BrowseComp-$V^3$: A Visual, Vertical, and Verifiable Benchmark for Multimodal Browsing Agents
作者: Huanyao Zhang, Jiepeng Zhou, Bo Li, Bowen Zhou, Yanzhe Dan, Haishan Lu, Zhiyong Cao, Jiaoyang Chen, Yuqian Han, Zinan Sheng, Zhengwei Tao, Hao Liang, Jialong Wu, Yang Shi, Yuanpeng He, Jiaye Lin, Qintong Zhang, Guochen Yan, Runhao Zhao, Zhengpin Li, Xiaohan Yu, Lang Mei, Chong Chen, Wentao Zhang, Bin Cui
分类: cs.AI
发布日期: 2026-02-13
💡 一句话要点
提出BrowseComp-$V^3$多模态浏览Agent基准,解决现有基准在复杂性、可访问性和评估粒度上的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 网页浏览Agent 深度搜索 基准测试 多跳推理 视觉感知 信息集成
📋 核心要点
- 现有网页浏览Agent基准在任务难度、证据获取和评估细致度上存在不足,难以全面评估Agent的深度搜索能力。
- BrowseComp-$V^3$基准通过构建复杂多模态推理任务,并要求证据公开可搜索,提升了评估的公平性和可重复性。
- 实验表明,现有最优模型在BrowseComp-$V^3$上表现不佳,突显了多模态信息融合和细粒度感知能力上的瓶颈。
📝 摘要(中文)
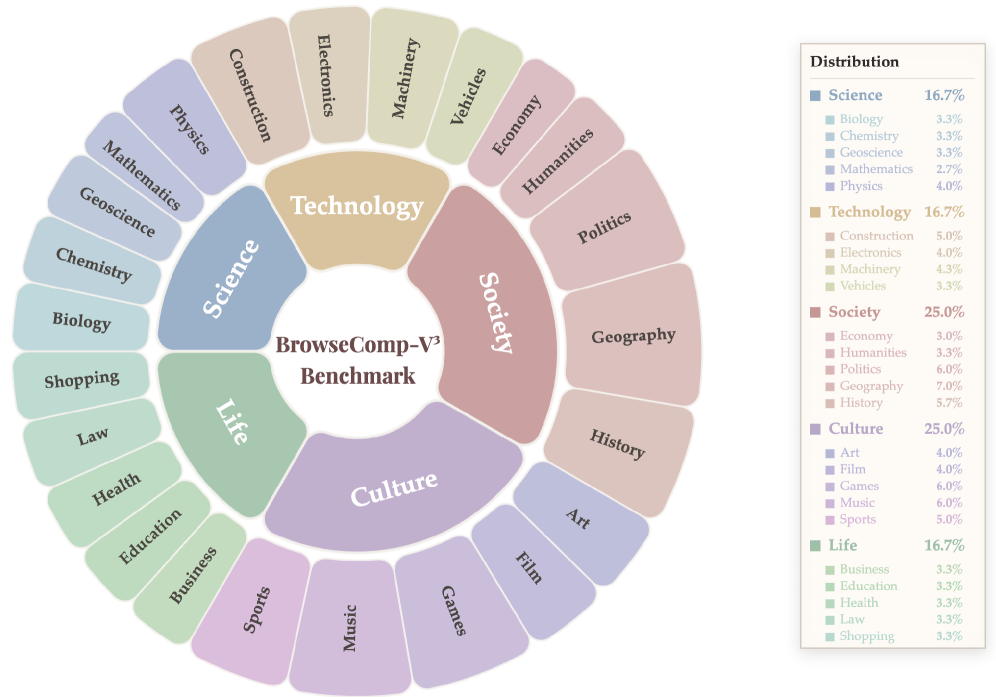
多模态大型语言模型(MLLM)具备日益先进的规划和工具使用能力,正发展成为能够在开放世界环境中执行多模态网页浏览和深度搜索的自主Agent。然而,现有的多模态浏览基准在任务复杂性、证据可访问性和评估粒度方面仍然有限,阻碍了对深度搜索能力的全面和可重复评估。为了解决这些限制,我们引入了BrowseComp-$V^3$,这是一个新颖的基准,包含300个精心策划且具有挑战性的问题,涵盖不同的领域。该基准强调深度、多层次和跨模态的多跳推理,其中关键证据交织在网页内部和跨网页的文本和视觉模态中。所有支持证据都严格要求可公开搜索,以确保公平性和可重复性。除了最终答案的准确性之外,我们还纳入了一种经过专家验证、以子目标驱动的过程评估机制,可以对中间推理行为进行细粒度分析,并系统地表征能力边界。此外,我们提出了OmniSeeker,一个统一的多模态浏览Agent框架,集成了各种网络搜索和视觉感知工具。全面的实验表明,即使是最先进的模型在我们的基准测试中也只能达到36%的准确率,揭示了多模态信息集成和细粒度感知方面的关键瓶颈。我们的结果突出了当前模型能力与现实环境中鲁棒的多模态深度搜索之间的根本差距。
🔬 方法详解
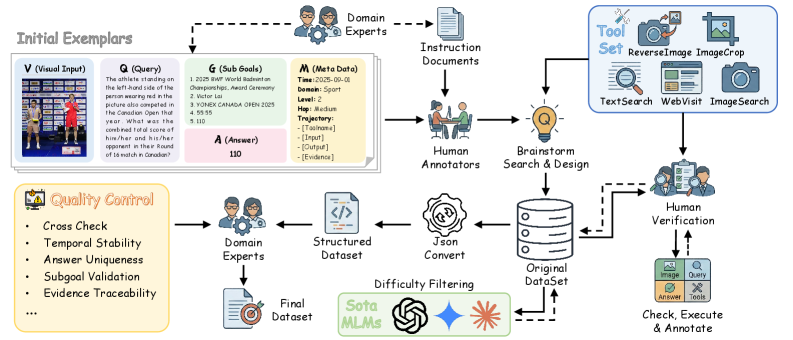
问题定义:现有网页浏览Agent的评测基准存在任务复杂度低、证据不易获取、评估粒度粗糙等问题,难以有效评估Agent在真实开放世界中的深度搜索能力。现有方法难以处理跨模态、多层级、多跳推理任务,且缺乏对Agent中间推理过程的细致评估。
核心思路:BrowseComp-$V^3$基准的核心思路是构建一个更具挑战性、更贴近真实场景的多模态网页浏览任务集,并设计细粒度的评估指标,从而更全面地评估Agent的深度搜索能力。通过要求所有证据公开可搜索,保证了评估的公平性和可重复性。
技术框架:BrowseComp-$V^3$基准包含300个精心设计的问题,涵盖多个领域。每个问题需要Agent进行深度、多层级、跨模态的多跳推理,关键证据分散在网页内部和跨网页的文本和视觉信息中。同时,论文提出了OmniSeeker框架,该框架集成了多种网络搜索和视觉感知工具,旨在提供一个统一的多模态浏览Agent平台。
关键创新:BrowseComp-$V^3$基准的关键创新在于其任务的复杂性和评估的细粒度。与现有基准相比,BrowseComp-$V^3$更强调多模态信息的融合和推理,并引入了子目标驱动的过程评估机制,可以对Agent的中间推理行为进行细致分析。OmniSeeker框架的提出也为多模态浏览Agent的研究提供了一个统一的平台。
关键设计:BrowseComp-$V^3$基准的问题设计注重真实性和挑战性,要求Agent能够处理复杂的网页结构、理解文本和图像信息,并进行多步推理。评估指标包括最终答案的准确率以及中间推理步骤的正确性。OmniSeeker框架的具体参数设置、损失函数和网络结构等技术细节在论文中未详细说明。
🖼️ 关键图片
📊 实验亮点
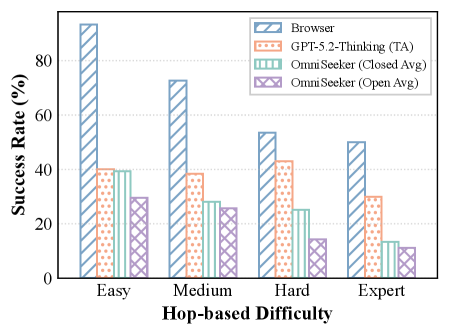
实验结果表明,即使是最先进的多模态大型语言模型在BrowseComp-$V^3$基准上的准确率仅为36%,远低于人类水平。这表明当前模型在多模态信息集成和细粒度感知方面存在显著瓶颈。该基准的提出为未来多模态浏览Agent的研究提供了重要的评估工具和发展方向。
🎯 应用场景
该研究成果可应用于开发更智能的搜索引擎、智能助手和自动化信息采集系统。通过提升Agent的多模态信息理解和推理能力,可以帮助用户更高效地获取所需信息,并解决复杂的问题。未来,该技术有望在医疗诊断、金融分析、教育等领域发挥重要作用。
📄 摘要(原文)
Multimodal large language models (MLLMs), equipped with increasingly advanced planning and tool-use capabilities, are evolving into autonomous agents capable of performing multimodal web browsing and deep search in open-world environments. However, existing benchmarks for multimodal browsing remain limited in task complexity, evidence accessibility, and evaluation granularity, hindering comprehensive and reproducible assessments of deep search capabilities. To address these limitations, we introduce BrowseComp-$V^3$, a novel benchmark consisting of 300 carefully curated and challenging questions spanning diverse domains. The benchmark emphasizes deep, multi-level, and cross-modal multi-hop reasoning, where critical evidence is interleaved across textual and visual modalities within and across web pages. All supporting evidence is strictly required to be publicly searchable, ensuring fairness and reproducibility. Beyond final-answer accuracy, we incorporate an expert-validated, subgoal-driven process evaluation mechanism that enables fine-grained analysis of intermediate reasoning behaviors and systematic characterization of capability boundaries. In addition, we propose OmniSeeker, a unified multimodal browsing agent framework integrating diverse web search and visual perception tools. Comprehensive experiments demonstrate that even state-of-the-art models achieve only 36% accuracy on our benchmark, revealing critical bottlenecks in multimodal information integration and fine-grained perception. Our results highlight a fundamental gap between current model capabilities and robust multimodal deep search in real-world settings.