Asynchronous Verified Semantic Caching for Tiered LLM Architectures
作者: Asmit Kumar Singh, Haozhe Wang, Laxmi Naga Santosh Attaluri, Tak Chiam, Weihua Zhu
分类: cs.IR, cs.AI
发布日期: 2026-02-13
💡 一句话要点
Krites:异步验证语义缓存,提升分层LLM架构静态缓存覆盖率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义缓存 大型语言模型 分层架构 异步验证 LLM判断
📋 核心要点
- 现有分层LLM缓存策略依赖单一相似度阈值,难以兼顾缓存命中率和语义准确性。
- Krites通过异步LLM判断机制,验证低于阈值的静态缓存结果,安全地提升缓存覆盖率。
- 实验表明,Krites在不影响关键路径延迟的前提下,显著提升了静态缓存的命中率。
📝 摘要(中文)
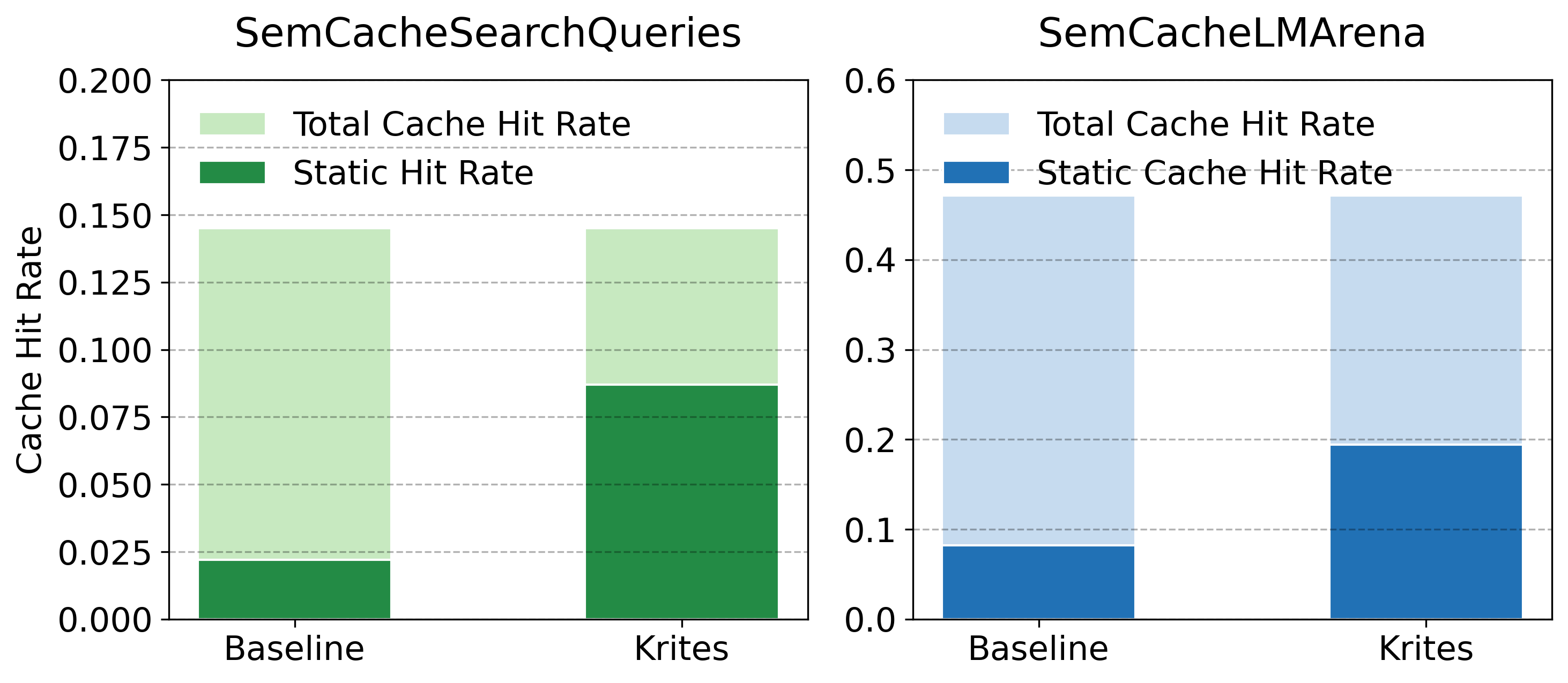
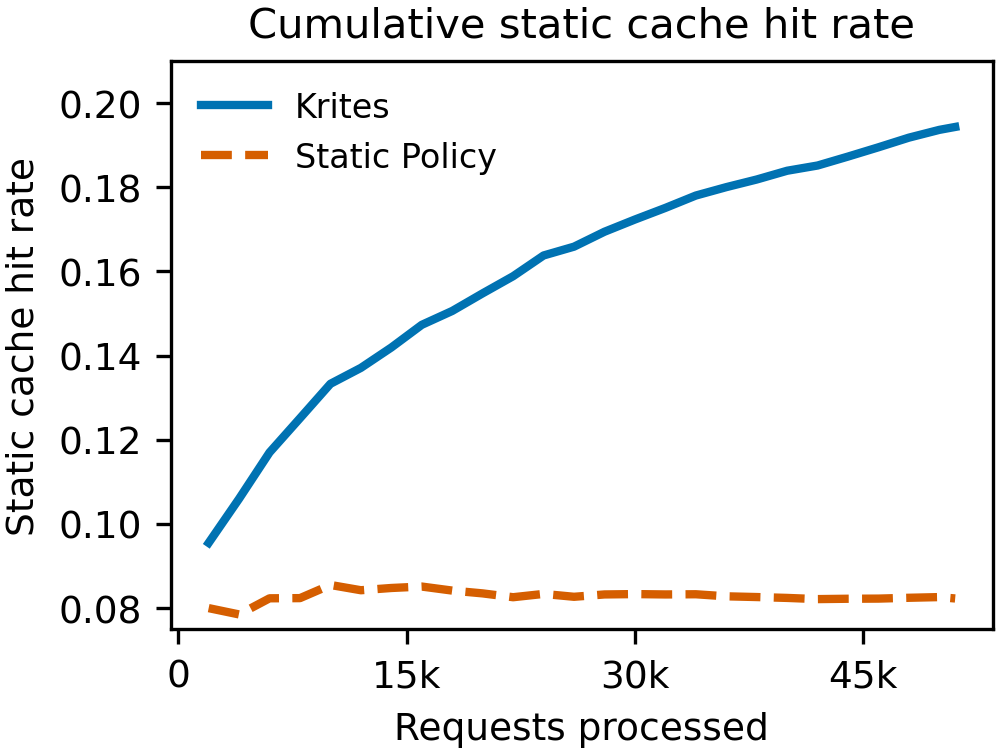
大型语言模型(LLMs)已成为搜索、助手和智能体工作流的关键组成部分,因此语义缓存对于降低推理成本和延迟至关重要。生产环境通常采用分层静态-动态设计:静态缓存包含来自日志的、经过离线审查的精选响应,动态缓存则在线填充。实践中,两层缓存通常由单一的嵌入相似度阈值控制,这导致了一个艰难的权衡:保守的阈值会错过安全重用机会,而激进的阈值则可能提供语义上不正确的响应。我们引入了Krites,一种异步的、由LLM判断的缓存策略,它可以在不改变服务决策的情况下扩展静态缓存的覆盖范围。在关键路径上,Krites的行为与标准静态阈值策略完全相同。当提示的最近静态邻居略低于静态阈值时,Krites异步调用LLM判断器来验证静态响应对于新提示是否可接受。批准的匹配项会被提升到动态缓存中,从而允许未来的重复和释义重用精选的静态答案,并随着时间的推移扩展静态缓存的覆盖范围。在会话和搜索工作负载的跟踪驱动模拟中,相对于调整后的基线,Krites将使用精选静态答案(直接静态命中加上验证提升)服务的请求比例提高了高达3.9倍,且关键路径延迟不变。
🔬 方法详解
问题定义:论文旨在解决分层LLM架构中,静态-动态缓存策略因单一相似度阈值而导致的缓存利用率不足问题。现有方法要么过于保守,导致错过潜在的缓存命中;要么过于激进,引入语义错误的风险。这种权衡限制了静态缓存的覆盖范围,增加了推理成本和延迟。
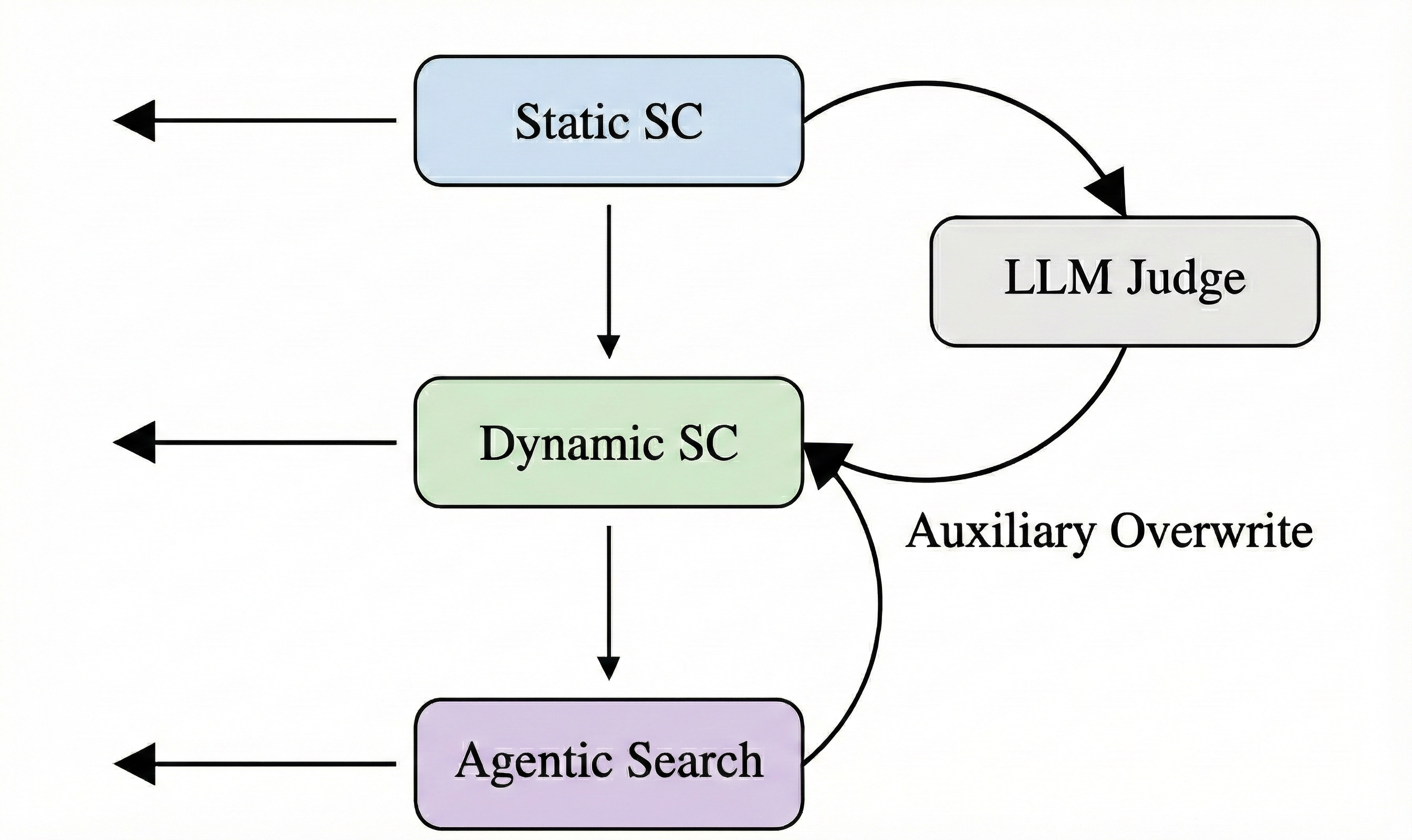
核心思路:Krites的核心思路是在不影响关键路径性能的前提下,利用LLM作为裁判,异步验证那些相似度略低于静态阈值的缓存结果。通过LLM的语义理解能力,判断这些结果是否可以安全地用于当前请求,从而扩展静态缓存的有效覆盖范围。
技术框架:Krites采用分层缓存架构,包含静态缓存和动态缓存。当接收到请求时,首先查询静态缓存。如果静态缓存命中,则直接返回结果。如果未命中,但最相似的静态缓存结果的相似度略低于阈值,则触发异步LLM判断。LLM判断结果如果为“可接受”,则将该静态缓存结果提升到动态缓存,并返回给用户。后续相似请求可以直接从动态缓存中获取结果。
关键创新:Krites的关键创新在于引入了异步LLM判断机制,用于验证“准命中”的静态缓存结果。这种方法避免了在关键路径上引入额外的延迟,同时利用LLM的语义理解能力,更准确地判断缓存结果的可用性。与传统的基于单一相似度阈值的缓存策略相比,Krites能够更有效地利用静态缓存,提高缓存命中率。
关键设计:Krites的关键设计包括:(1) 异步LLM判断的触发阈值,需要仔细调整以平衡判断频率和缓存命中率的提升;(2) LLM判断器的选择,需要考虑判断的准确性和延迟;(3) 动态缓存的更新策略,需要避免频繁更新导致性能下降;(4) LLM判断的prompt设计,需要确保LLM能够准确理解请求和缓存结果的语义。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Krites在会话和搜索工作负载下,相对于经过调优的基线方法,可以将使用精选静态答案服务的请求比例提高高达3.9倍,同时保持关键路径延迟不变。这意味着Krites能够在不影响用户体验的前提下,显著提高缓存效率,降低推理成本。
🎯 应用场景
Krites适用于各种需要低延迟和高吞吐量的大型语言模型应用场景,例如智能客服、搜索引擎、问答系统等。通过提高缓存命中率,Krites可以显著降低推理成本,提高系统响应速度,并提升用户体验。该方法尤其适用于那些拥有大量历史数据,可以构建高质量静态缓存的应用。
📄 摘要(原文)
Large language models (LLMs) now sit in the critical path of search, assistance, and agentic workflows, making semantic caching essential for reducing inference cost and latency. Production deployments typically use a tiered static-dynamic design: a static cache of curated, offline vetted responses mined from logs, backed by a dynamic cache populated online. In practice, both tiers are commonly governed by a single embedding similarity threshold, which induces a hard tradeoff: conservative thresholds miss safe reuse opportunities, while aggressive thresholds risk serving semantically incorrect responses. We introduce \textbf{Krites}, an asynchronous, LLM-judged caching policy that expands static coverage without changing serving decisions. On the critical path, Krites behaves exactly like a standard static threshold policy. When the nearest static neighbor of the prompt falls just below the static threshold, Krites asynchronously invokes an LLM judge to verify whether the static response is acceptable for the new prompt. Approved matches are promoted into the dynamic cache, allowing future repeats and paraphrases to reuse curated static answers and expanding static reach over time. In trace-driven simulations on conversational and search workloads, Krites increases the fraction of requests served with curated static answers (direct static hits plus verified promotions) by up to $\textbf{3.9}$ times for conversational traffic and search-style queries relative to tuned baselines, with unchanged critical path latency.