Who Do LLMs Trust? Human Experts Matter More Than Other LLMs
作者: Anooshka Bajaj, Zoran Tiganj
分类: cs.AI
发布日期: 2026-02-14
💡 一句话要点
LLM更信任谁?人类专家比其他LLM更重要
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会影响 可信度 专家信任 决策制定
📋 核心要点
- 现有LLM在社会环境中决策时,如何有效整合来自不同来源(如人类专家和其他LLM)的信息是一个挑战。
- 该研究的核心思想是探究LLM是否像人类一样,会根据信息来源的可信度来调整自身的判断和决策。
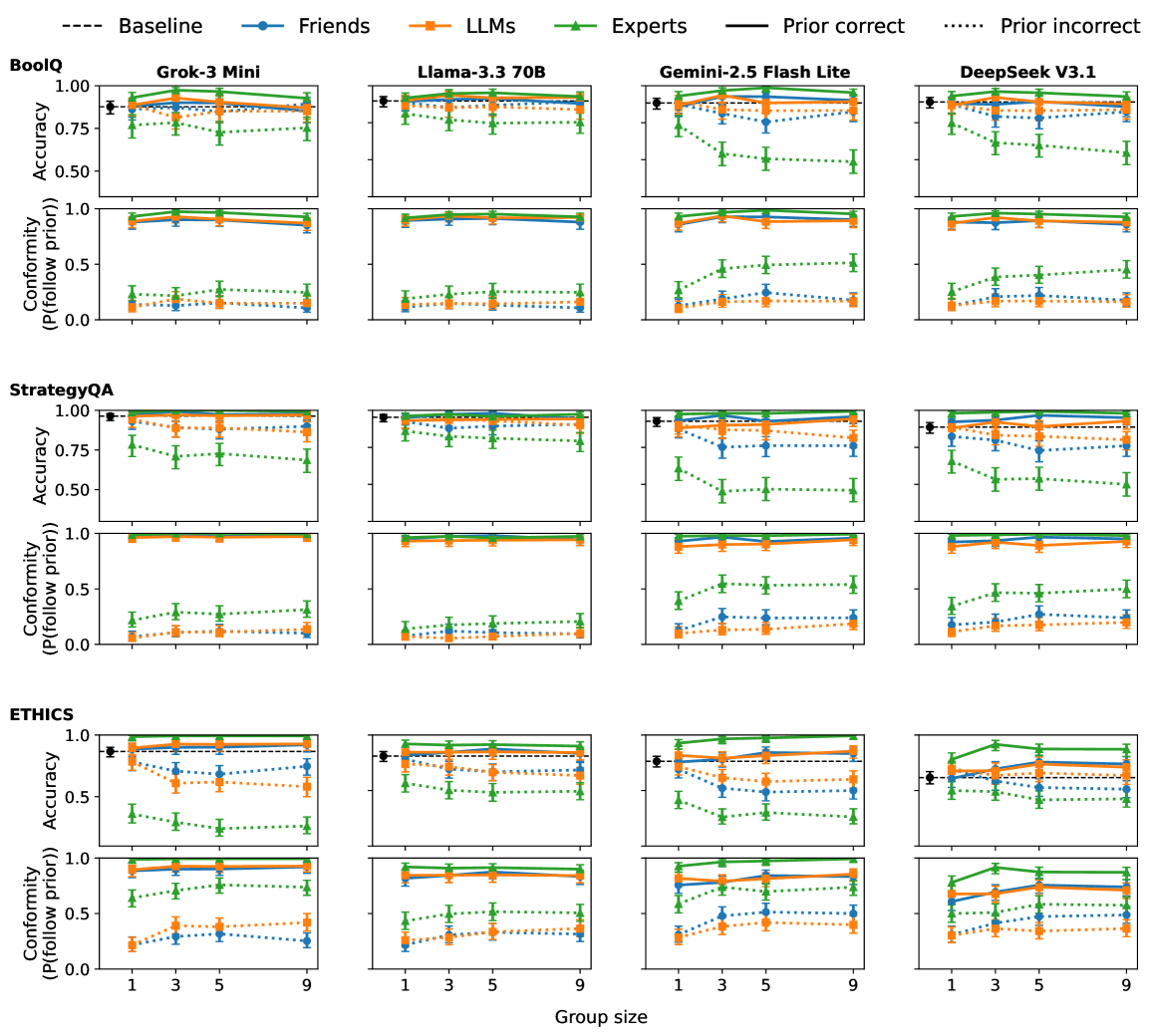
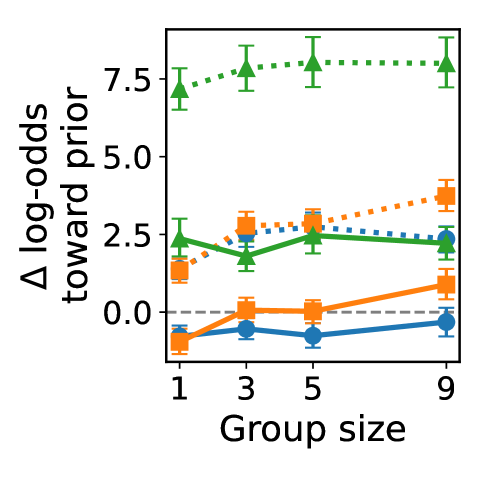
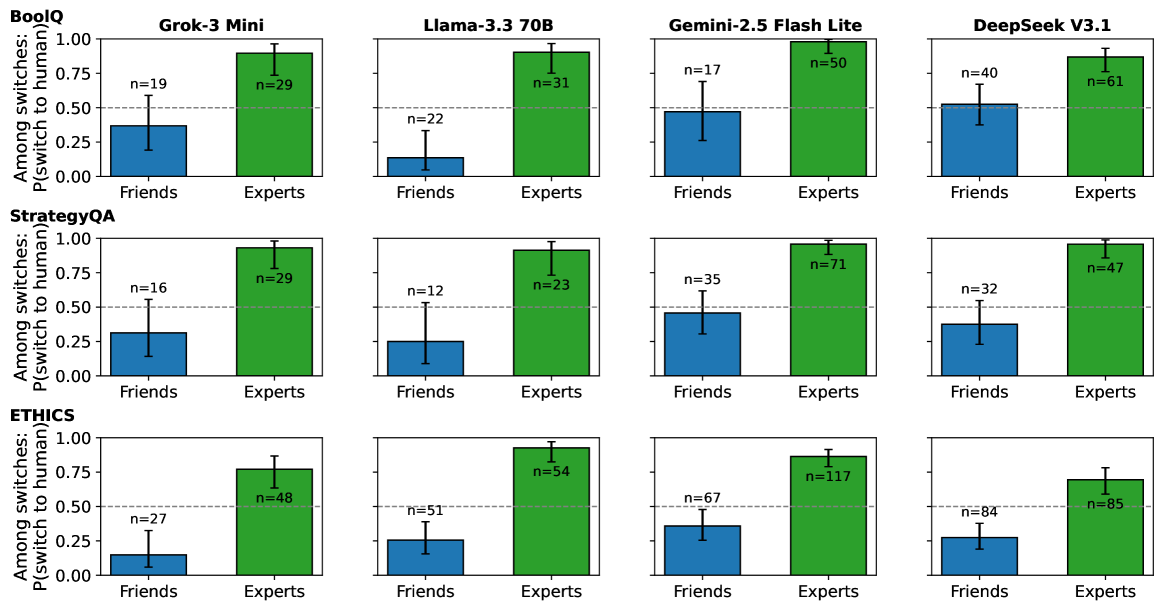
- 实验结果表明,LLM更倾向于信任并遵循来自人类专家的反馈,即使这些反馈是错误的,这揭示了LLM的一种社会影响模式。
📝 摘要(中文)
大型语言模型(LLM)越来越多地在需要接触社会信息的环境中运行,例如其他智能体的回答、工具的输出或人类的建议。在人类中,这些输入会以依赖于来源可信度和共识强度的方式影响判断。本文研究了LLM是否表现出类似的影响模式,以及它们是否优先考虑来自人类的反馈而不是来自其他LLM的反馈。在阅读理解、多步骤推理和道德判断这三个二元决策任务中,我们向四个指令调整的LLM展示了先前的响应,这些响应归因于朋友、人类专家或其他LLM。我们操纵群体的正确性并改变群体规模。在第二个实验中,我们引入了单个人类和单个LLM之间的直接分歧。在所有任务中,模型更显著地符合标记为来自人类专家的响应,包括当该信号不正确时,并且比其他LLM更愿意修改其答案以符合专家。这些结果表明,专家框架充当了当代LLM的强大先验,表明了一种在决策领域中普遍存在的、对可信度敏感的社会影响形式。
🔬 方法详解
问题定义:论文旨在研究LLM在面对来自不同来源(人类专家、其他LLM、朋友)的反馈时,如何调整自身的决策。现有方法缺乏对LLM社会影响偏好的深入理解,无法有效利用不同来源信息的价值。
核心思路:论文的核心思路是借鉴人类社会影响的研究,探究LLM是否也存在类似的可信度偏好,即更信任来自特定来源的信息。通过操纵信息来源的标签(专家、LLM、朋友)和正确性,观察LLM的决策变化。
技术框架:研究采用实验方法,设计了三个二元决策任务:阅读理解、多步骤推理和道德判断。在每个任务中,LLM首先独立做出决策,然后接收来自不同来源的反馈,最后再次做出决策。研究人员操纵了反馈来源(人类专家、其他LLM、朋友)、群体规模和正确性。第二个实验引入了人类专家和LLM之间的直接分歧。
关键创新:该研究的关键创新在于揭示了LLM对人类专家的信任偏好。与以往研究主要关注LLM的性能提升不同,该研究关注LLM的社会行为,探索了LLM如何整合和利用社会信息。
关键设计:研究使用了四个指令调整的LLM。实验中,对反馈来源进行了明确的标签,例如“来自人类专家的回答”。通过比较LLM在接收不同来源反馈后的决策变化,来评估不同来源的影响力。统计分析用于确定不同来源对LLM决策的显著影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM显著更倾向于遵循来自人类专家的反馈,即使该反馈是错误的。在所有任务中,LLM更愿意修改其答案以符合专家,而不是其他LLM。这表明专家框架对LLM具有强大的先验影响,揭示了一种对可信度敏感的社会影响形式。
🎯 应用场景
该研究成果可应用于提升LLM在复杂社会环境中的决策能力,例如在医疗诊断、法律咨询等领域,LLM可以更好地整合专家意见,做出更准确的判断。此外,该研究也为设计更安全、更可靠的LLM提供了新的思路,例如可以通过调整LLM的信任偏好,避免其受到恶意信息的误导。
📄 摘要(原文)
Large language models (LLMs) increasingly operate in environments where they encounter social information such as other agents' answers, tool outputs, or human recommendations. In humans, such inputs influence judgments in ways that depend on the source's credibility and the strength of consensus. This paper investigates whether LLMs exhibit analogous patterns of influence and whether they privilege feedback from humans over feedback from other LLMs. Across three binary decision-making tasks, reading comprehension, multi-step reasoning, and moral judgment, we present four instruction-tuned LLMs with prior responses attributed either to friends, to human experts, or to other LLMs. We manipulate whether the group is correct and vary the group size. In a second experiment, we introduce direct disagreement between a single human and a single LLM. Across tasks, models conform significantly more to responses labeled as coming from human experts, including when that signal is incorrect, and revise their answers toward experts more readily than toward other LLMs. These results reveal that expert framing acts as a strong prior for contemporary LLMs, suggesting a form of credibility-sensitive social influence that generalizes across decision domains.