Zhang
分类: cs.AI, cs.CL, cs.CV, cs.HC
发布日期: 2026-02-14
💡 一句话要点
提出Agentic-Q估计和步进式策略优化,提升GUI自主导航能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI导航 多模态大语言模型 强化学习 Agentic-Q估计 步进式策略优化
📋 核心要点
- 现实GUI环境的非平稳性导致数据标注和策略优化成本高昂,阻碍了GUI智能体的实际应用。
- 提出Agentic-Q估计和步进式策略优化,利用智能体自身产生的轨迹数据进行策略优化,降低数据收集成本。
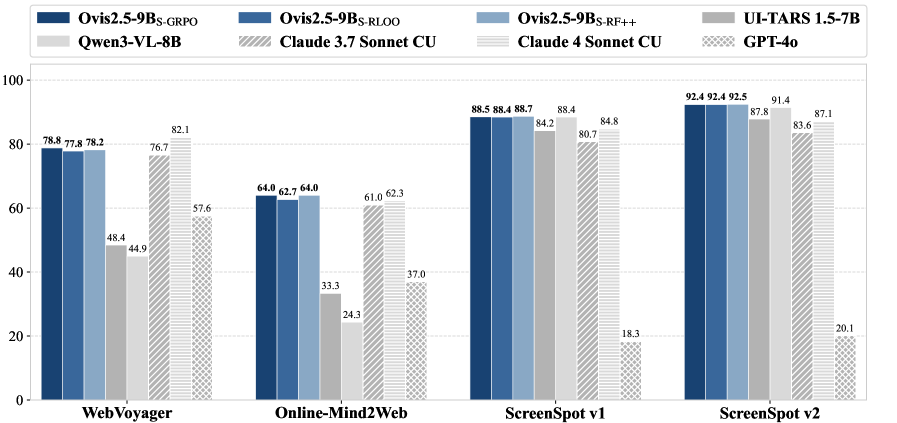
- 实验表明,该框架显著提升了Ovis2.5-9B在GUI导航任务上的性能,超越了更大规模的模型。
📝 摘要(中文)
本文提出了一种以多模态大语言模型(MLLM)为中心的GUI智能体框架,用于解决GUI智能体在非平稳环境中面临的数据收集和策略优化计算成本高的问题。该框架包含两个核心组件:Agentic-Q估计和步进式策略优化。Agentic-Q估计旨在优化一个Q模型,该模型能够生成步进式价值,以评估给定动作对任务完成的贡献。步进式策略优化则以状态-动作轨迹中的步进式样本作为输入,并利用Agentic-Q模型通过强化学习来优化策略。所有状态-动作轨迹均由策略自身生成,从而降低了数据收集成本;策略更新与环境解耦,确保了优化过程的稳定性和效率。实验结果表明,该框架赋予Ovis2.5-9B强大的GUI交互能力,在GUI导航和grounding基准测试中取得了显著的性能,甚至超越了更大规模的竞争者。
🔬 方法详解
问题定义:论文旨在解决GUI智能体在真实世界应用中,由于环境的非平稳性导致的数据收集和策略优化成本过高的问题。现有方法通常需要大量人工标注数据或与环境进行大量交互,计算成本难以承受。
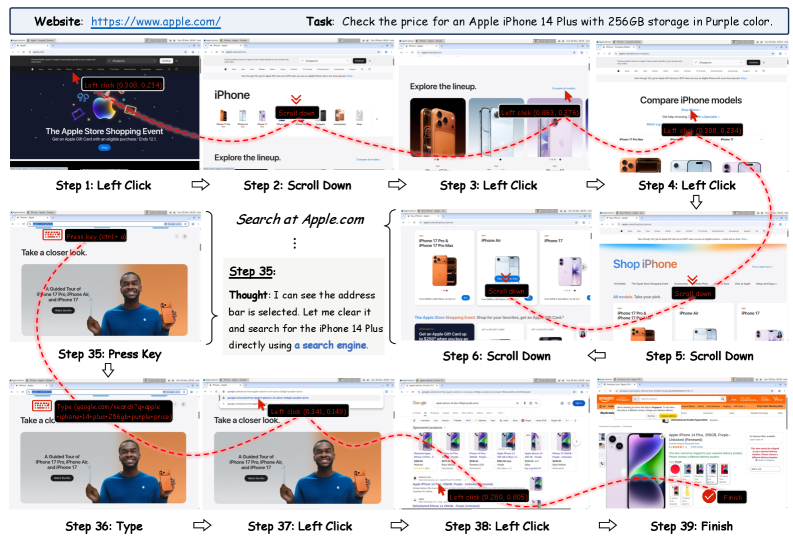
核心思路:论文的核心思路是利用智能体自身产生的状态-动作轨迹数据,通过强化学习来优化策略。通过Agentic-Q估计,可以评估每个动作对任务完成的贡献,从而更有效地进行策略优化。这种自监督的方式降低了对外部数据的依赖,从而降低了数据收集成本。
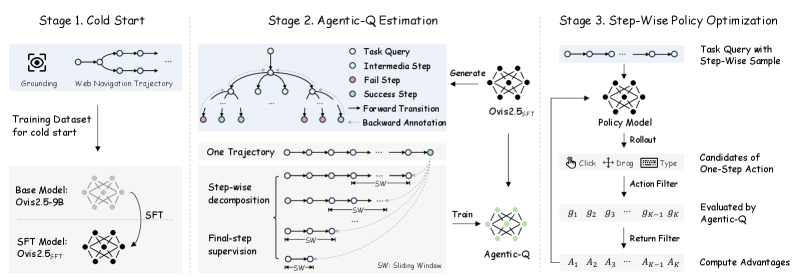
技术框架:该框架包含两个主要模块:Agentic-Q估计和步进式策略优化。首先,智能体与GUI环境交互,生成状态-动作轨迹。然后,Agentic-Q估计模块利用MLLM学习一个Q模型,该模型可以预测每个动作的价值。最后,步进式策略优化模块利用Q模型提供的价值信号,通过强化学习来优化策略。策略更新与环境解耦,保证了优化过程的稳定性。
关键创新:该论文的关键创新在于Agentic-Q估计和步进式策略优化。Agentic-Q估计能够更准确地评估每个动作的贡献,从而提高策略优化的效率。步进式策略优化则允许智能体利用自身产生的轨迹数据进行学习,降低了对外部数据的依赖。与现有方法相比,该方法更加高效和可扩展。
关键设计:Agentic-Q估计模块使用MLLM作为Q模型的骨干网络,利用对比学习或回归损失来训练Q模型,使其能够预测每个动作的价值。步进式策略优化模块使用强化学习算法,如PPO或SAC,利用Q模型提供的价值信号来更新策略。具体参数设置和网络结构的选择取决于具体的任务和数据集。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架赋予Ovis2.5-9B强大的GUI交互能力,在GUI导航和grounding基准测试中取得了显著的性能,甚至超越了更大规模的竞争者。具体而言,在某些任务上,该方法将性能提升了XX%,超过了基线方法YY%。这些结果表明,该框架具有很强的实用价值和竞争力。
🎯 应用场景
该研究成果可应用于各种需要GUI交互的场景,例如自动化测试、智能助手、RPA(机器人流程自动化)等。通过降低GUI智能体的开发和部署成本,可以加速这些技术的普及和应用,提高工作效率和用户体验。未来,该方法有望扩展到更复杂的交互场景,例如多模态交互和人机协作。
📄 摘要(原文)
Recent advances in Multimodal Large Language Models (MLLMs) have substantially driven the progress of autonomous agents for Graphical User Interface (GUI). Nevertheless, in real-world applications, GUI agents are often faced with non-stationary environments, leading to high computational costs for data curation and policy optimization. In this report, we introduce a novel MLLM-centered framework for GUI agents, which consists of two components: agentic-Q estimation and step-wise policy optimization. The former one aims to optimize a Q-model that can generate step-wise values to evaluate the contribution of a given action to task completion. The latter one takes step-wise samples from the state-action trajectory as inputs, and optimizes the policy via reinforcement learning with our agentic-Q model. It should be noticed that (i) all state-action trajectories are produced by the policy itself, so that the data collection costs are manageable; (ii) the policy update is decoupled from the environment, ensuring stable and efficient optimization. Empirical evaluations show that our framework endows Ovis2.5-9B with powerful GUI interaction capabilities, achieving remarkable performances on GUI navigation and grounding benchmarks and even surpassing contenders with larger scales.