Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents
作者: Ruihan Yang, Fanghua Ye, Xiang We, Ruoqing Zhao, Kang Luo, Xinbo Xu, Bo Zhao, Ruotian Ma, Shanyi Wang, Zhaopeng Tu, Xiaolong Li, Deqing Yang, Linus
分类: cs.AI, cs.CL
发布日期: 2026-02-13
💡 一句话要点
CogRouter:为LLM Agent设计认知深度自适应框架,提升效率与性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 认知深度自适应 多轮决策 强化学习 ACT-R理论 策略优化 效率提升
📋 核心要点
- 现有LLM Agent在多轮决策任务中采用固定认知模式,无法根据任务需求动态调整认知深度,导致效率低下。
- CogRouter框架通过ACT-R理论指导,设计分层认知水平,并训练Agent动态适应每个步骤的认知深度。
- 实验表明,CogRouter在ALFWorld和ScienceWorld上达到SOTA性能,显著提升成功率并降低token使用量。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被部署为用于多轮决策任务的自主Agent。然而,当前的Agent通常依赖于固定的认知模式:非思考模型产生即时响应,而思考模型则统一地进行深度推理。这种刚性对于长程任务来说效率低下,因为在长程任务中,认知需求在每个步骤中差异很大,有些需要战略规划,有些只需要例行执行。本文介绍CogRouter,一个训练Agent在每个步骤动态调整认知深度的框架。基于ACT-R理论,我们设计了四个层次的认知水平,从本能反应到战略规划。我们的两阶段训练方法包括认知感知监督微调(CoSFT),以灌输稳定的特定水平模式,以及认知感知策略优化(CoPO),用于通过置信度感知优势重加权进行步级信用分配。关键的见解是,适当的认知深度应该最大化结果动作的置信度。在ALFWorld和ScienceWorld上的实验表明,CogRouter实现了最先进的性能和卓越的效率。使用Qwen2.5-7B,它达到了82.3%的成功率,优于GPT-4o (+40.3%)、OpenAI-o3 (+18.3%)和GRPO (+14.0%),同时使用的token减少了62%。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在多轮决策任务中认知深度固定的问题。现有方法要么快速但不深入思考,要么始终进行深度推理,无法根据任务步骤的实际需求调整认知水平,导致效率低下,尤其是在长程任务中。
核心思路:论文的核心思路是让LLM Agent能够根据当前步骤的任务需求,动态地选择合适的认知深度。通过模仿人类的认知过程,Agent可以在需要快速反应的步骤选择较低的认知深度,而在需要战略规划的步骤选择较高的认知深度。这种自适应的认知深度选择能够提高Agent的效率和性能。
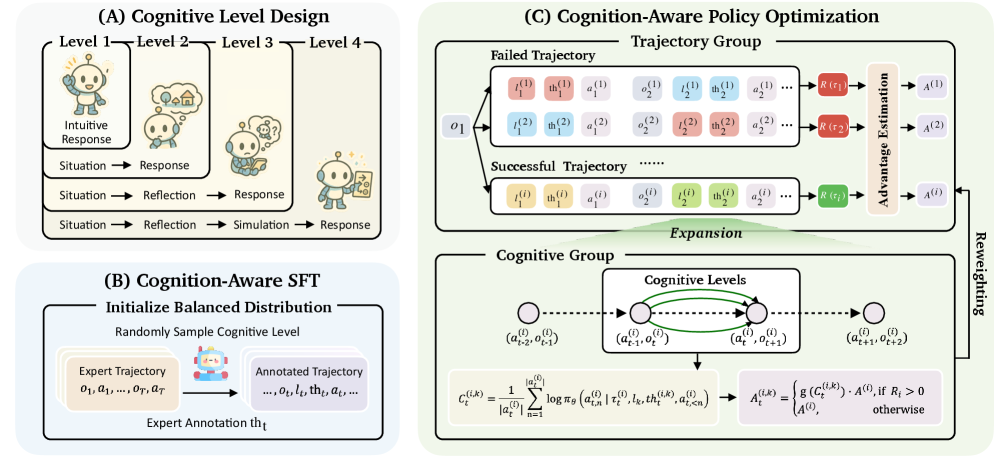
技术框架:CogRouter框架包含两个主要阶段:认知感知监督微调(CoSFT)和认知感知策略优化(CoPO)。CoSFT阶段用于训练Agent掌握不同认知水平下的行为模式。CoPO阶段则通过强化学习,训练Agent在每个步骤选择合适的认知水平。整体流程是,Agent接收环境状态,根据当前状态选择认知水平,然后根据选择的认知水平生成动作,最后环境反馈奖励,Agent根据奖励更新策略。
关键创新:CogRouter的关键创新在于提出了认知深度自适应的概念,并设计了相应的训练框架。与现有方法相比,CogRouter能够让Agent根据任务需求动态调整认知深度,从而提高效率和性能。此外,CoPO阶段采用置信度感知优势重加权,鼓励Agent选择能够产生高置信度动作的认知水平。
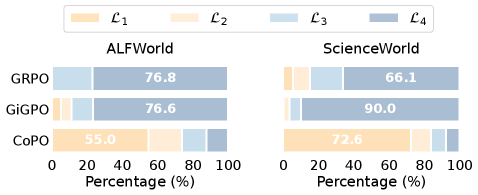
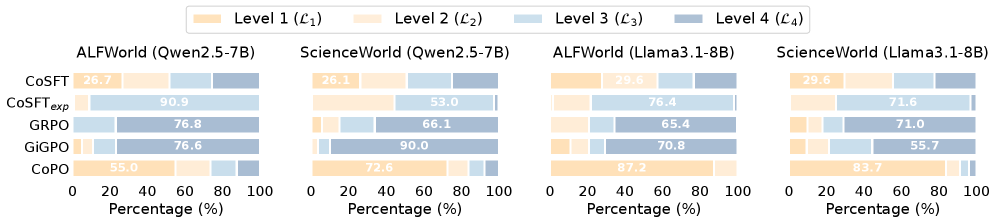
关键设计:CogRouter基于ACT-R理论设计了四个层次的认知水平,分别是:本能反应、习惯性行为、目标导向行为和战略规划。CoSFT阶段使用监督学习,训练Agent在每个认知水平下生成相应的动作。CoPO阶段使用强化学习,目标是最大化累积奖励。置信度感知优势重加权的具体实现方式是,将优势函数乘以一个与动作置信度相关的权重,从而鼓励Agent选择能够产生高置信度动作的认知水平。具体损失函数未知。
🖼️ 关键图片
📊 实验亮点
CogRouter在ALFWorld和ScienceWorld两个任务上都取得了显著的性能提升。使用Qwen2.5-7B模型,CogRouter在两个任务上都达到了SOTA性能,成功率达到82.3%,超过了GPT-4o (+40.3%)、OpenAI-o3 (+18.3%)和GRPO (+14.0%)等强大的基线模型,同时使用的token数量减少了62%,表明其具有更高的效率。
🎯 应用场景
CogRouter框架具有广泛的应用前景,可应用于各种需要多轮决策的Agent任务,例如机器人导航、游戏AI、智能客服等。通过动态调整认知深度,Agent可以更高效地完成任务,并更好地适应复杂多变的环境。该研究有助于提升LLM Agent的智能化水平,使其更接近人类的认知能力。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed as autonomous agents for multi-turn decision-making tasks. However, current agents typically rely on fixed cognitive patterns: non-thinking models generate immediate responses, while thinking models engage in deep reasoning uniformly. This rigidity is inefficient for long-horizon tasks, where cognitive demands vary significantly from step to step, with some requiring strategic planning and others only routine execution. In this paper, we introduce CogRouter, a framework that trains agents to dynamically adapt cognitive depth at each step. Grounded in ACT-R theory, we design four hierarchical cognitive levels ranging from instinctive responses to strategic planning. Our two-stage training approach includes Cognition-aware Supervised Fine-tuning (CoSFT) to instill stable level-specific patterns, and Cognition-aware Policy Optimization (CoPO) for step-level credit assignment via confidence-aware advantage reweighting. The key insight is that appropriate cognitive depth should maximize the confidence of the resulting action. Experiments on ALFWorld and ScienceWorld demonstrate that CogRouter achieves state-of-the-art performance with superior efficiency. With Qwen2.5-7B, it reaches an 82.3% success rate, outperforming GPT-4o (+40.3%), OpenAI-o3 (+18.3%), and GRPO (+14.0%), while using 62% fewer tokens.