TriGen: NPU Architecture for End-to-End Acceleration of Large Language Models based on SW-HW Co-Design
作者: Jonghun Lee, Junghoon Lee, Hyeonjin Kim, Seoho Jeon, Jisup Yoon, Hyunbin Park, Meejeong Park, Heonjae Ha
分类: cs.AR, cs.AI
发布日期: 2026-02-13
备注: 13 pages, 14 figures
💡 一句话要点
TriGen:基于软硬件协同设计的端到端大语言模型加速NPU架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NPU架构 大语言模型 软硬件协同设计 低精度计算 边缘计算
📋 核心要点
- 现有NPU架构难以在资源受限设备上高效执行日益增长的大语言模型,因为LLM参数复用率低,对端到端执行构成挑战。
- TriGen通过软硬件协同设计,采用低精度计算、LUT优化非线性运算以及调度技术,为资源受限环境定制高效的LLM加速方案。
- 实验结果表明,TriGen在多种LLM上实现了显著的性能提升,平均加速2.73倍,内存传输减少52%,同时保持了可接受的精度。
📝 摘要(中文)
本文提出TriGen,一种新颖的NPU架构,通过软硬件协同设计,专为资源受限环境下的AI推理加速而定制。TriGen采用微缩放(MX)低精度计算,在保持精度的同时实现额外的优化机会,并解决了由此产生的问题。为了联合优化非线性和线性运算,TriGen通过使用快速且精确的LUT消除了对专用非线性运算硬件的需求,从而最大限度地提高了性能增益并降低了片上环境中的硬件成本。此外,考虑到实际的硬件约束,TriGen还采用了调度技术,即使在有限的片上存储容量下也能最大限度地提高计算利用率。在各种LLM上的评估表明,TriGen相比基线NPU设计实现了平均2.73倍的性能加速和52%的内存传输减少,且精度损失可忽略不计。
🔬 方法详解
问题定义:现有的大语言模型(LLM)由于模型规模庞大,参数复用率低,在资源受限的设备上进行端到端推理面临巨大的挑战。传统的NPU架构难以同时兼顾性能、功耗和内存占用,无法满足LLM在边缘设备上的部署需求。
核心思路:TriGen的核心思路是通过软硬件协同设计,针对LLM的特性进行优化。具体而言,采用低精度计算来降低计算复杂度和内存需求,利用LUT加速非线性运算,并设计高效的调度策略来提高硬件利用率。
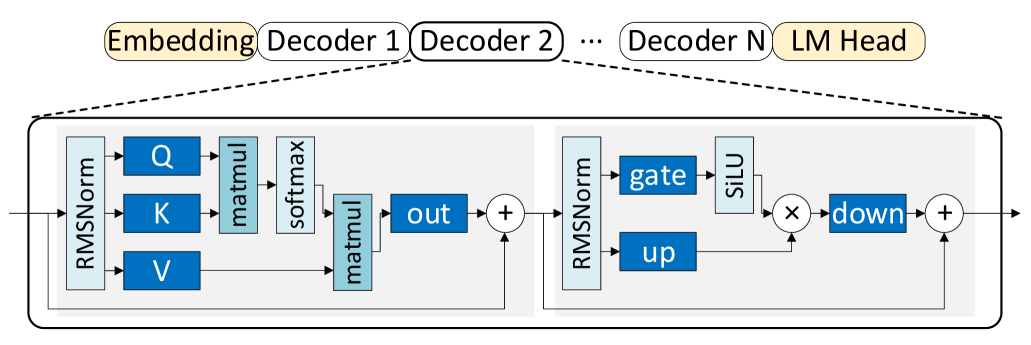
技术框架:TriGen的整体架构包含计算单元、存储单元和控制单元。计算单元采用微缩放(MX)低精度计算,存储单元采用片上SRAM,控制单元负责指令调度和数据传输。TriGen通过LUT来加速非线性激活函数,避免了专用硬件电路的设计。此外,TriGen还采用了数据重用和流水线技术来提高计算效率。
关键创新:TriGen的关键创新在于软硬件协同设计。一方面,通过微缩放低精度计算和LUT优化,降低了硬件复杂度,提高了计算效率。另一方面,通过调度策略,最大限度地利用了有限的片上存储资源,避免了频繁的片外数据访问。
关键设计:TriGen的关键设计包括:1) 微缩放低精度计算的量化方案,需要在精度和性能之间进行权衡;2) LUT的查找表设计,需要在存储空间和查找速度之间进行平衡;3) 调度策略的设计,需要考虑数据依赖关系和硬件资源约束。
🖼️ 关键图片
📊 实验亮点
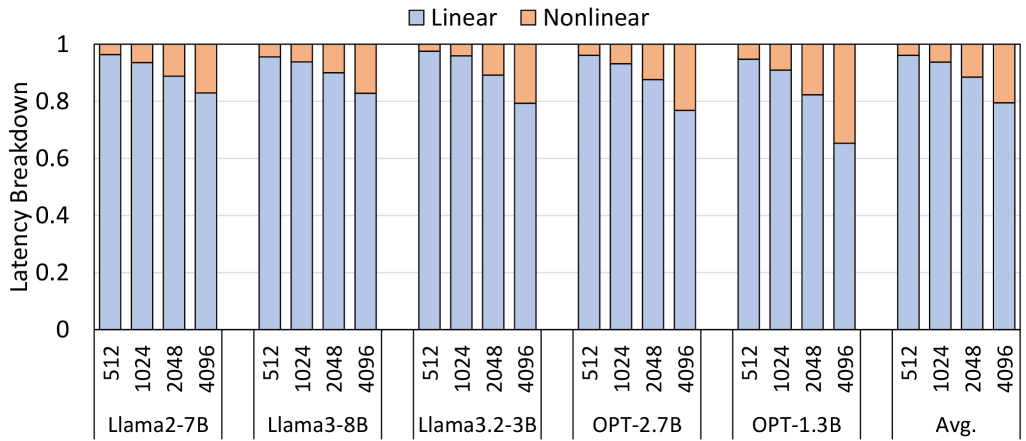
实验结果表明,TriGen在各种LLM上实现了显著的性能提升。与基线NPU设计相比,TriGen实现了平均2.73倍的性能加速和52%的内存传输减少,同时精度损失可忽略不计。这些结果表明,TriGen是一种高效且实用的LLM加速方案,适用于资源受限的边缘设备。
🎯 应用场景
TriGen架构适用于各种资源受限的边缘设备,例如智能手机、物联网设备和可穿戴设备。它可以加速这些设备上的LLM推理,从而实现本地化的自然语言处理应用,例如智能助手、机器翻译和文本摘要。该研究有助于推动LLM在边缘计算领域的应用,并为未来的NPU架构设计提供参考。
📄 摘要(原文)
Recent studies have extensively explored NPU architectures for accelerating AI inference in on-device environments, which are inherently resource-constrained. Meanwhile, transformer-based large language models (LLMs) have become dominant, with rapidly increasing model sizes but low degree of parameter reuse compared to conventional CNNs, making end-to-end execution on resource-limited devices extremely challenging. To address these challenges, we propose TriGen, a novel NPU architecture tailored for resource-constrained environments through software-hardware co-design. Firstly, TriGen adopts low-precision computation using microscaling (MX) to enable additional optimization opportunities while preserving accuracy, and resolves the issues that arise by employing such precision. Secondly, to jointly optimize both nonlinear and linear operations, TriGen eliminates the need for specialized hardware for essential nonlinear operations by using fast and accurate LUT, thereby maximizing performance gains and reducing hardware-cost in on-device environments, and finally, by taking practical hardware constraints into account, further employs scheduling techniques to maximize computational utilization even under limited on-chip memory capacity. We evaluate the performance of TriGen on various LLMs and show that TriGen achieves an average 2.73x performance speedup and 52% less memory transfer over the baseline NPU design with negligible accuracy loss.