How Multimodal Large Language Models Support Access to Visual Information: A Diary Study With Blind and Low Vision People
作者: Ricardo E. Gonzalez Penuela, Crescentia Jung, Sharon Y Lin, Ruiying Hu, Shiri Azenkot
分类: cs.HC, cs.AI
发布日期: 2026-02-13 (更新: 2026-02-19)
备注: 24 pages, 17 figures, 7 tables, appendix section, to appear main track CHI 2026
💡 一句话要点
研究多模态大语言模型如何辅助视障人士获取视觉信息,揭示其在实际应用中的挑战与机遇。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉信息辅助 视障人士 日记研究 视觉助手 用户体验 可访问性
📋 核心要点
- 现有视觉解释工具仅提供描述,缺乏交互性,难以满足视障人士获取目标相关细节的需求。
- 本研究通过日记研究,记录视障人士使用MLLM视觉解释应用的真实情况,评估其性能和影响。
- 研究发现MLLM在描述准确性方面有所提升,但仍需提高“视觉助手”技能,以提供更可靠的辅助。
📝 摘要(中文)
多模态大语言模型(MLLM)正在改变视障人士(BLV)获取视觉信息的方式。与仅提供描述的传统视觉解释工具不同,MLLM支持的应用提供会话式辅助,用户可以通过提问来获取与目标相关的细节。为了评估其真实性能和对BLV人群日常生活的潜在影响,我们进行了一项为期两周的日记研究,记录了20名BLV参与者使用MLLM视觉解释应用的情况。尽管参与者对应用的视觉解释的“可信度”(平均3.76/5,最高为“非常可信”)和“满意度”(平均4.13/5,最高为“非常满意”)评价较高,但AI经常产生不正确的答案(22.2%)或拒绝响应用户请求(10.8%)。研究结果表明,虽然MLLM可以提高视觉解释的描述准确性,但支持日常使用还取决于“视觉助手”技能:即提供目标导向、可靠辅助的能力。最后,我们提出了“视觉助手”技能和指导原则,以帮助MLLM视觉解释应用更好地支持BLV人群获取视觉信息。
🔬 方法详解
问题定义:该论文旨在研究多模态大语言模型(MLLM)在辅助视障人士(BLV)获取视觉信息方面的实际应用效果。现有视觉解释工具的痛点在于仅仅提供图像的描述,缺乏交互性,无法根据用户的具体需求提供定制化的信息,导致BLV人群难以高效地获取目标相关的视觉信息。
核心思路:论文的核心思路是通过让BLV人群在日常生活中实际使用MLLM驱动的视觉解释应用,记录他们的使用情况和反馈,从而评估MLLM在真实场景下的性能和用户体验。通过分析用户的使用模式、遇到的问题和对系统的评价,揭示MLLM在辅助BLV人群获取视觉信息方面的优势和不足,并提出改进建议。
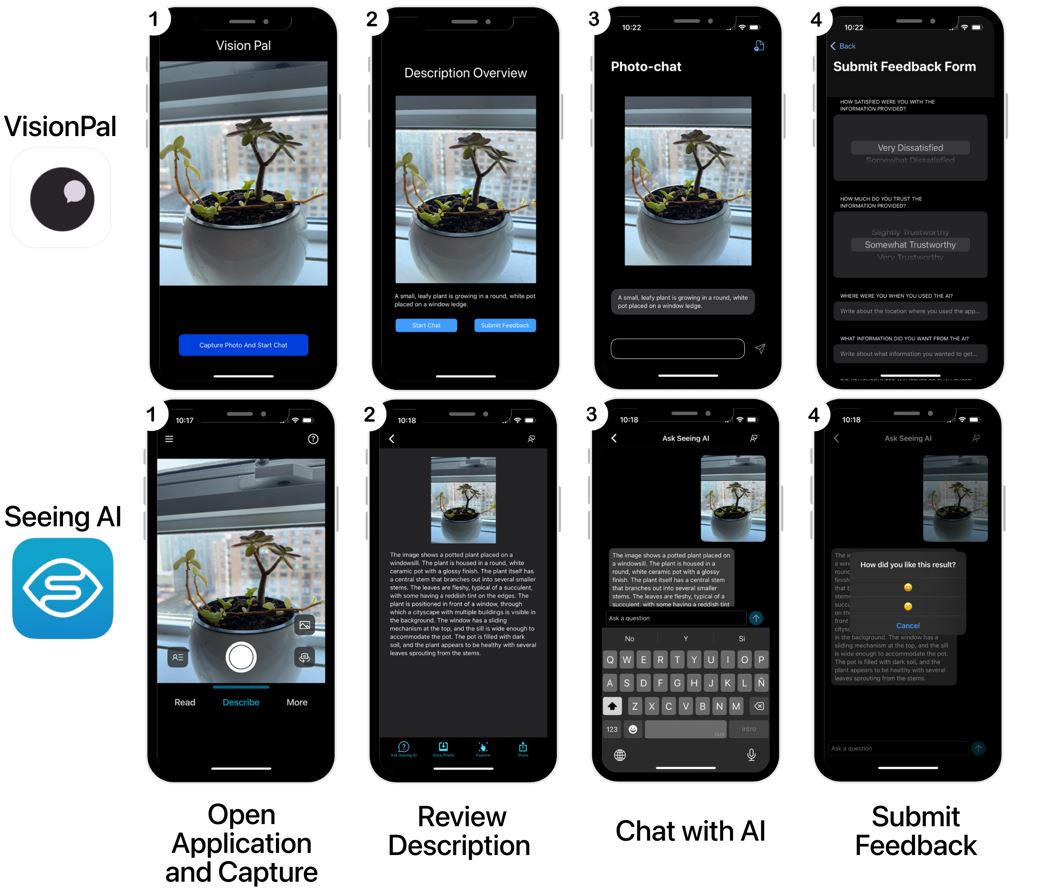
技术框架:该研究采用日记研究方法,招募了20名BLV参与者,让他们在为期两周的时间内使用一款MLLM驱动的视觉解释应用。研究人员收集了参与者的使用日志、提问记录和对系统反馈的评价。然后,研究人员对收集到的数据进行定量和定性分析,评估MLLM的准确性、可靠性和用户满意度。
关键创新:该研究的关键创新在于关注MLLM在真实世界中的应用,并从用户的角度评估其性能和影响。与以往的研究主要关注MLLM在特定任务上的性能不同,该研究关注MLLM在日常生活中如何帮助BLV人群获取视觉信息,并揭示了MLLM在实际应用中面临的挑战。提出了“视觉助手”技能的概念,强调了MLLM不仅需要具备准确的视觉理解能力,还需要具备提供目标导向、可靠辅助的能力。
关键设计:研究中使用的MLLM视觉解释应用的具体技术细节未知。但研究强调了视觉助手技能的重要性,这可能涉及到对MLLM进行微调,使其能够更好地理解用户的意图,并提供更相关、更可靠的答案。此外,可能还需要设计更友好的用户界面,方便BLV人群使用。
🖼️ 关键图片


📊 实验亮点
研究发现,参与者对MLLM视觉解释应用的可信度和满意度评价较高(平均分别为3.76/5和4.13/5)。然而,AI产生不正确答案的比例为22.2%,拒绝响应用户请求的比例为10.8%。这些数据表明,MLLM在视觉理解方面仍有提升空间,尤其是在提供可靠辅助方面。
🎯 应用场景
该研究成果可应用于开发更智能、更易用的视觉辅助工具,帮助视障人士更好地理解周围环境,提高生活质量。例如,可以应用于智能眼镜、手机应用等,为视障人士提供实时的视觉信息辅助。未来,结合更先进的MLLM技术,有望实现更个性化、更可靠的视觉辅助服务。
📄 摘要(原文)
Multimodal large language models (MLLMs) are changing how Blind and Low Vision (BLV) people access visual information. Unlike traditional visual interpretation tools that only provide descriptions, MLLM-enabled applications offer conversational assistance, where users can ask questions to obtain goal-relevant details. However, evidence about their performance in the real-world and implications for BLV people's daily lives remains limited. To address this, we conducted a two-week diary study, where we captured 20 BLV participants' use of an MLLM-enabled visual interpretation application. Although participants rated the visual interpretations of the application as "trustworthy" (mean=3.76 out of 5, max=extremely trustworthy) and "somewhat satisfying" (mean=4.13 out of 5, max=very satisfying), the AI often produced incorrect answers (22.2%) or abstained (10.8%) from responding to users' requests. Our findings show that while MLLMs can improve visual interpretations' descriptive accuracy, supporting everyday use also depends on the "visual assistant" skill: behaviors for providing goal-directed, reliable assistance. We conclude by proposing the "visual assistant" skill and guidelines to help MLLM-enabled visual interpretation applications better support BLV people's access to visual information.