Multi-Modal Sensing and Fusion in mmWave Beamforming for Connected Vehicles: A Transformer Based Framework
作者: Muhammad Baqer Mollah, Honggang Wang, Mohammad Ataul Karim, Hua Fang
分类: cs.NI, cs.AI, cs.ET, cs.LG
发布日期: 2026-02-14
备注: 13 Pages. arXiv admin note: text overlap with arXiv:2509.11112
期刊: IEEE Transactions on Vehicular Technology, 2026
💡 一句话要点
提出基于Transformer的多模态融合毫米波波束赋形框架,降低车联网环境下的波束训练开销。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 毫米波通信 波束赋形 多模态融合 Transformer 车联网 V2I V2V
📋 核心要点
- 车联网中毫米波通信面临高动态环境下的波束训练开销问题,传统方法依赖大量导频信号交换和穷举式波束测量。
- 论文提出一种多模态感知融合框架,利用Transformer学习不同模态间的依赖关系,预测最优波束,减少训练开销。
- 实验结果表明,该框架在真实场景下能显著提高波束预测准确率,降低延迟和搜索空间开销,并保持较低的功率损耗。
📝 摘要(中文)
本文提出了一种多模态感知和融合学习框架,旨在降低车联网中毫米波波束赋形带来的高昂波束训练开销。该框架首先通过特定模态编码器提取来自不同感知模态的代表性特征,然后利用多头跨模态注意力机制学习模态间的依赖性和相关性,并融合多模态特征以预测最优的top-k波束,从而主动建立最佳视距链路。在真实的V2I和V2V场景下,使用多模态和60GHz毫米波无线感知数据进行了综合实验,结果表明,该框架在预测top-15波束时,准确率高达96.72%,平均功率损耗约为0.77 dB,并且与标准方法相比,整体延迟和波束搜索空间开销分别降低了86.81%和76.56%。
🔬 方法详解
问题定义:在车联网环境中,毫米波通信需要通过波束赋形来克服路径损耗。然而,高动态的车辆环境使得传统的波束赋形方法需要大量的导频信号交换和穷举式的波束测量,导致高昂的波束训练开销,降低了通信的有效空口时间。因此,如何降低波束训练开销,快速准确地找到最佳波束是本文要解决的问题。
核心思路:本文的核心思路是利用多模态感知数据来辅助波束赋形。通过融合来自不同传感器(例如摄像头、激光雷达等)的信息,可以更全面地了解车辆周围的环境,从而预测最佳波束的方向。利用Transformer模型学习不同模态之间的相关性,可以有效地融合多模态信息,提高波束预测的准确性。
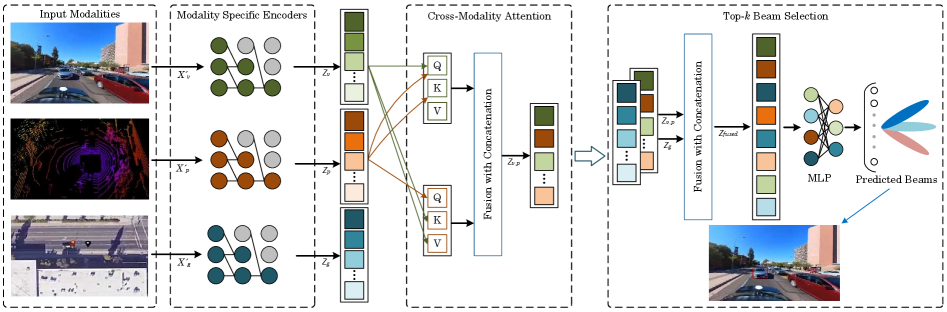
技术框架:该框架主要包含以下几个模块:1) 模态特定编码器:用于从不同的感知模态中提取特征。每个模态都有一个独立的编码器,例如,可以使用卷积神经网络(CNN)从图像数据中提取特征,使用循环神经网络(RNN)从时间序列数据中提取特征。2) 多头跨模态注意力机制:用于学习不同模态之间的依赖关系。该模块使用多头注意力机制来捕捉不同模态之间的长程依赖关系,并融合不同模态的特征。3) 波束预测器:用于预测最佳波束的方向。该模块使用融合后的多模态特征来预测最佳波束的方向。
关键创新:该论文的关键创新在于将多模态感知和Transformer模型应用于毫米波波束赋形。与传统的波束赋形方法相比,该方法不需要大量的导频信号交换和穷举式的波束测量,从而降低了波束训练开销。此外,利用Transformer模型学习不同模态之间的相关性,可以有效地融合多模态信息,提高波束预测的准确性。
关键设计:在模态特定编码器中,根据不同模态的数据特点选择合适的网络结构。例如,对于图像数据,可以使用预训练的CNN模型(如ResNet、VGG)作为编码器;对于时间序列数据,可以使用LSTM或GRU等RNN模型。在多头跨模态注意力机制中,需要设置合适的头数和注意力维度。在波束预测器中,可以使用全连接网络或卷积神经网络来预测最佳波束的方向。损失函数可以选择交叉熵损失或均方误差损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在预测top-15波束时,准确率高达96.72%,平均功率损耗约为0.77 dB,并且与标准方法相比,整体延迟和波束搜索空间开销分别降低了86.81%和76.56%。这些结果表明,该框架能够有效地降低波束训练开销,提高波束预测的准确性,并保持较低的功率损耗。
🎯 应用场景
该研究成果可广泛应用于车联网、自动驾驶等领域。通过降低波束训练开销,可以提高通信效率,降低延迟,从而提升车辆的安全性和智能化水平。此外,该方法还可以应用于其他需要快速准确地建立无线连接的场景,例如无人机通信、智能交通等。
📄 摘要(原文)
Millimeter wave (mmWave) communication, utilizing beamforming techniques to address the inherent path loss limitation, is considered as one of the key technologies to support ever increasing high throughput and low latency demands of connected vehicles. However, adopting standard defined beamforming approach in highly dynamic vehicular environments often incurs high beam training overheads and reduction in the available airtime for communications, which is mainly due to exchanging pilot signals and exhaustive beam measurements. To this end, we present a multi-modal sensing and fusion learning framework as a potential alternative solution to reduce such overheads. In this framework, we first extract the representative features from the sensing modalities by modality specific encoders, then, utilize multi-head cross-modal attention to learn dependencies and correlations between different modalities, and subsequently fuse the multimodal features to obtain predicted top-k beams so that the best line-of-sight links can be proactively established. To show the generalizability of the proposed framework, we perform a comprehensive experiment in four different vehicle-to-infrastructure (V2I) and vehicle-to-vehicle (V2V) scenarios from real world multimodal and 60 GHz mmWave wireless sensing data. The experiment reveals that the proposed framework (i) achieves up to 96.72% accuracy on predicting top-15 beams correctly, (ii) incurs roughly 0.77 dB average power loss, and (iii) improves the overall latency and beam searching space overheads by 86.81% and 76.56% respectively for top-15 beams compared to standard defined approach.