OpAgent: Operator Agent for Web Navigation
作者: Yuyu Guo, Wenjie Yang, Siyuan Yang, Ziyang Liu, Cheng Chen, Yuan Wei, Yun Hu, Yang Huang, Guoliang Hao, Dongsheng Yuan, Jianming Wang, Xin Chen, Hang Yu, Lei Lei, Peng Di
分类: cs.AI
发布日期: 2026-02-14
💡 一句话要点
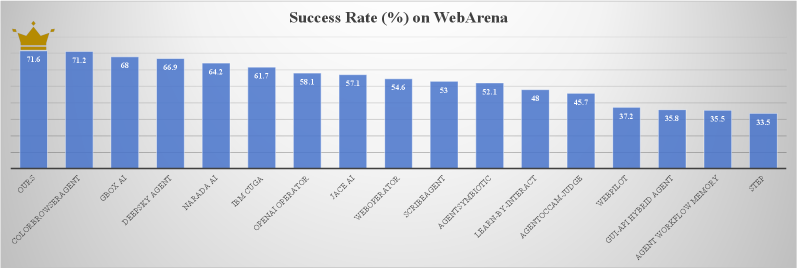
OpAgent:用于Web导航的在线增强学习操作代理,实现71.6%的SOTA成功率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web代理 在线强化学习 视觉-语言模型 模块化代理 Web导航
📋 核心要点
- 现有Web代理方法依赖静态数据集,无法适应Web环境的动态变化,导致严重的分布偏移问题。
- OpAgent通过在线强化学习与Web环境直接交互,利用混合奖励机制优化策略,解决信用分配难题。
- OpAgent采用模块化框架,包含规划、执行、反思和总结模块,实现错误恢复和自我纠正,显著提升性能。
📝 摘要(中文)
为了完成用户指令,自主Web代理必须应对真实世界网站固有的复杂性和易变性。传统范式主要依赖于监督微调(SFT)或使用静态数据集的离线强化学习(RL)。然而,这些方法存在严重的分布偏移,因为离线轨迹无法捕捉到不受约束的广泛Web环境的随机状态转换和实时反馈。本文提出了一种鲁棒的在线强化学习Web代理,旨在通过与不受约束的广泛网站的直接迭代交互来优化其策略。我们的方法包括三个核心创新:1)分层多任务微调:我们整理了一个全面的数据集混合,按功能原语(规划、行动和基础)进行分类,从而建立了一个具有强大的Web GUI任务指令遵循能力的视觉-语言模型(VLM)。2)野外在线代理RL:我们开发了一个在线交互环境,并使用专门的RL管道微调VLM。我们引入了一种混合奖励机制,该机制结合了用于整体结果评估的与真实情况无关的WebJudge和用于进度奖励的基于规则的决策树(RDT)。该系统有效地缓解了长时程导航中的信用分配挑战。值得注意的是,我们的RL增强模型在WebArena上实现了38.1%的成功率(pass@5),优于所有现有的单体基线。3)操作代理:我们引入了一个模块化的代理框架,即OpAgent,它协调规划器、基础器、反射器和摘要器。这种协同作用实现了强大的错误恢复和自我纠正,将代理的性能提升到71.6%的最新(SOTA)成功率。
🔬 方法详解
问题定义:现有Web代理主要依赖离线数据训练,无法适应真实Web环境的动态性和复杂性,导致泛化能力差,难以应对实际应用中的各种挑战。具体痛点在于,离线数据无法捕捉到Web环境的实时反馈和随机状态转移,使得模型在实际交互中表现不佳。
核心思路:OpAgent的核心思路是采用在线强化学习,让代理直接与真实Web环境进行交互,通过不断试错和学习来优化策略。这种方法能够更好地适应Web环境的动态变化,并利用实时反馈来提升性能。此外,OpAgent还引入了模块化的代理框架,通过规划、执行、反思和总结等模块的协同工作,实现更强大的错误恢复和自我纠正能力。
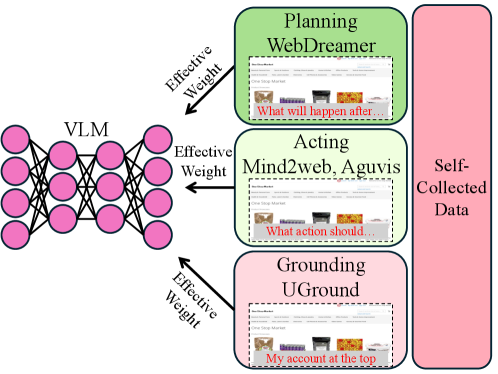
技术框架:OpAgent的整体架构包含以下几个主要模块:1)分层多任务微调的视觉-语言模型(VLM),负责理解用户指令和Web界面信息;2)在线交互环境,用于代理与真实Web环境的交互;3)混合奖励机制,包括WebJudge和基于规则的决策树(RDT),用于评估代理的行动效果并提供奖励信号;4)模块化的代理框架,包含规划器、基础器、反射器和摘要器,负责任务分解、信息提取、错误反思和行动总结。整个流程是:用户输入指令,VLM理解指令并生成行动计划,代理在Web环境中执行行动,混合奖励机制评估行动效果并提供奖励,反射器反思错误并进行自我纠正,摘要器总结经验并用于后续行动。
关键创新:OpAgent最重要的技术创新点在于将在线强化学习与模块化的代理框架相结合。传统的Web代理通常采用离线学习或单体架构,难以适应Web环境的动态变化和复杂性。OpAgent通过在线学习不断优化策略,并通过模块化设计实现更强大的错误恢复和自我纠正能力。此外,混合奖励机制的设计也有效地缓解了长时程导航中的信用分配挑战。
关键设计:OpAgent的关键设计包括:1)分层多任务微调的数据集构建,涵盖规划、行动和基础等多个方面;2)混合奖励机制中WebJudge和RDT的权重设置,需要根据实际情况进行调整;3)模块化代理框架中各个模块之间的协同方式,需要保证信息流畅传递和高效处理;4)在线强化学习算法的选择,例如PPO或DQN,需要根据具体任务和环境进行调整。
🖼️ 关键图片

📊 实验亮点
OpAgent在WebArena上取得了显著的实验结果,其RL增强模型实现了38.1%的成功率(pass@5),优于所有现有的单体基线。更重要的是,通过引入模块化的代理框架,OpAgent的性能进一步提升至71.6%的最新(SOTA)成功率,证明了其在Web导航任务中的强大能力。
🎯 应用场景
OpAgent具有广泛的应用前景,可用于自动化Web任务,如在线购物、信息搜索、数据录入等。它能够显著提高工作效率,降低人工成本,并为用户提供更便捷的Web服务。未来,OpAgent有望应用于智能客服、自动化测试、Web数据挖掘等领域,推动Web智能化发展。
📄 摘要(原文)
To fulfill user instructions, autonomous web agents must contend with the inherent complexity and volatile nature of real-world websites. Conventional paradigms predominantly rely on Supervised Fine-Tuning (SFT) or Offline Reinforcement Learning (RL) using static datasets. However, these methods suffer from severe distributional shifts, as offline trajectories fail to capture the stochastic state transitions and real-time feedback of unconstrained wide web environments. In this paper, we propose a robust Online Reinforcement Learning WebAgent, designed to optimize its policy through direct, iterative interactions with unconstrained wide websites. Our approach comprises three core innovations: 1) Hierarchical Multi-Task Fine-tuning: We curate a comprehensive mixture of datasets categorized by functional primitives -- Planning, Acting, and Grounding -- establishing a Vision-Language Model (VLM) with strong instruction-following capabilities for Web GUI tasks. 2) Online Agentic RL in the Wild: We develop an online interaction environment and fine-tune the VLM using a specialized RL pipeline. We introduce a Hybrid Reward Mechanism that combines a ground-truth-agnostic WebJudge for holistic outcome assessment with a Rule-based Decision Tree (RDT) for progress reward. This system effectively mitigates the credit assignment challenge in long-horizon navigation. Notably, our RL-enhanced model achieves a 38.1\% success rate (pass@5) on WebArena, outperforming all existing monolithic baselines. 3) Operator Agent: We introduce a modular agentic framework, namely \textbf{OpAgent}, orchestrating a Planner, Grounder, Reflector, and Summarizer. This synergy enables robust error recovery and self-correction, elevating the agent's performance to a new State-of-the-Art (SOTA) success rate of \textbf{71.6\%}.