AttentionRetriever: Attention Layers are Secretly Long Document Retrievers
作者: David Jiahao Fu, Lam Thanh Do, Jiayu Li, Kevin Chen-Chuan Chang
分类: cs.IR, cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出AttentionRetriever,利用注意力机制进行高效长文档检索。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文档检索 注意力机制 检索增强生成 上下文感知 实体检索
📋 核心要点
- 现有检索模型在处理长文档时,缺乏对上下文的有效感知,难以捕捉文档内的因果依赖关系,检索范围也难以确定。
- AttentionRetriever利用注意力机制和基于实体的检索,构建上下文感知的长文档嵌入,从而确定合适的检索范围。
- 实验结果表明,AttentionRetriever在长文档检索任务上显著优于现有模型,同时保持了较高的检索效率。
📝 摘要(中文)
检索增强生成(RAG)已被广泛采用,以帮助大型语言模型(LLM)处理涉及长文档的任务。然而,现有的检索模型并非为长文档检索而设计,无法解决长文档检索的几个关键挑战,包括上下文感知、因果依赖和检索范围。本文提出了AttentionRetriever,一种新颖的长文档检索模型,它利用注意力机制和基于实体的检索来构建长文档的上下文感知嵌入,并确定检索范围。通过大量的实验,我们发现AttentionRetriever能够在长文档检索数据集上大幅优于现有的检索模型,同时保持与密集检索模型一样高效。
🔬 方法详解
问题定义:现有检索模型在长文档检索任务中表现不佳,主要痛点在于无法有效捕捉长文档中的上下文信息、因果依赖关系,以及难以确定合适的检索范围。这导致检索结果的准确性和相关性降低。
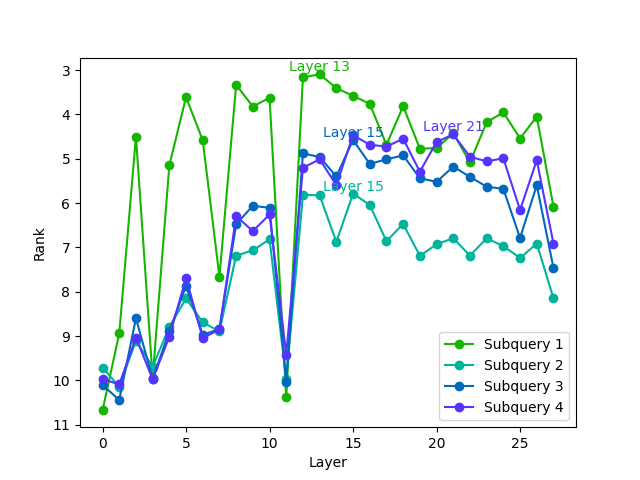
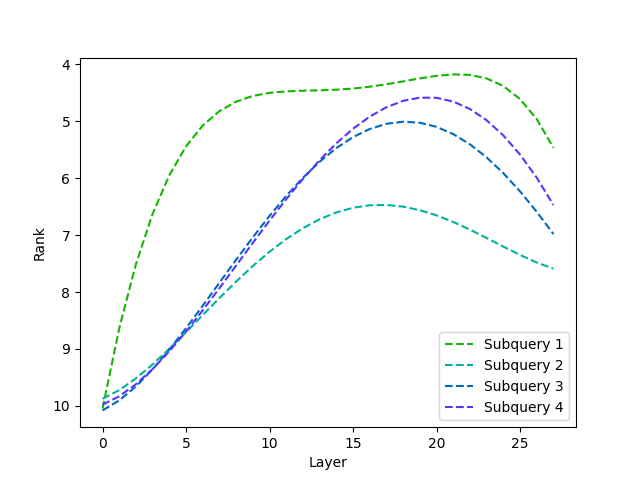
核心思路:AttentionRetriever的核心思路是利用注意力机制来学习长文档的上下文感知嵌入表示。通过注意力机制,模型可以关注文档中与查询相关的关键部分,从而更好地理解文档的语义信息。同时,结合基于实体的检索,可以更精确地确定检索范围,提高检索效率。
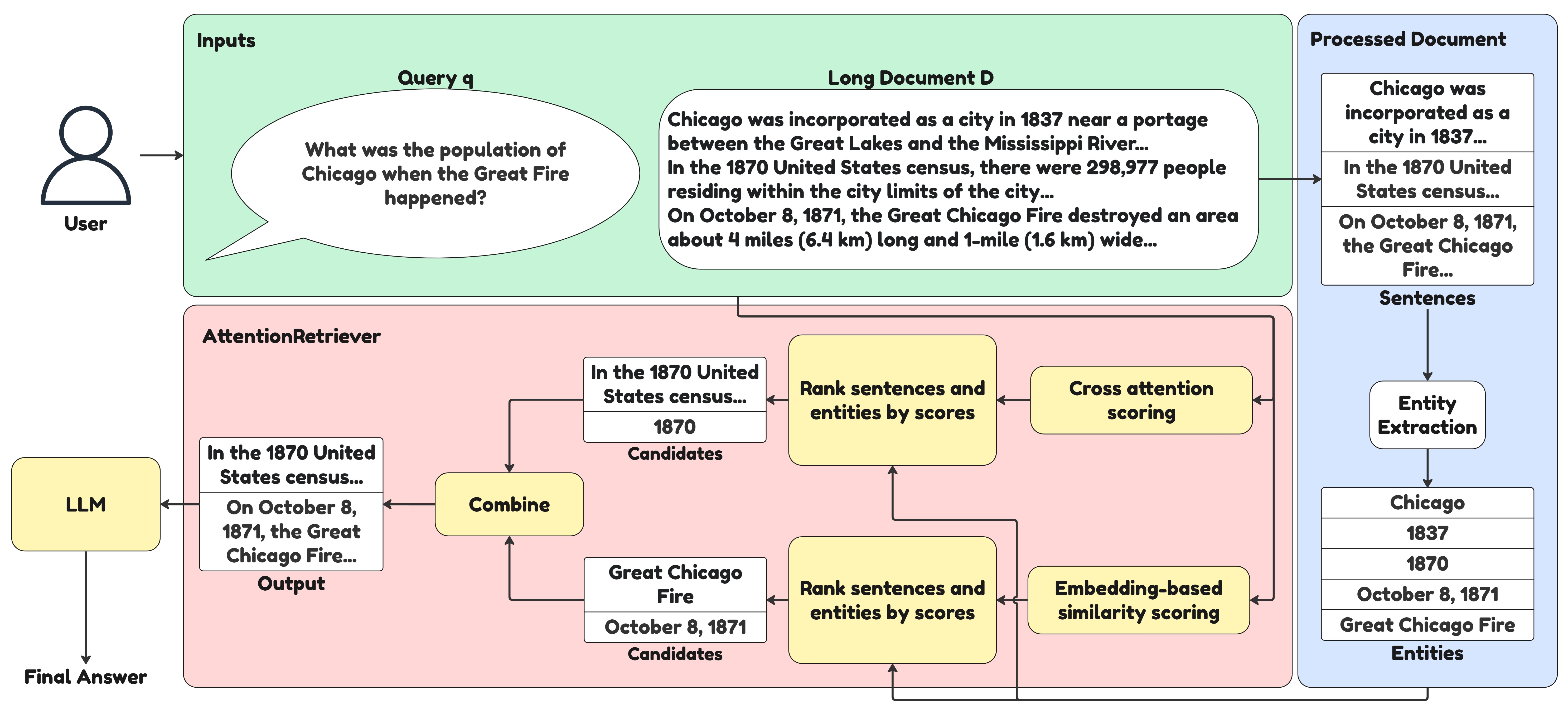
技术框架:AttentionRetriever的整体框架包括以下几个主要模块:1) 文档编码器:使用注意力机制对长文档进行编码,生成上下文感知的文档嵌入;2) 查询编码器:对查询进行编码,生成查询嵌入;3) 实体识别模块:识别文档中的实体信息,用于辅助确定检索范围;4) 检索模块:基于文档嵌入和查询嵌入,进行相似度计算,并返回最相关的文档。
关键创新:AttentionRetriever的关键创新在于将注意力机制应用于长文档检索,从而能够更好地捕捉文档的上下文信息。与传统的密集检索模型相比,AttentionRetriever能够更有效地处理长文档中的复杂语义关系。此外,结合基于实体的检索,可以进一步提高检索的准确性和效率。
关键设计:AttentionRetriever使用了Transformer架构作为文档编码器和查询编码器的基础。在注意力机制方面,采用了多头注意力机制,以捕捉不同角度的语义信息。损失函数方面,使用了对比学习损失,以鼓励相似的文档和查询具有更接近的嵌入表示。实体识别模块可以使用预训练的命名实体识别模型,也可以进行端到端的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AttentionRetriever在长文档检索数据集上显著优于现有的检索模型。具体而言,AttentionRetriever在多个数据集上取得了超过10%的性能提升,同时保持了与密集检索模型相当的检索效率。这些结果表明,AttentionRetriever是一种有效且高效的长文档检索模型。
🎯 应用场景
AttentionRetriever可应用于各种需要处理长文档的场景,例如法律文档检索、医学文献检索、金融报告分析等。该模型能够提高检索的准确性和效率,帮助用户快速找到所需信息,具有重要的实际应用价值和潜力。未来,可以进一步探索AttentionRetriever在其他领域的应用,例如知识图谱构建、问答系统等。
📄 摘要(原文)
Retrieval augmented generation (RAG) has been widely adopted to help Large Language Models (LLMs) to process tasks involving long documents. However, existing retrieval models are not designed for long document retrieval and fail to address several key challenges of long document retrieval, including context-awareness, causal dependence, and scope of retrieval. In this paper, we proposed AttentionRetriever, a novel long document retrieval model that leverages attention mechanism and entity-based retrieval to build context-aware embeddings for long document and determine the scope of retrieval. With extensive experiments, we found AttentionRetriever is able to outperform existing retrieval models on long document retrieval datasets by a large margin while remaining as efficient as dense retrieval models.