Think like a Scientist: Physics-guided LLM Agent for Equation Discovery
作者: Jianke Yang, Ohm Venkatachalam, Mohammad Kianezhad, Sharvaree Vadgama, Rose Yu
分类: cs.AI, cs.LG
发布日期: 2026-02-12
💡 一句话要点
KeplerAgent:基于物理先验知识的LLM智能体,用于符号方程发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 符号方程发现 大型语言模型 物理先验知识 智能体 符号回归
📋 核心要点
- 现有基于LLM的方程发现方法缺乏对物理规律的建模,直接从数据猜测方程,忽略了科学家常用的推理过程。
- KeplerAgent通过模拟科学家的推理过程,首先推断物理属性,然后将其作为先验知识来约束候选方程的搜索空间。
- 实验结果表明,KeplerAgent在符号精度和抗噪声能力方面均优于现有的LLM和传统方法。
📝 摘要(中文)
本研究旨在通过可解释的符号公式来解释观测到的现象,这是科学研究的一个基本目标。 近年来,大型语言模型(LLM)凭借其广泛的领域知识和强大的推理能力,已成为符号方程发现领域中很有前途的工具。 然而,大多数现有的基于LLM的系统试图直接从数据中猜测方程,而没有模拟科学家通常遵循的多步骤推理过程:首先推断物理性质(例如对称性),然后使用这些性质作为先验来限制候选方程的空间。 我们引入了KeplerAgent,这是一个agent框架,它明确地遵循了这种科学的推理过程。 该agent协调基于物理的工具来提取中间结构,并使用这些结果来配置符号回归引擎(例如PySINDy和PySR),包括它们的函数库和结构约束。 在一系列物理方程基准测试中,与LLM和传统基线相比,KeplerAgent实现了更高的符号精度和对噪声数据的更强的鲁棒性。
🔬 方法详解
问题定义:现有的基于LLM的符号方程发现方法主要依赖于直接从数据中学习,缺乏对物理规律的显式建模。这种方法忽略了科学家在发现方程时通常遵循的推理过程,例如首先推断物理属性(如对称性),然后利用这些属性来约束方程的搜索空间。因此,现有方法在精度和鲁棒性方面存在局限性,尤其是在处理噪声数据时。
核心思路:KeplerAgent的核心思路是模拟科学家的推理过程,将物理知识融入到方程发现的过程中。具体来说,KeplerAgent首先利用物理工具提取数据中的中间结构,例如对称性等物理属性。然后,将这些物理属性作为先验知识,用于配置符号回归引擎,从而限制候选方程的搜索空间,提高方程发现的效率和准确性。
技术框架:KeplerAgent采用agentic框架,包含以下主要模块:1) 物理属性推断模块:利用物理工具(具体工具未知)从数据中提取物理属性,例如对称性、守恒律等。2) 符号回归引擎配置模块:根据推断出的物理属性,配置符号回归引擎(如PySINDy和PySR)的参数,包括函数库和结构约束。3) 符号回归模块:利用配置好的符号回归引擎,在约束条件下搜索候选方程。4) 评估模块:评估候选方程的质量,并选择最优方程。整个流程是一个迭代的过程,可以不断优化方程的发现结果。
关键创新:KeplerAgent的关键创新在于将物理知识显式地融入到LLM的方程发现过程中。与现有方法相比,KeplerAgent不是直接从数据中猜测方程,而是首先利用物理工具提取数据中的中间结构,然后将这些结构作为先验知识来指导方程的搜索。这种方法更符合科学家的思维方式,可以显著提高方程发现的效率和准确性。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,可以推断出,物理属性推断模块可能需要设计特定的算法或模型来提取不同的物理属性。符号回归引擎配置模块需要根据不同的物理属性,选择合适的函数库和结构约束。评估模块可能需要设计特定的指标来评估候选方程的物理合理性。
🖼️ 关键图片
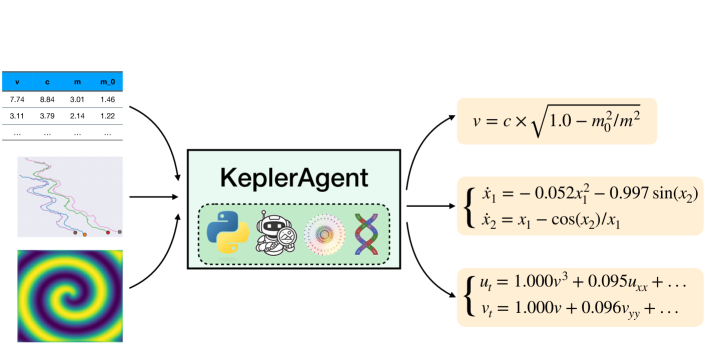
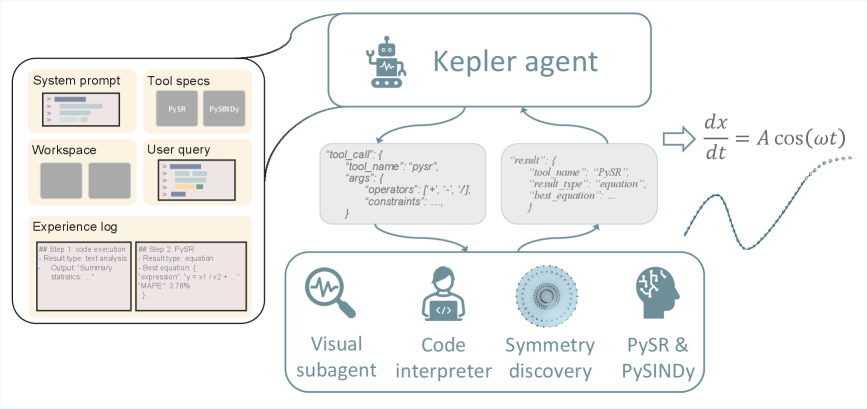
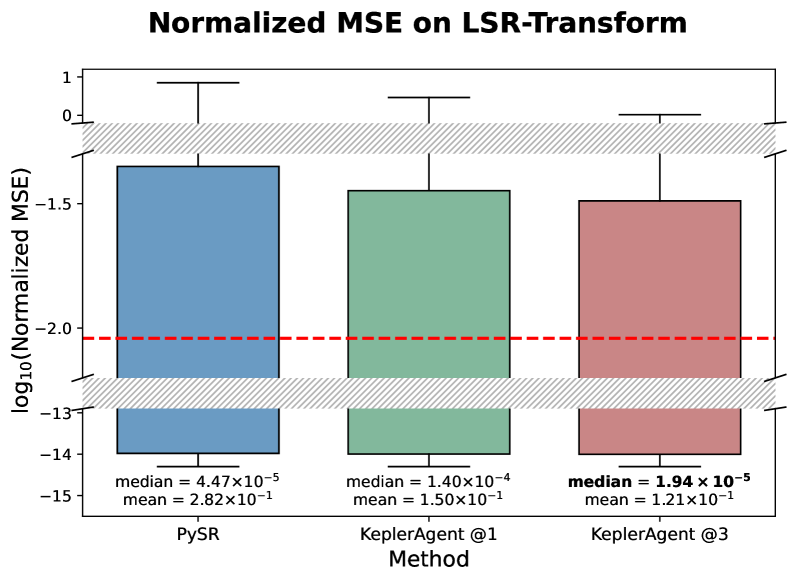
📊 实验亮点
KeplerAgent在多个物理方程基准测试中取得了显著的性能提升。与现有的LLM和传统方法相比,KeplerAgent在符号精度和抗噪声能力方面均表现出更强的优势。具体的性能数据和提升幅度在论文中进行了详细的展示,表明了KeplerAgent的有效性和优越性。
🎯 应用场景
KeplerAgent具有广泛的应用前景,可用于物理学、化学、生物学等多个科学领域。它可以帮助科学家从实验数据中发现新的物理规律和数学模型,加速科学研究的进程。此外,KeplerAgent还可以应用于工程领域,例如控制系统设计、材料科学等,帮助工程师优化产品设计和性能。
📄 摘要(原文)
Explaining observed phenomena through symbolic, interpretable formulas is a fundamental goal of science. Recently, large language models (LLMs) have emerged as promising tools for symbolic equation discovery, owing to their broad domain knowledge and strong reasoning capabilities. However, most existing LLM-based systems try to guess equations directly from data, without modeling the multi-step reasoning process that scientists often follow: first inferring physical properties such as symmetries, then using these as priors to restrict the space of candidate equations. We introduce KeplerAgent, an agentic framework that explicitly follows this scientific reasoning process. The agent coordinates physics-based tools to extract intermediate structure and uses these results to configure symbolic regression engines such as PySINDy and PySR, including their function libraries and structural constraints. Across a suite of physical equation benchmarks, KeplerAgent achieves substantially higher symbolic accuracy and greater robustness to noisy data than both LLM and traditional baselines.