On-Policy Supervised Fine-Tuning for Efficient Reasoning
作者: Anhao Zhao, Ziyang Chen, Junlong Tong, Yingqi Fan, Fanghua Ye, Shuhao Li, Yunpu Ma, Wenjie Li, Xiaoyu Shen
分类: cs.AI
发布日期: 2026-02-13
🔗 代码/项目: GITHUB
💡 一句话要点
提出On-Policy SFT,通过监督微调提升大推理模型的效率与准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理模型 监督微调 强化学习 链式思维
📋 核心要点
- 现有大推理模型依赖强化学习,计算成本高昂,且多重奖励目标训练不稳定,难以达到最优。
- 论文提出On-Policy SFT,简化奖励机制,通过监督微调优化模型,提升推理效率和准确率。
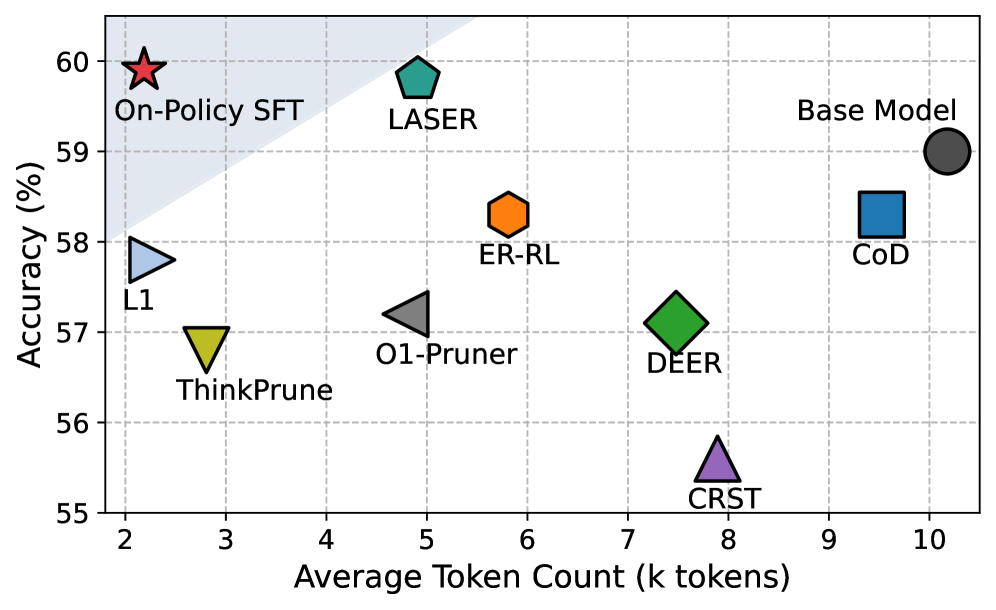
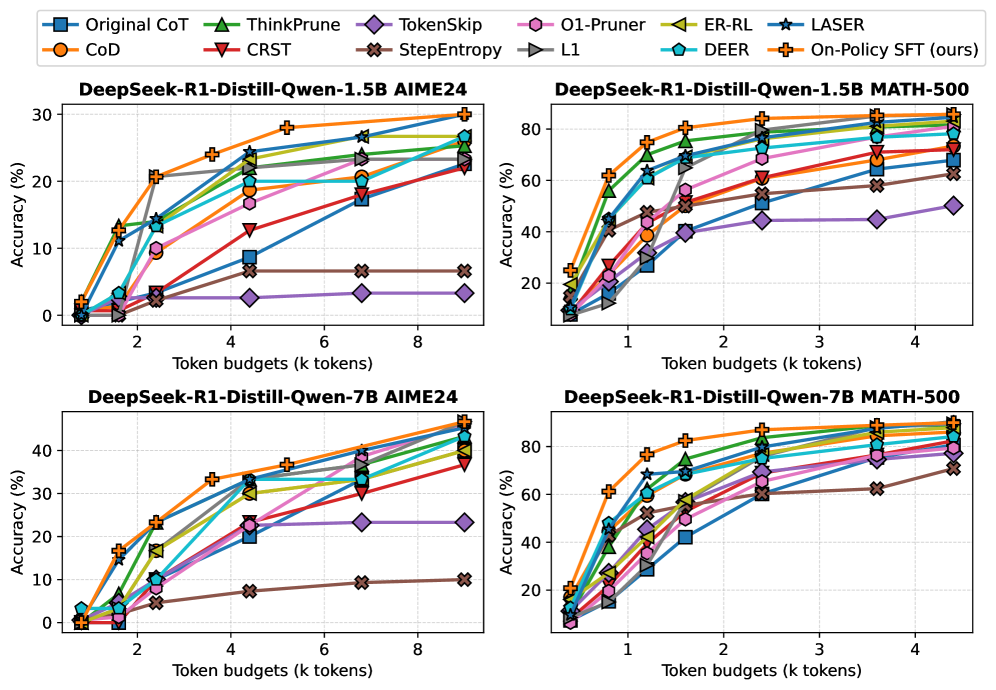
- 实验表明,On-Policy SFT在多个基准测试中超越了复杂的RL方法,显著降低了计算成本。
📝 摘要(中文)
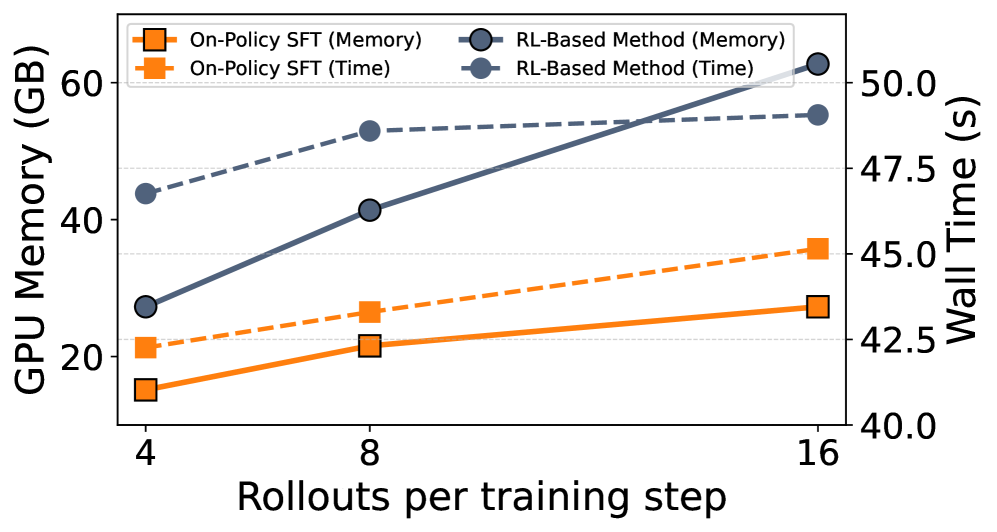
大型推理模型(LRM)通常使用强化学习(RL)进行训练,以探索长链式思维推理,虽然取得了强大的性能,但计算成本很高。最近的方法增加了多重奖励目标,以联合优化正确性和简洁性,但这些复杂的扩展往往会破坏训练的稳定性,并产生次优的权衡。本文重新审视了这一目标,并对这种复杂性的必要性提出了质疑。通过原则性分析,我们发现这种范式存在根本性的错位:当正确性和长度可以直接验证时,KL正则化失去了其预期的作用,并且在多个奖励信号下,组归一化变得模糊。通过移除这两个项目并将奖励简化为基于截断的长度惩罚,我们表明优化问题简化为对经过正确性和简洁性过滤的自生成数据进行监督微调。我们将这种简化的训练策略称为on-policy SFT。尽管它很简单,但on-policy SFT始终定义了准确性-效率的帕累托前沿。它在保持原始准确性的同时,将CoT长度最多减少80%,超过了五项基准测试中更复杂的基于RL的方法。此外,它显着提高了训练效率,将GPU内存使用量减少了50%,并将收敛速度提高了70%。
🔬 方法详解
问题定义:现有的大型推理模型(LRMs)通常采用强化学习(RL)进行训练,以实现长链式思维(Chain-of-Thought, CoT)推理。然而,这种方法计算成本高昂,并且为了同时优化正确性和简洁性而引入的多重奖励目标,往往会使训练过程不稳定,导致次优的结果。现有的方法在奖励函数设计和训练策略上存在复杂性,使得模型难以达到效率和准确率之间的最佳平衡。
核心思路:论文的核心思路是通过简化训练流程,将复杂的强化学习训练过程转化为监督微调(SFT)问题。具体来说,通过移除不必要的KL正则化和组归一化,并将奖励函数简化为基于截断的长度惩罚,使得优化目标更加明确,从而能够直接利用监督学习的方法进行训练。这种方法旨在消除强化学习训练中的不稳定性,并提高训练效率。
技术框架:On-Policy SFT的整体框架包括以下几个主要步骤:首先,使用模型自身生成推理数据;然后,对生成的数据进行过滤,只保留那些既正确又简洁的样本;最后,使用过滤后的数据对模型进行监督微调。这个过程是“on-policy”的,因为微调的数据是由当前策略生成的。
关键创新:最重要的技术创新点在于将复杂的强化学习训练过程简化为监督微调。与现有方法相比,On-Policy SFT避免了强化学习训练中的探索和利用的权衡,以及多重奖励目标带来的不稳定性。通过直接优化正确性和简洁性,On-Policy SFT能够更有效地训练模型,并达到更好的性能。
关键设计:关键的设计包括:1) 移除KL正则化和组归一化,简化优化目标;2) 使用基于截断的长度惩罚作为奖励函数,鼓励模型生成简洁的推理过程;3) 使用模型自身生成的数据进行训练,保证训练数据与模型当前策略的一致性;4) 对生成的数据进行过滤,只保留既正确又简洁的样本,提高训练数据的质量。
🖼️ 关键图片
📊 实验亮点
On-Policy SFT在五个基准测试中超越了更复杂的基于RL的方法,在保持原始准确性的同时,将CoT长度最多减少80%。此外,它还显著提高了训练效率,将GPU内存使用量减少了50%,并将收敛速度提高了70%。这些结果表明,On-Policy SFT是一种高效且有效的训练策略,能够显著提升大型推理模型的性能。
🎯 应用场景
该研究成果可广泛应用于需要高效推理的场景,例如问答系统、对话生成、代码生成等。通过降低计算成本和提高推理效率,On-Policy SFT能够使大型推理模型在资源受限的环境中部署,并加速相关应用的开发和落地。此外,该方法还可以作为一种通用的训练策略,用于优化其他类型的生成模型。
📄 摘要(原文)
Large reasoning models (LRMs) are commonly trained with reinforcement learning (RL) to explore long chain-of-thought reasoning, achieving strong performance at high computational cost. Recent methods add multi-reward objectives to jointly optimize correctness and brevity, but these complex extensions often destabilize training and yield suboptimal trade-offs. We revisit this objective and challenge the necessity of such complexity. Through principled analysis, we identify fundamental misalignments in this paradigm: KL regularization loses its intended role when correctness and length are directly verifiable, and group-wise normalization becomes ambiguous under multiple reward signals. By removing these two items and simplifying the reward to a truncation-based length penalty, we show that the optimization problem reduces to supervised fine-tuning on self-generated data filtered for both correctness and conciseness. We term this simplified training strategy on-policy SFT. Despite its simplicity, on-policy SFT consistently defines the accuracy-efficiency Pareto frontier. It reduces CoT length by up to 80 while maintaining original accuracy, surpassing more complex RL-based methods across five benchmarks. Furthermore, it significantly enhances training efficiency, reducing GPU memory usage by 50% and accelerating convergence by 70%. Our code is available at https://github.com/EIT-NLP/On-Policy-SFT.