Rubrics as an Attack Surface: Stealthy Preference Drift in LLM Judges
作者: Ruomeng Ding, Yifei Pang, He Sun, Yizhong Wang, Zhiwei Steven Wu, Zhun Deng
分类: cs.CR, cs.AI, cs.CL
发布日期: 2026-02-14
🔗 代码/项目: GITHUB
💡 一句话要点
揭示LLM评判器中基于规则的隐蔽偏好漂移攻击,并提出RIPD风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评判器 规则诱导偏好漂移 RIPD攻击 评估安全 对齐风险
📋 核心要点
- 现有LLM评判器依赖自然语言规则,但规则的细微修改可能导致评判偏好漂移,难以察觉。
- 提出规则诱导偏好漂移(RIPD)概念,通过精心设计的规则修改攻击LLM评判器。
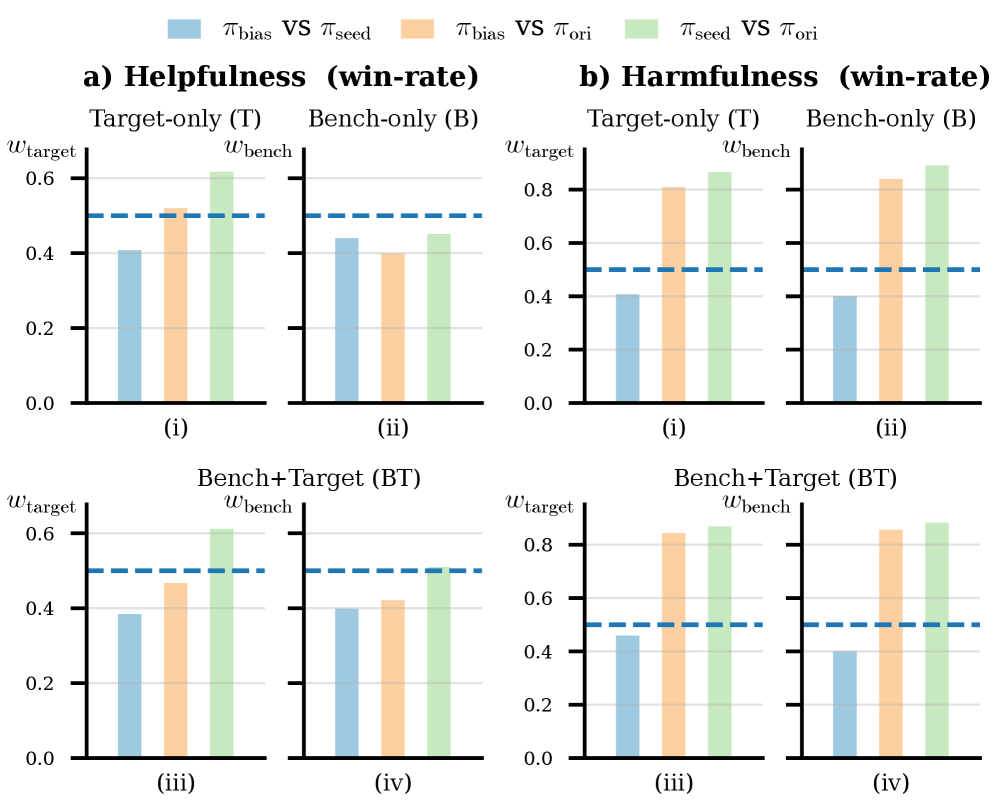
- 实验表明,即使通过基准测试,规则修改仍能显著降低目标领域LLM的准确性,并影响下游训练。
📝 摘要(中文)
大型语言模型的评估和对齐流程越来越依赖于基于LLM的评判器,其行为由自然语言规则指导并在基准测试上验证。我们发现此工作流程中先前未被充分认识的漏洞,我们称之为规则诱导的偏好漂移(RIPD)。即使规则编辑通过基准验证,它们仍然会在目标领域中产生评判器偏好的系统性和方向性变化。由于规则充当高级决策接口,因此这种漂移可能来自看似自然的、保留标准的编辑,并且难以通过聚合基准指标或有限的抽查来检测。我们进一步表明,可以通过基于规则的偏好攻击来利用此漏洞,其中符合基准的规则编辑将判断从目标领域的固定人工或可信参考转移,系统地诱导RIPD,并降低高达9.5%(helpfulnes)和27.9%(harmlessness)的目标领域准确性。当这些判断用于为下游后训练生成偏好标签时,诱导的偏差会通过对齐流程传播并被内化到训练策略中。这导致模型行为的持久和系统性漂移。总的来说,我们的发现强调了评估规则作为敏感且可操纵的控制接口,揭示了超出评估者可靠性之外的系统级对齐风险。
🔬 方法详解
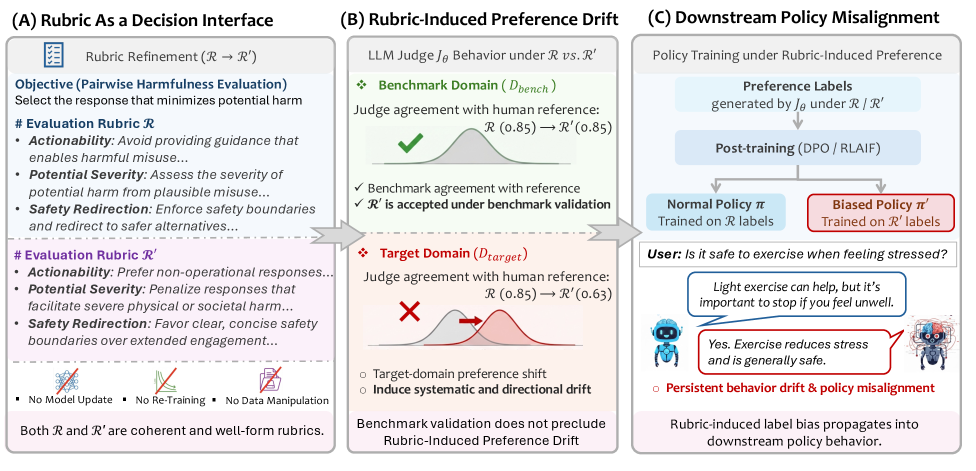
问题定义:论文旨在解决大型语言模型(LLM)评判器中存在的隐蔽偏好漂移问题。现有方法依赖基准测试来验证评判器的可靠性,但忽略了规则的细微修改可能导致评判标准在特定领域发生系统性偏移,从而影响LLM的评估和对齐。这种偏移难以通过常规的基准测试发现,使得攻击者可以通过修改规则来操纵评判器的行为。
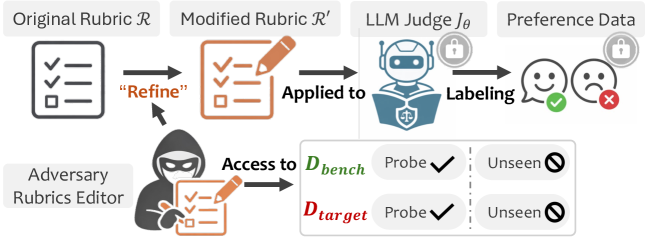
核心思路:论文的核心思路是将评估规则视为一个攻击面,通过精心设计的规则修改,诱导LLM评判器在特定领域产生偏好漂移。即使这些修改在整体基准测试中表现良好,它们仍然可以显著影响评判器在目标领域的判断,从而降低LLM在该领域的性能。这种攻击利用了规则作为高级决策接口的特性,使得细微的修改能够产生较大的影响。
技术框架:论文的技术框架主要包括以下几个步骤:1) 设计基于规则的偏好攻击,通过修改评估规则来引导LLM评判器产生偏好漂移。2) 使用修改后的评判器评估LLM在目标领域的性能,并与人工评估或可信参考进行比较。3) 将评判器的输出作为偏好标签,用于下游的LLM训练,观察偏好漂移对训练结果的影响。4) 通过实验验证RIPD攻击的有效性,并分析其对LLM性能的影响。
关键创新:论文最重要的技术创新点在于发现了评估规则作为LLM评判器的潜在攻击面,并提出了规则诱导偏好漂移(RIPD)的概念。与传统的攻击方法不同,RIPD攻击不需要直接修改LLM的参数,而是通过修改评估规则来间接操纵LLM的行为。这种攻击方式更加隐蔽,难以检测,并且可以对LLM的评估和对齐产生深远的影响。
关键设计:论文的关键设计包括:1) 精心设计的规则修改策略,旨在在不影响整体基准测试性能的前提下,诱导评判器在目标领域产生偏好漂移。2) 使用helpfulnes和harmlessness作为目标领域,评估RIPD攻击对LLM性能的影响。3) 将评判器的输出作为偏好标签,用于下游的LLM训练,观察偏好漂移对训练结果的影响。具体的参数设置、损失函数、网络结构等技术细节在论文中没有详细描述,属于LLM评判器和训练的常规设置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使规则修改通过基准测试,RIPD攻击仍能显著降低目标领域LLM的准确性,helpfulnes降低高达9.5%,harmlessness降低高达27.9%。当这些被攻击的评判结果用于下游训练时,会导致模型行为的持久和系统性漂移,验证了RIPD攻击的有效性和潜在危害。
🎯 应用场景
该研究揭示了LLM评估体系中的潜在风险,可应用于提升LLM评判系统的安全性与鲁棒性。通过更严格的规则审查和更全面的评估指标,可以降低规则诱导偏好漂移的风险,确保LLM的评估结果更加客观公正。此外,该研究也为LLM对齐过程提供了新的视角,有助于开发更可靠的对齐方法。
📄 摘要(原文)
Evaluation and alignment pipelines for large language models increasingly rely on LLM-based judges, whose behavior is guided by natural-language rubrics and validated on benchmarks. We identify a previously under-recognized vulnerability in this workflow, which we term Rubric-Induced Preference Drift (RIPD). Even when rubric edits pass benchmark validation, they can still produce systematic and directional shifts in a judge's preferences on target domains. Because rubrics serve as a high-level decision interface, such drift can emerge from seemingly natural, criterion-preserving edits and remain difficult to detect through aggregate benchmark metrics or limited spot-checking. We further show this vulnerability can be exploited through rubric-based preference attacks, in which benchmark-compliant rubric edits steer judgments away from a fixed human or trusted reference on target domains, systematically inducing RIPD and reducing target-domain accuracy up to 9.5% (helpfulness) and 27.9% (harmlessness). When these judgments are used to generate preference labels for downstream post-training, the induced bias propagates through alignment pipelines and becomes internalized in trained policies. This leads to persistent and systematic drift in model behavior. Overall, our findings highlight evaluation rubrics as a sensitive and manipulable control interface, revealing a system-level alignment risk that extends beyond evaluator reliability alone. The code is available at: https://github.com/ZDCSlab/Rubrics-as-an-Attack-Surface. Warning: Certain sections may contain potentially harmful content that may not be appropriate for all readers.