Arming Data Agents with Tribal Knowledge
作者: Shubham Agarwal, Asim Biswal, Sepanta Zeighami, Alvin Cheung, Joseph Gonzalez, Aditya G. Parameswaran
分类: cs.DB, cs.AI
发布日期: 2026-02-13 (更新: 2026-02-17)
💡 一句话要点
Tk-Boost:利用部落知识增强NL2SQL数据代理,提升查询准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NL2SQL 自然语言查询 数据库 知识增强 大型语言模型 数据代理 部落知识
📋 核心要点
- 现有NL2SQL代理在处理大型真实数据库时,缺乏对数据意图的理解,容易产生误解,导致查询错误。
- Tk-Boost通过积累代理在数据库上的查询经验,识别其误解,并生成部落知识来纠正这些误解,从而提升查询准确性。
- 实验结果表明,Tk-Boost在Spider 2.0和BIRD基准测试中,分别将NL2SQL代理的准确性提高了高达16.9%和13.7%。
📝 摘要(中文)
本文提出Tk-Boost,一个用于增强NL2SQL代理的框架,通过“部落知识”来纠正代理在查询数据库时产生的误解。现有的NL2SQL代理在面对大型真实数据库时,由于缺乏对底层数据的正确利用知识(例如,每个列的意图)以及对数据的错误理解,导致查询错误。Tk-Boost通过让NL2SQL代理回答一些查询,分析其错误以识别误解,并生成相应的部落知识来解决这些问题,从而积累经验。为了实现准确检索,Tk-Boost使用适用性条件索引这些知识,这些条件指定了知识有用的查询特征。在回答新查询时,Tk-Boost利用这些知识向NL2SQL代理提供反馈,从而在SQL生成过程中解决代理的误解,提高代理的准确性。在BIRD和Spider 2.0基准测试中进行的大量实验表明,Tk-Boost将NL2SQL代理的准确性在Spider 2.0上提高了高达16.9%,在BIRD上提高了13.7%。
🔬 方法详解
问题定义:NL2SQL任务旨在将自然语言查询转换为SQL查询,但现有方法在处理大型真实数据库时,由于缺乏对数据库schema和数据的深入理解,容易产生误解,导致查询错误。现有的方法主要集中于直接从数据库内容生成事实,而忽略了纠正代理的固有误解。
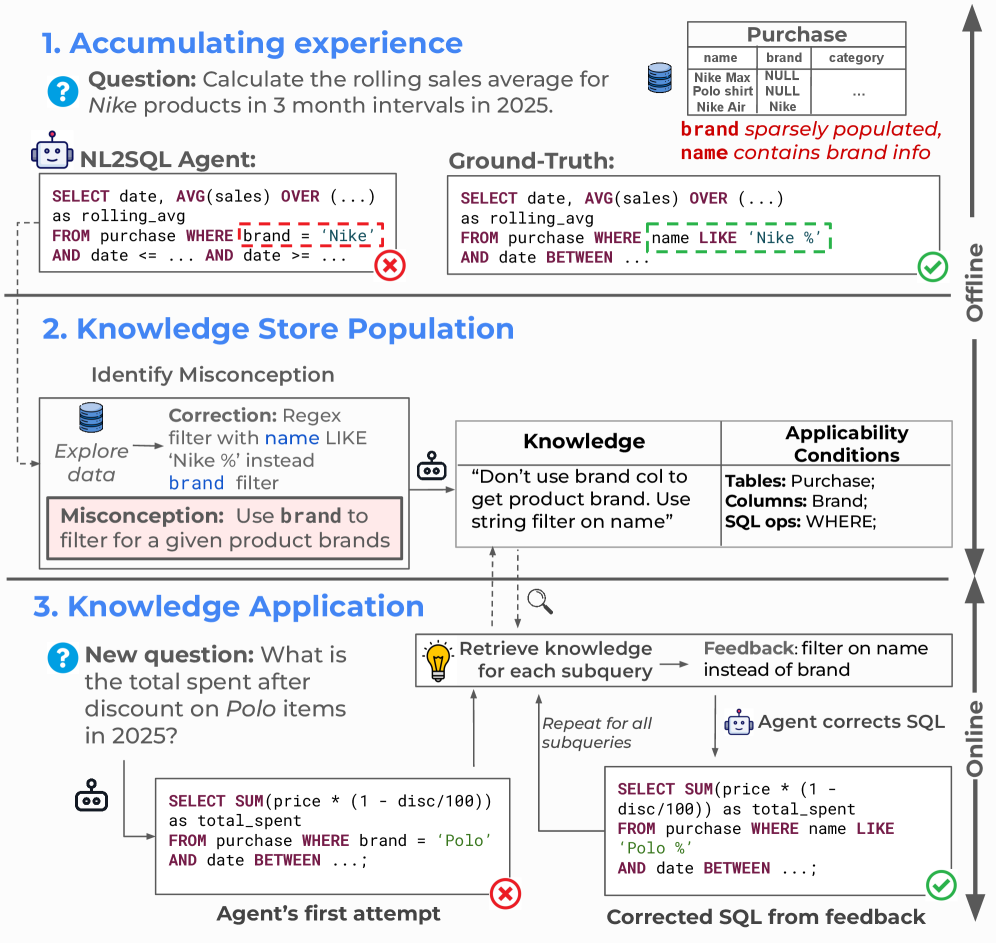
核心思路:Tk-Boost的核心思路是利用“部落知识”来纠正NL2SQL代理在查询数据库时产生的误解。“部落知识”是指通过使用数据库的经验积累起来的,能够纠正代理错误认知的知识。通过让代理在数据库上进行查询,分析其错误,并生成相应的知识来解决这些错误。
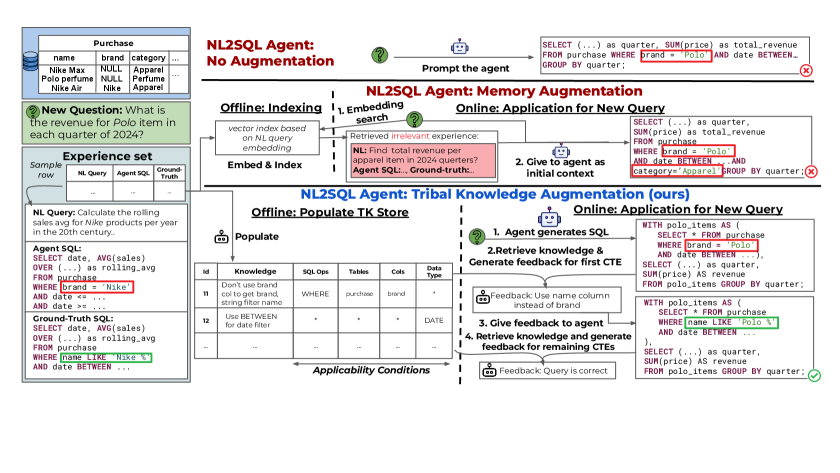
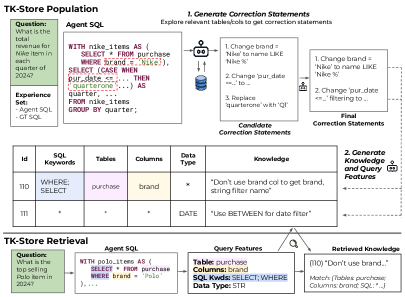
技术框架:Tk-Boost是一个附加框架,可以与任何NL2SQL代理集成。其主要流程包括:1) 查询执行:让NL2SQL代理执行一些查询。2) 误解识别:分析代理的错误,识别其对数据库的误解。3) 知识生成:生成用于纠正这些误解的“部落知识”。4) 知识索引:使用适用性条件(指定知识有用的查询特征)索引这些知识。5) 知识检索与反馈:在回答新查询时,检索相关知识,并向NL2SQL代理提供反馈,以纠正其误解。
关键创新:Tk-Boost的关键创新在于引入了“部落知识”的概念,并利用该知识来纠正NL2SQL代理的误解。与现有方法不同,Tk-Boost不是简单地重述数据库内容,而是主动识别和纠正代理的错误认知,从而更有效地提高查询准确性。
关键设计:Tk-Boost的关键设计包括:1) 误解识别方法:如何准确识别代理的误解是至关重要的,具体方法未知。2) 知识生成策略:如何生成有效的“部落知识”来纠正误解,具体方法未知。3) 适用性条件的设计:如何设计有效的适用性条件,以实现准确的知识检索,具体方法未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Tk-Boost能够显著提高NL2SQL代理的准确性。在Spider 2.0基准测试中,Tk-Boost将NL2SQL代理的准确性提高了高达16.9%,在BIRD基准测试中提高了13.7%。这些结果表明,Tk-Boost能够有效地纠正NL2SQL代理的误解,并提高其在真实世界数据库上的查询性能。
🎯 应用场景
Tk-Boost可应用于各种需要使用自然语言查询关系数据库的场景,例如企业数据分析、智能客服、数据可视化等。通过提高NL2SQL代理的准确性,Tk-Boost可以降低用户使用数据库的门槛,提高数据利用效率,并为决策提供更可靠的数据支持。未来,该技术有望扩展到更复杂的数据查询和分析任务中。
📄 摘要(原文)
Natural language to SQL (NL2SQL) translation enables non-expert users to query relational databases through natural language. Recently, NL2SQL agents, powered by the reasoning capabilities of Large Language Models (LLMs), have significantly advanced NL2SQL translation. Nonetheless, NL2SQL agents still make mistakes when faced with large-scale real-world databases because they lack knowledge of how to correctly leverage the underlying data (e.g., knowledge about the intent of each column) and form misconceptions about the data when querying it, leading to errors. Prior work has studied generating facts about the database to provide more context to NL2SQL agents, but such approaches simply restate database contents without addressing the agent's misconceptions. In this paper, we propose Tk-Boost, a bolt-on framework for augmenting any NL2SQL agent with tribal knowledge: knowledge that corrects the agent's misconceptions in querying the database accumulated through experience using the database. To accumulate experience, Tk-Boost first asks the NL2SQL agent to answer a few queries on the database, identifies the agent's misconceptions by analyzing its mistakes on the database, and generates tribal knowledge to address them. To enable accurate retrieval, Tk-Boost indexes this knowledge with applicability conditions that specify the query features for which the knowledge is useful. When answering new queries, Tk-Boost uses this knowledge to provide feedback to the NL2SQL agent, resolving the agent's misconceptions during SQL generation, and thus improving the agent's accuracy. Extensive experiments across the BIRD and Spider 2.0 benchmarks with various NL2SQL agents shows Tk-Boost improves NL2SQL agents accuracy by up to 16.9% on Spider 2.0 and 13.7% on BIRD