SAM3-LiteText: An Anatomical Study of the SAM3 Text Encoder for Efficient Vision-Language Segmentation
作者: Chengxi Zeng, Yuxuan Jiang, Ge Gao, Shuai Wang, Duolikun Danier, Bin Zhu, Stevan Rudinac, David Bull, Fan Zhang
分类: cs.AI
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出SAM3-LiteText,通过知识蒸馏压缩文本编码器,提升视觉-语言分割效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言分割 知识蒸馏 模型压缩 轻量级模型 MobileCLIP
📋 核心要点
- 现有视觉-语言分割模型依赖大型文本编码器,造成计算和内存开销过大,效率低下。
- SAM3-LiteText通过知识蒸馏,将大型文本编码器替换为轻量级的MobileCLIP学生模型。
- 实验表明,SAM3-LiteText在保持分割性能的同时,显著降低了文本编码器的参数量和内存占用。
📝 摘要(中文)
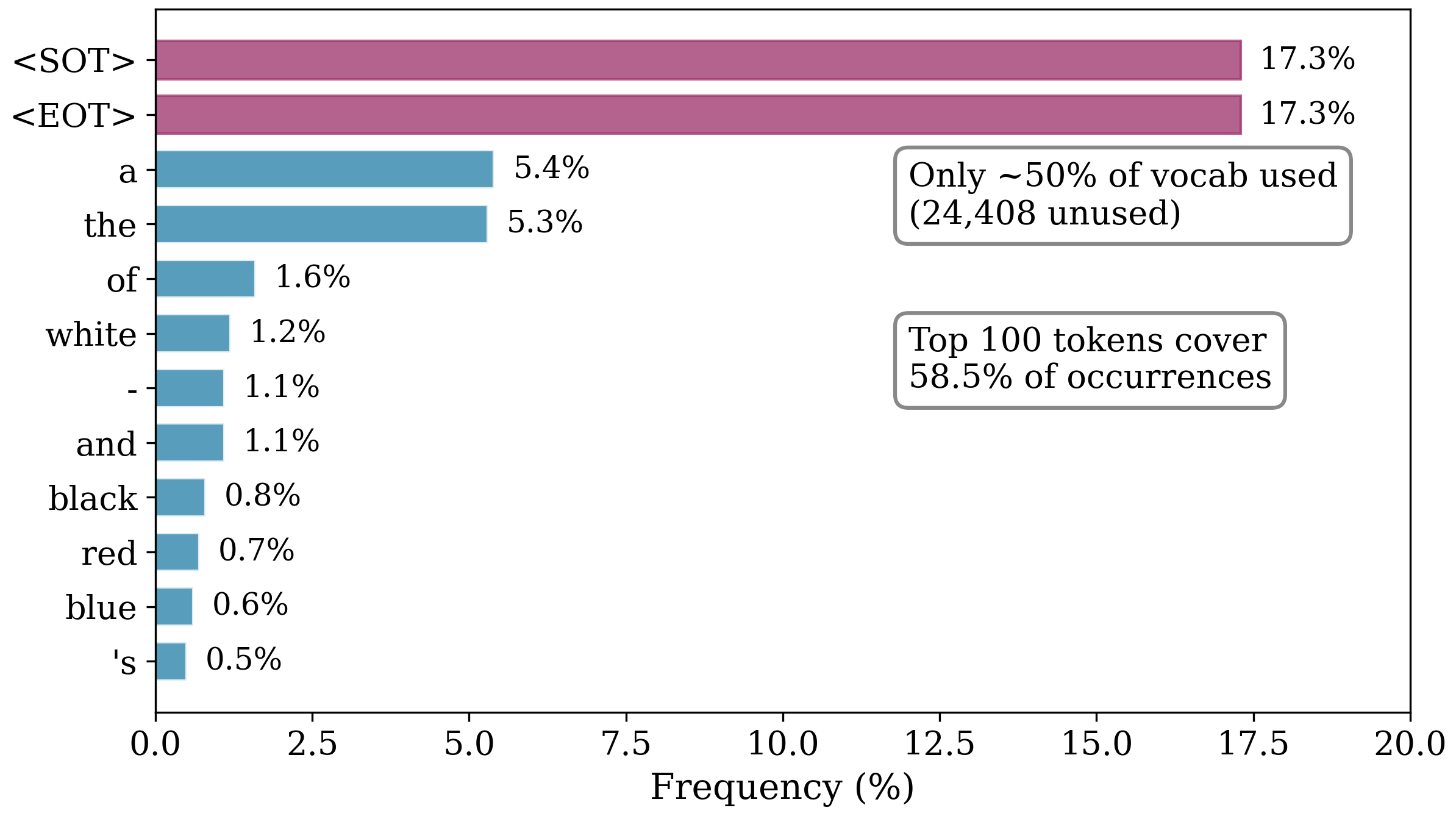
视觉-语言分割模型(如SAM3)能够实现灵活的、由提示驱动的视觉 grounding,但继承了原本为开放式语言理解设计的大型通用文本编码器。实际上,分割提示通常是短的、结构化的且语义受限的,导致文本编码器的容量过剩,以及持续的计算和内存开销。本文对视觉-语言分割中的文本提示进行大规模的解剖分析,涵盖多个基准测试中的404,796个真实提示。分析表明存在严重的冗余:大多数上下文窗口未被充分利用,词汇使用高度稀疏,并且文本嵌入位于低维流形上,尽管表示是高维的。受这些发现的启发,我们提出了SAM3-LiteText,一个轻量级的文本编码框架,它用一个紧凑的MobileCLIP学生模型替换了原始的SAM3文本编码器,并通过知识蒸馏进行优化。在图像和视频分割基准测试上的大量实验表明,SAM3-LiteText将文本编码器参数减少了高达88%,显著减少了静态内存占用,同时保持了与原始模型相当的分割性能。
🔬 方法详解
问题定义:现有视觉-语言分割模型,如SAM3,使用了为通用语言理解设计的大型文本编码器。然而,分割任务的文本提示通常较短、结构化且语义受限,导致文本编码器容量过剩,计算和内存开销巨大。现有方法未能充分利用文本提示的特性进行优化。
核心思路:核心思路是通过知识蒸馏,将大型文本编码器的知识迁移到轻量级的学生模型(MobileCLIP)中。这样可以在保持分割性能的同时,显著降低文本编码器的参数量和计算复杂度。通过分析大量真实分割提示,发现文本嵌入存在冗余,为知识蒸馏提供了理论依据。
技术框架:SAM3-LiteText框架主要包含两个部分:教师模型(原始SAM3的文本编码器)和学生模型(MobileCLIP)。首先,使用教师模型对大量的分割提示进行编码,得到文本嵌入。然后,使用知识蒸馏技术,训练学生模型,使其能够生成与教师模型相似的文本嵌入。最后,将训练好的学生模型替换原始SAM3的文本编码器。
关键创新:关键创新在于针对视觉-语言分割任务的文本提示特性,设计了一种轻量级的文本编码框架。该框架通过知识蒸馏,有效地压缩了文本编码器,降低了计算和内存开销,同时保持了分割性能。此外,对大量真实分割提示的解剖分析,为模型设计提供了理论支撑。
关键设计:使用MobileCLIP作为学生模型,因为它具有较小的参数量和较高的效率。知识蒸馏过程中,使用了多种损失函数,包括文本嵌入的相似性损失和分割性能损失,以保证学生模型能够学习到教师模型的关键知识。具体参数设置未知,论文中可能包含更多细节。
🖼️ 关键图片

📊 实验亮点
SAM3-LiteText在图像和视频分割基准测试中表现出色,将文本编码器参数减少了高达88%,显著降低了静态内存占用,同时保持了与原始SAM3模型相当的分割性能。具体性能数据未知,但参数量的大幅减少是显著的优势。
🎯 应用场景
SAM3-LiteText可应用于各种需要高效视觉-语言分割的场景,例如移动设备上的图像编辑、实时视频分析、机器人导航等。该方法降低了模型部署的硬件要求,使其能够在资源受限的环境中运行,具有广泛的应用前景。
📄 摘要(原文)
Vision-language segmentation models such as SAM3 enable flexible, prompt-driven visual grounding, but inherit large, general-purpose text encoders originally designed for open-ended language understanding. In practice, segmentation prompts are short, structured, and semantically constrained, leading to substantial over-provisioning in text encoder capacity and persistent computational and memory overhead. In this paper, we perform a large-scale anatomical analysis of text prompting in vision-language segmentation, covering 404,796 real prompts across multiple benchmarks. Our analysis reveals severe redundancy: most context windows are underutilized, vocabulary usage is highly sparse, and text embeddings lie on low-dimensional manifold despite high-dimensional representations. Motivated by these findings, we propose SAM3-LiteText, a lightweight text encoding framework that replaces the original SAM3 text encoder with a compact MobileCLIP student that is optimized by knowledge distillation. Extensive experiments on image and video segmentation benchmarks show that SAM3-LiteText reduces text encoder parameters by up to 88%, substantially reducing static memory footprint, while maintaining segmentation performance comparable to the original model. Code: https://github.com/SimonZeng7108/efficientsam3/tree/sam3_litetext.