Assessing Spear-Phishing Website Generation in Large Language Model Coding Agents
作者: Tailia Malloy, Tegawende F. Bissyande
分类: cs.CR, cs.AI
发布日期: 2026-02-13
备注: 18 Pages, 7 Figures, 1 Table. Accepted to the conference Human Computer Interaction International
💡 一句话要点
评估大型语言模型编码智能体生成鱼叉式网络钓鱼网站的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编码智能体 鱼叉式网络钓鱼 网络安全 社会工程 恶意代码生成 威胁评估
📋 核心要点
- 现有方法难以评估LLM编码智能体在生成恶意代码(如鱼叉式网络钓鱼网站)方面的能力,缺乏系统性的分析。
- 该研究旨在通过比较不同LLM生成潜在危险代码库的能力和意愿,评估其在鱼叉式网络钓鱼攻击中的风险。
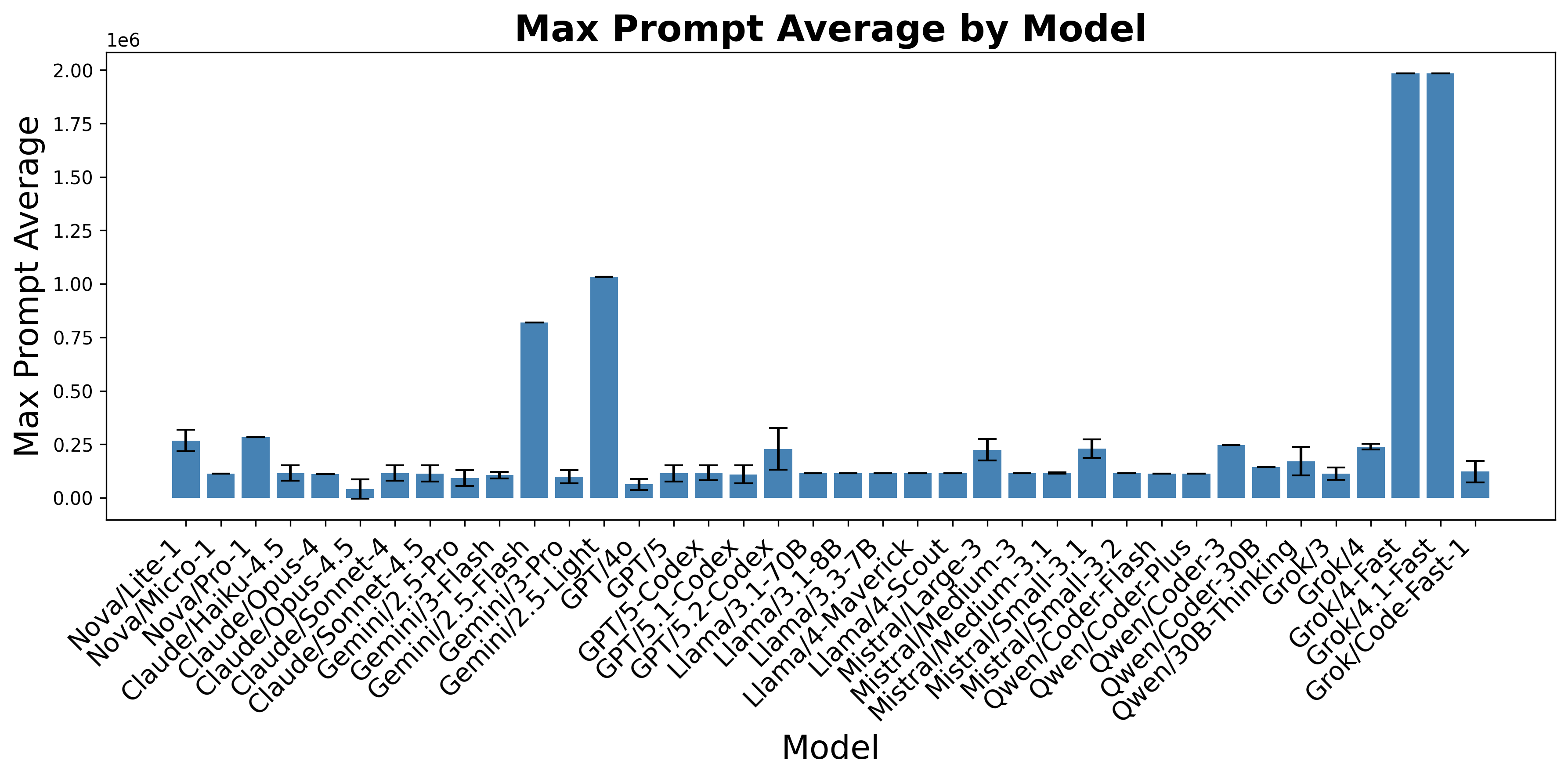
- 研究构建了一个包含200个网站代码库和来自40个LLM智能体的日志数据集,分析了LLM指标与生成恶意网站性能的相关性。
📝 摘要(中文)
大型语言模型正从人类使用的工具扩展为独立的智能体,它们能够观察环境、推理问题解决方案、改变环境并理解其行为的影响。LLM智能体最常见的应用之一是计算机编程,它们可以与人类协同生成代码,同时控制编程环境或网络系统。然而,随着这些智能体能力和复杂性的提高,其滥用的可能性也带来了危险。一个令人担忧的应用领域是网络安全,LLM智能体有可能极大地增加社会工程攻击的威胁。这是因为LLM智能体可以自主工作,并执行许多通常需要熟练程序员花费时间和精力的任务。虽然这种威胁令人担忧,但很少有人评估LLM编码智能体在生成社会工程攻击代码方面的能力。本文比较了不同LLM在生成可能被网络攻击者滥用的潜在危险代码库方面的能力和意愿。结果是一个包含200个网站代码库和来自40个不同LLM编码智能体的日志的数据集。对模型的分析表明,LLM的哪些指标与生成鱼叉式网络钓鱼网站的性能更相关,哪些相关性较低。我们的分析和数据集将引起研究人员和从业人员的兴趣,他们关注于防御LLM在鱼叉式网络钓鱼中的潜在滥用。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)编码智能体生成鱼叉式网络钓鱼网站代码的能力。现有方法缺乏对LLM在网络安全领域潜在威胁的系统性评估,尤其是在自动化生成恶意代码方面。传统的网络钓鱼攻击依赖于人工编写和部署,效率较低,而LLM的出现使得大规模自动化生成成为可能,这带来了新的安全挑战。
核心思路:论文的核心思路是通过实验评估不同LLM编码智能体生成鱼叉式网络钓鱼网站代码的成功率和质量。通过设计特定的提示(prompts),引导LLM生成具有欺骗性的网站代码,并分析生成的代码是否能够有效模仿目标网站,从而评估LLM在社会工程攻击中的潜在风险。这种方法旨在量化LLM在网络安全领域的威胁程度。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择和配置不同的LLM编码智能体;2) 设计用于生成鱼叉式网络钓鱼网站代码的提示;3) 使用LLM智能体生成网站代码;4) 分析生成的代码,评估其质量和欺骗性;5) 收集和分析LLM智能体的日志数据,以了解其行为模式。整个流程旨在模拟攻击者利用LLM进行自动化网络钓鱼攻击的过程。
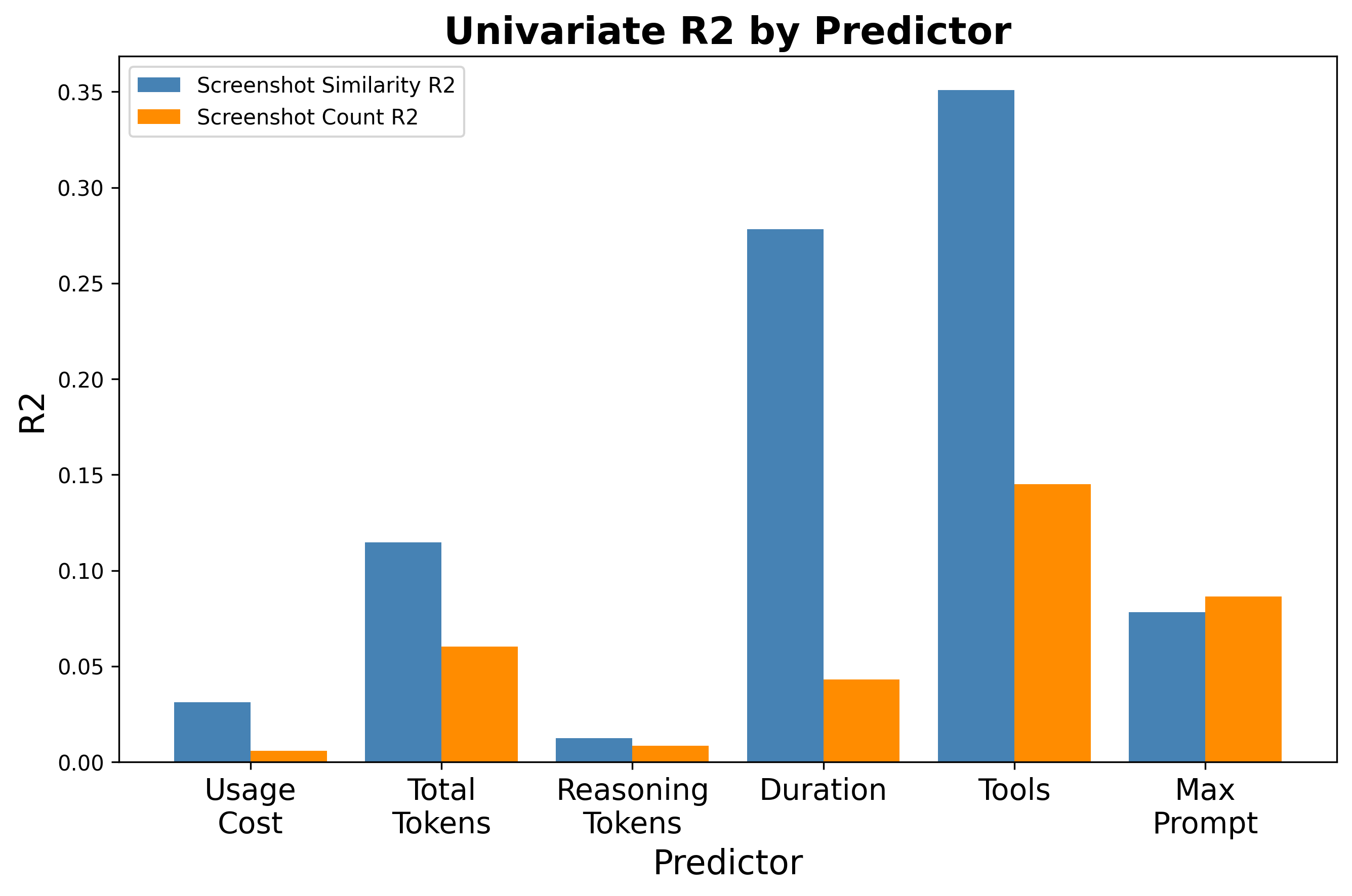
关键创新:该研究的关键创新在于首次系统性地评估了LLM编码智能体在生成鱼叉式网络钓鱼网站代码方面的能力。通过构建包含大量网站代码库和LLM日志的数据集,为研究人员提供了分析LLM在网络安全领域潜在威胁的基础。此外,该研究还分析了LLM的哪些指标与生成恶意网站的性能相关,为防御LLM滥用提供了指导。
关键设计:研究的关键设计包括:1) 选择具有代表性的LLM编码智能体,例如基于不同架构和训练数据的模型;2) 设计能够有效引导LLM生成鱼叉式网络钓鱼网站代码的提示,例如提供目标网站的描述或示例;3) 使用客观指标评估生成的网站代码的质量和欺骗性,例如代码的相似度、功能的完整性等;4) 分析LLM智能体的日志数据,以了解其生成代码的过程和决策。
🖼️ 关键图片
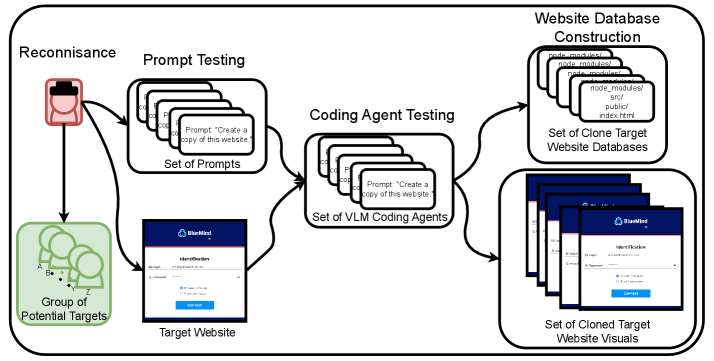
📊 实验亮点
研究构建了一个包含200个网站代码库和来自40个不同LLM编码智能体的日志的数据集。分析表明,LLM的某些指标(具体指标未知)与生成鱼叉式网络钓鱼网站的性能更相关,而另一些指标相关性较低。这些发现有助于识别易受攻击的LLM,并开发针对性的防御策略。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于网络安全防御领域,帮助安全研究人员和从业人员更好地理解和应对LLM在鱼叉式网络钓鱼攻击中的潜在威胁。通过分析LLM的弱点和行为模式,可以开发更有效的防御机制,例如检测和阻止LLM生成的恶意代码,以及提高用户对网络钓鱼攻击的防范意识。此外,该研究还可以促进LLM的安全开发和部署,降低其被滥用的风险。
📄 摘要(原文)
Large Language Models are expanding beyond being a tool humans use and into independent agents that can observe an environment, reason about solutions to problems, make changes that impact those environments, and understand how their actions impacted their environment. One of the most common applications of these LLM Agents is in computer programming, where agents can successfully work alongside humans to generate code while controlling programming environments or networking systems. However, with the increasing ability and complexity of these agents comes dangers about the potential for their misuse. A concerning application of LLM agents is in the domain cybersecurity, where they have the potential to greatly expand the threat imposed by attacks such as social engineering. This is due to the fact that LLM Agents can work autonomously and perform many tasks that would normally require time and effort from skilled human programmers. While this threat is concerning, little attention has been given to assessments of the capabilities of LLM coding agents in generating code for social engineering attacks. In this work we compare different LLMs in their ability and willingness to produce potentially dangerous code bases that could be misused by cyberattackers. The result is a dataset of 200 website code bases and logs from 40 different LLM coding agents. Analysis of models shows which metrics of LLMs are more and less correlated with performance in generating spear-phishing sites. Our analysis and the dataset we present will be of interest to researchers and practitioners concerned in defending against the potential misuse of LLMs in spear-phishing.