Artic: AI-oriented Real-time Communication for MLLM Video Assistant
作者: Jiangkai Wu, Zhiyuan Ren, Junquan Zhong, Liming Liu, Xinggong Zhang
分类: cs.NI, cs.AI, cs.HC, cs.MM
发布日期: 2026-02-13
🔗 代码/项目: GITHUB
💡 一句话要点
Artic:面向MLLM视频助手的AI实时通信框架,提升准确率并降低延迟
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI视频助手 实时通信 多模态大语言模型 自适应码率 上下文感知流媒体
📋 核心要点
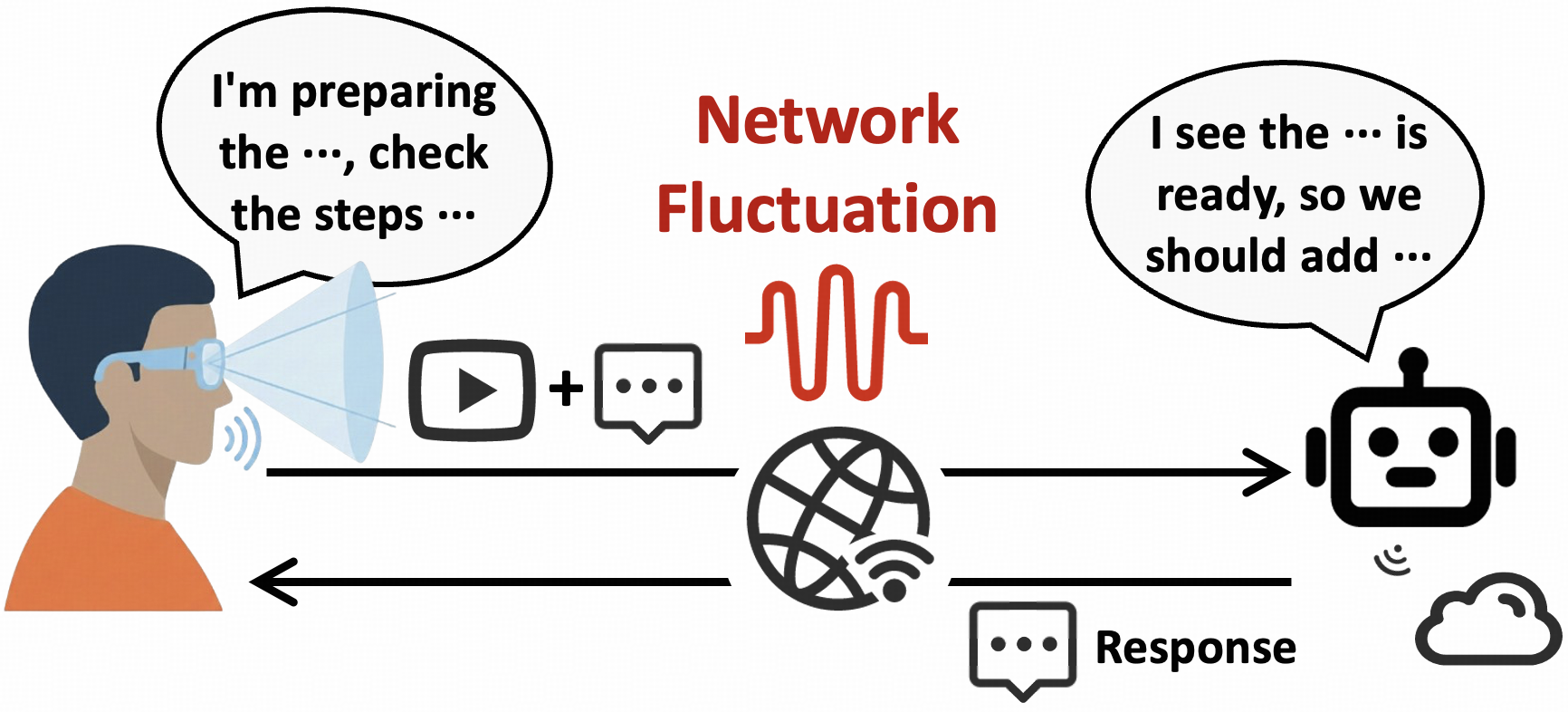
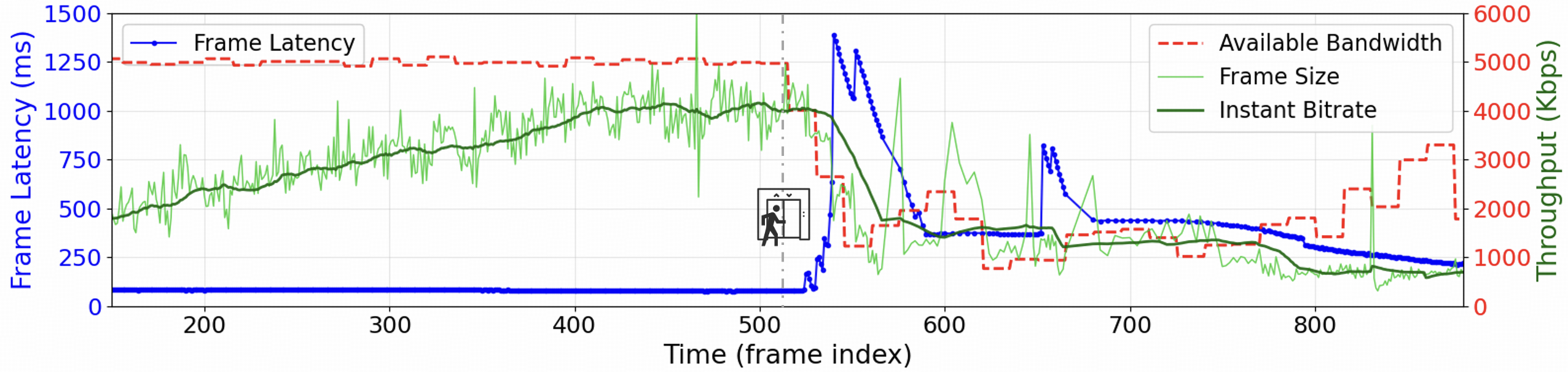
- 现有RTC框架在AI视频助手场景下存在不足,无法满足MLLM对QoE的需求,导致延迟增加和准确率下降。
- Artic通过响应能力感知的自适应码率、上下文感知流媒体等技术,优化视频传输,提升MLLM的理解准确率。
- 实验表明,Artic相比现有方法,显著提高了MLLM的准确率(15.12%)并降低了延迟(135.31毫秒)。
📝 摘要(中文)
AI视频助手作为实时通信(RTC)的新范式正在兴起,其中一方是部署在云端的多模态大型语言模型(MLLM)。这使得人与AI之间的交互更加直观,类似于与真人聊天。然而,当前的RTC框架与AI视频助手之间存在根本性的不匹配,源于体验质量(QoE)的巨大转变和更具挑战性的网络环境。在我们的生产原型上的测量也证实了当前RTC的不足,导致延迟峰值和准确率下降。为了解决这些挑战,我们提出了Artic,一个面向MLLM视频助手的AI实时通信框架,探索从“人类观看视频”到“AI理解视频”的转变。具体来说,Artic提出了:(1)响应能力感知的自适应码率,利用MLLM准确率饱和度来主动限制码率,保留带宽余量以吸收未来波动,从而减少延迟;(2)零开销的上下文感知流媒体,将有限的码率分配给对响应最重要的区域,即使在超低码率下也能保持准确率;(3)退化视频理解基准,这是第一个评估RTC引起的视频退化如何影响MLLM准确率的基准。使用真实上行链路跟踪的原型实验表明,与现有方法相比,Artic显著提高了15.12%的准确率,并减少了135.31毫秒的延迟。我们将在https://github.com/pku-netvideo/DeViBench发布基准和代码。
🔬 方法详解
问题定义:论文旨在解决在AI视频助手场景下,现有实时通信(RTC)框架无法有效支持多模态大型语言模型(MLLM)的问题。现有RTC框架主要为“人观看视频”设计,而AI视频助手需要“AI理解视频”,这导致了QoE需求的根本性转变。现有方法在网络条件不佳时,容易出现延迟峰值和MLLM理解准确率下降的问题。
核心思路:Artic的核心思路是设计一个AI导向的RTC框架,充分利用MLLM的特性来优化视频传输。它通过感知MLLM的响应能力,自适应地调整码率,并优先传输对MLLM理解最重要的视频区域,从而在有限的带宽下最大化MLLM的准确率,并降低延迟。
技术框架:Artic框架包含三个主要组成部分:(1) 响应能力感知的自适应码率(Response Capability-aware Adaptive Bitrate):根据MLLM的准确率饱和度动态调整视频码率,预留带宽应对波动。(2) 零开销的上下文感知流媒体(Zero-overhead Context-aware Streaming):识别并优先传输对MLLM响应至关重要的视频区域。(3) 退化视频理解基准(Degraded Video Understanding Benchmark):用于评估不同视频质量下MLLM的理解能力。
关键创新:Artic的关键创新在于其AI导向的设计理念,它将MLLM的理解能力纳入RTC框架的考虑范围,并根据MLLM的特性进行优化。与传统RTC框架不同,Artic不是简单地追求高视频质量,而是关注如何以最小的带宽代价,最大化MLLM的理解准确率。此外,提出的退化视频理解基准,为评估RTC对MLLM性能的影响提供了新的工具。
关键设计:响应能力感知的自适应码率通过监控MLLM的准确率变化来判断是否达到饱和状态,并相应地降低码率。上下文感知流媒体可能采用目标检测、显著性检测等技术来识别重要区域,并使用不同的编码参数进行处理。具体的损失函数和网络结构细节在论文中可能未详细说明,需要参考相关代码或后续研究。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Artic框架在实际网络环境中能够显著提升MLLM的准确率并降低延迟。与现有方法相比,Artic将MLLM的准确率提高了15.12%,并将延迟降低了135.31毫秒。这些数据表明Artic在AI视频助手场景下具有显著的优势。
🎯 应用场景
Artic框架可应用于各种AI视频助手场景,例如智能客服、远程医疗、智能安防等。通过优化视频传输,提升AI的理解能力,可以改善用户体验,提高工作效率。未来,该研究可以扩展到其他类型的AI应用,例如自动驾驶、机器人导航等,为AI在复杂环境中的应用提供更好的支持。
📄 摘要(原文)
AI Video Assistant emerges as a new paradigm for Real-time Communication (RTC), where one peer is a Multimodal Large Language Model (MLLM) deployed in the cloud. This makes interaction between humans and AI more intuitive, akin to chatting with a real person. However, a fundamental mismatch exists between current RTC frameworks and AI Video Assistants, stemming from the drastic shift in Quality of Experience (QoE) and more challenging networks. Measurements on our production prototype also confirm that current RTC fails, causing latency spikes and accuracy drops. To address these challenges, we propose Artic, an AI-oriented RTC framework for MLLM Video Assistants, exploring the shift from "humans watching video" to "AI understanding video." Specifically, Artic proposes: (1) Response Capability-aware Adaptive Bitrate, which utilizes MLLM accuracy saturation to proactively cap bitrate, reserving bandwidth headroom to absorb future fluctuations for latency reduction; (2) Zero-overhead Context-aware Streaming, which allocates limited bitrate to regions most important for the response, maintaining accuracy even under ultra-low bitrates; and (3) Degraded Video Understanding Benchmark, the first benchmark evaluating how RTC-induced video degradation affects MLLM accuracy. Prototype experiments using real-world uplink traces show that compared with existing methods, Artic significantly improves accuracy by 15.12% and reduces latency by 135.31 ms. We will release the benchmark and codes at https://github.com/pku-netvideo/DeViBench.