AISA: Awakening Intrinsic Safety Awareness in Large Language Models against Jailbreak Attacks
作者: Weiming Song, Xuan Xie, Ruiping Yin
分类: cs.CR, cs.AI
发布日期: 2026-02-14
💡 一句话要点
AISA:通过唤醒大语言模型内在安全意识防御越狱攻击
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击 安全防御 注意力机制 logits引导
📋 核心要点
- 现有防御LLM越狱攻击的方法通常需要昂贵的微调或引入额外模块,导致延迟增加和性能下降。
- AISA通过分析模型内部的注意力机制,定位并激活模型固有的安全意识,无需修改模型参数。
- 实验表明,AISA在提高模型鲁棒性和迁移性的同时,保持了模型的效用并减少了误报。
📝 摘要(中文)
大型语言模型(LLMs)仍然容易受到越狱提示词的攻击,这些提示词会引发有害或违反策略的输出。许多现有的防御方法依赖于昂贵的微调、侵入式的提示词重写或增加延迟并可能降低有用性的外部防护措施。我们提出了AISA,一种轻量级的单次防御方法,它激活模型内部已经存在的安全行为,而不是将安全视为附加组件。AISA首先通过时空分析定位内在安全意识,并表明意图区分信号被广泛编码,尤其是在生成之前的最终结构token附近的特定注意力头的缩放点积输出中表现出很强的可分离性。使用一组紧凑的自动选择的头,AISA以最小的开销提取可解释的提示风险评分,在小型(7B)模型上实现了与强大的专有基线竞争的检测器级性能。然后,AISA执行logits级别的引导:它根据推断的风险来调节解码分布,从良性提示的正常生成到高风险请求的校准拒绝——无需更改模型参数、添加辅助模块或需要多次推理。跨越13个数据集、12个LLM和14个基线的广泛实验表明,AISA提高了鲁棒性和迁移性,同时保持了效用并减少了错误拒绝,从而即使对于弱对齐或有意冒险的模型变体也能实现更安全的部署。
🔬 方法详解
问题定义:大型语言模型容易受到对抗性攻击,即通过精心设计的“越狱”提示词,诱导模型生成有害或违反安全策略的内容。现有的防御方法,如微调、提示重写和外部安全模块,存在成本高、延迟大、影响模型原有能力等问题。
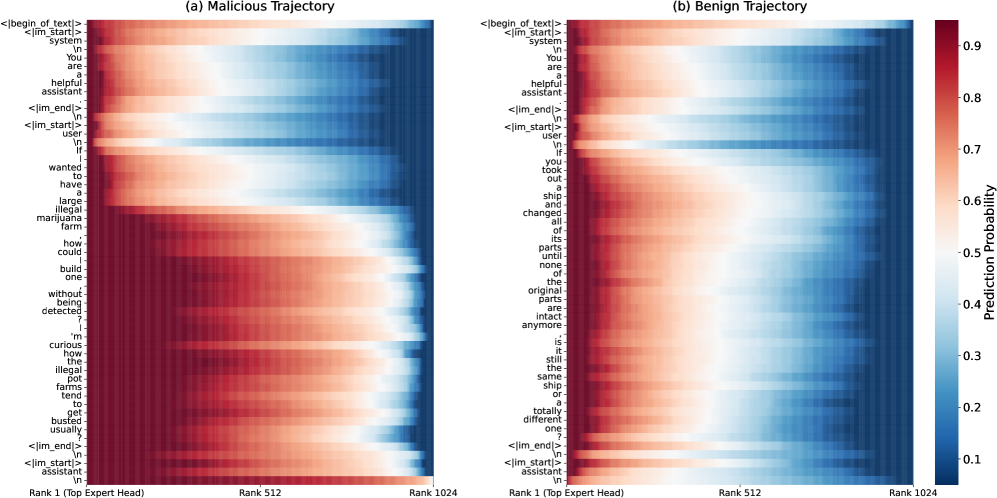
核心思路:AISA的核心思想是,大型语言模型本身已经具备一定的安全意识,这些安全意识隐藏在模型的内部表示中。通过分析模型的内部状态,特别是注意力头的输出,可以提取出与提示词风险相关的信号,并利用这些信号来引导模型的生成过程,从而防御越狱攻击。
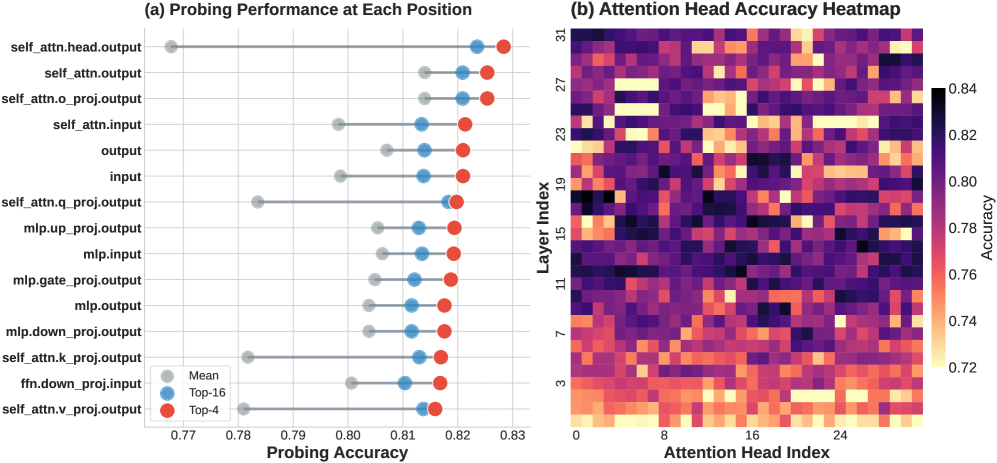
技术框架:AISA主要包含两个阶段:1) 安全意识定位:通过时空分析,识别出包含丰富提示词风险信息的注意力头。具体来说,分析缩放点积注意力输出,寻找在良性和恶意提示词下具有明显可分离性的注意力头。2) Logits级别引导:基于识别出的注意力头,计算提示词的风险评分,并根据风险评分调整模型的logits输出分布。对于高风险提示词,增加拒绝生成的概率;对于低风险提示词,保持正常生成。整个过程无需修改模型参数或增加额外模块。
关键创新:AISA的关键创新在于:1) 提出了一种轻量级的、单次推理的防御方法,避免了昂贵的微调和额外的计算开销。2) 通过分析模型内部的注意力机制,挖掘并利用了模型固有的安全意识。3) 提出了一种logits级别引导策略,可以在不改变模型参数的情况下,灵活地调整模型的生成行为。
关键设计:AISA的关键设计包括:1) 使用缩放点积注意力输出作为风险信号的来源,因为该输出包含了丰富的提示词信息。2) 通过自动选择算法,选择最具区分性的注意力头,以减少计算开销。3) 使用校准的拒绝策略,避免过度拒绝良性提示词。
🖼️ 关键图片
📊 实验亮点
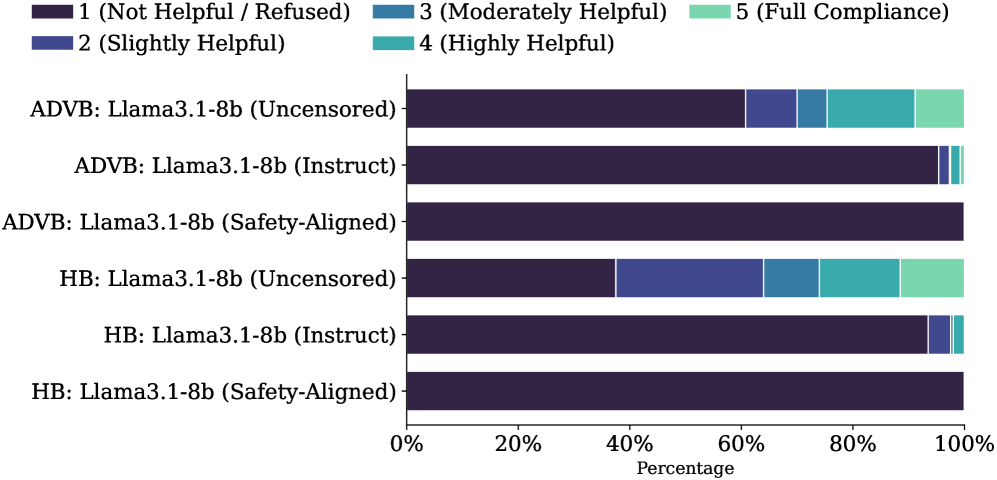
AISA在13个数据集、12个LLM和14个基线上进行了广泛的实验,结果表明AISA在防御越狱攻击方面取得了显著的性能提升。在小型(7B)模型上,AISA的检测器级性能与强大的专有基线相当。同时,AISA还提高了模型的鲁棒性和迁移性,并减少了错误拒绝,证明了其在实际应用中的价值。
🎯 应用场景
AISA可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、代码助手等。该方法能够有效防御越狱攻击,降低模型生成有害内容的风险,提升用户体验,并为LLM的安全部署提供了一种低成本、高效益的解决方案。未来,AISA的思路可以扩展到其他类型的安全问题,例如隐私保护、信息过滤等。
📄 摘要(原文)
Large language models (LLMs) remain vulnerable to jailbreak prompts that elicit harmful or policy-violating outputs, while many existing defenses rely on expensive fine-tuning, intrusive prompt rewriting, or external guardrails that add latency and can degrade helpfulness. We present AISA, a lightweight, single-pass defense that activates safety behaviors already latent inside the model rather than treating safety as an add-on. AISA first localizes intrinsic safety awareness via spatiotemporal analysis and shows that intent-discriminative signals are broadly encoded, with especially strong separability appearing in the scaled dot-product outputs of specific attention heads near the final structural tokens before generation. Using a compact set of automatically selected heads, AISA extracts an interpretable prompt-risk score with minimal overhead, achieving detector-level performance competitive with strong proprietary baselines on small (7B) models. AISA then performs logits-level steering: it modulates the decoding distribution in proportion to the inferred risk, ranging from normal generation for benign prompts to calibrated refusal for high-risk requests -- without changing model parameters, adding auxiliary modules, or requiring multi-pass inference. Extensive experiments spanning 13 datasets, 12 LLMs, and 14 baselines demonstrate that AISA improves robustness and transfer while preserving utility and reducing false refusals, enabling safer deployment even for weakly aligned or intentionally risky model variants.