Pedagogically-Inspired Data Synthesis for Language Model Knowledge Distillation
作者: Bowei He, Yankai Chen, Xiaokun Zhang, Linghe Kong, Philip S. Yu, Xue Liu, Chen Ma
分类: cs.AI, cs.CL
发布日期: 2026-02-12
备注: Accepted by ICLR 2026
💡 一句话要点
提出IOA框架,通过教学启发的数据合成方法提升语言模型知识蒸馏效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 语言模型 教学启发 数据合成 模型压缩
📋 核心要点
- 现有知识蒸馏方法缺乏教学意识,将知识转移视为一次性任务,忽略了系统性的学习过程。
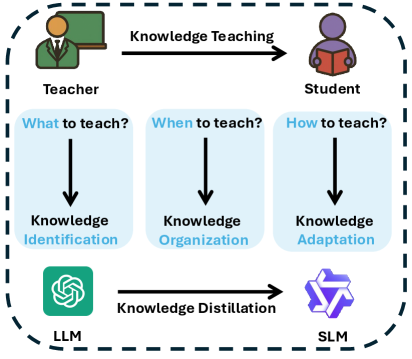
- 提出IOA框架,通过知识识别、组织和适配三个阶段,模拟教学过程,提升知识蒸馏效果。
- 实验表明,IOA框架在复杂推理任务上显著优于现有方法,并在参数量较小的情况下保持了较高的性能。
📝 摘要(中文)
本文提出了一种受教学启发的LLM知识蒸馏框架,旨在解决当前合成数据蒸馏方法缺乏教学意识的问题,将知识转移视为一个系统性的学习过程。该框架包含知识识别器(Knowledge Identifier)、组织器(Organizer)和适配器(Adapter)三个阶段,系统性地识别学生模型的知识缺陷,通过渐进式课程组织知识传递,并调整表征以匹配学生模型的认知能力。该方法融合了Bloom的掌握学习原则和维果茨基的最近发展区理论,创建了一个动态的蒸馏过程。实验结果表明,IOA在LLaMA-3.1/3.2和Qwen2.5等学生模型上取得了显著改进,在DollyEval上保留了教师模型94.7%的性能,同时参数量小于教师模型的1/10。该框架在复杂的推理任务中表现出色,在MATH和HumanEval上分别比最先进的基线提高了19.2%和22.3%。
🔬 方法详解
问题定义:当前知识蒸馏方法主要依赖于大规模语言模型(LLM)生成合成数据,然后训练较小的学生模型。然而,这些方法通常缺乏教学意识,没有针对学生模型的知识缺陷进行针对性教学,导致蒸馏效果不佳。现有方法将知识转移视为一次性的数据合成和训练任务,忽略了学习是一个循序渐进的过程。
核心思路:本文的核心思路是借鉴教育学原理,设计一个更有效的知识蒸馏框架。该框架模拟了教师如何根据学生的知识水平,有针对性地组织和呈现知识的过程。通过识别学生模型的知识薄弱环节,并以渐进的方式引入新的知识,从而提高学生模型的学习效率和性能。
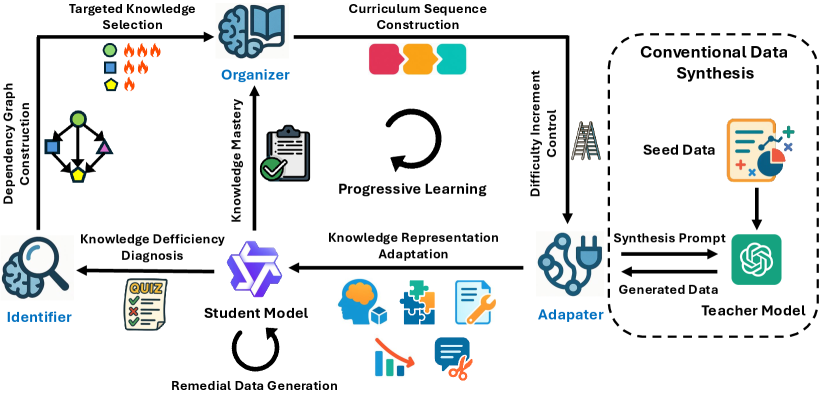
技术框架:IOA框架包含三个主要阶段:知识识别器(Knowledge Identifier)、组织器(Organizer)和适配器(Adapter)。首先,知识识别器用于识别学生模型在哪些知识点上存在不足。然后,组织器根据学生模型的知识水平,设计一个渐进式的学习课程,逐步引入新的知识。最后,适配器用于调整知识的表征方式,使其更适合学生模型的认知能力。
关键创新:IOA框架的关键创新在于其教学启发的设计理念。它将知识蒸馏视为一个动态的学习过程,而不是一个静态的数据合成和训练任务。通过融合Bloom的掌握学习原则和维果茨基的最近发展区理论,IOA框架能够更有效地引导学生模型学习,并取得更好的蒸馏效果。
关键设计:在知识识别阶段,可以使用各种方法来评估学生模型的知识水平,例如,可以通过测试学生模型在不同任务上的表现来识别其知识缺陷。在知识组织阶段,可以根据知识点的难度和学生模型的掌握程度,设计一个渐进式的学习课程。在知识适配阶段,可以使用各种技术来调整知识的表征方式,例如,可以使用知识图谱来表示知识之间的关系,或者可以使用对比学习来增强知识的区分度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IOA框架在LLaMA-3.1/3.2和Qwen2.5等学生模型上取得了显著改进。在DollyEval基准测试中,学生模型保留了教师模型94.7%的性能,同时参数量小于教师模型的1/10。在复杂的推理任务中,IOA框架在MATH和HumanEval上分别比最先进的基线提高了19.2%和22.3%。
🎯 应用场景
该研究成果可广泛应用于各种需要将大型语言模型的知识迁移到小型模型的场景,例如移动设备上的自然语言处理、边缘计算环境下的智能应用、以及资源受限的嵌入式系统。通过高效的知识蒸馏,可以降低模型部署成本,提高推理速度,并促进人工智能技术的普及。
📄 摘要(原文)
Knowledge distillation from Large Language Models (LLMs) to smaller models has emerged as a critical technique for deploying efficient AI systems. However, current methods for distillation via synthetic data lack pedagogical awareness, treating knowledge transfer as a one-off data synthesis and training task rather than a systematic learning process. In this paper, we propose a novel pedagogically-inspired framework for LLM knowledge distillation that draws from fundamental educational principles. Our approach introduces a three-stage pipeline -- Knowledge Identifier, Organizer, and Adapter (IOA) -- that systematically identifies knowledge deficiencies in student models, organizes knowledge delivery through progressive curricula, and adapts representations to match the cognitive capacity of student models. We integrate Bloom's Mastery Learning Principles and Vygotsky's Zone of Proximal Development to create a dynamic distillation process where student models approach teacher model's performance on prerequisite knowledge before advancing, and new knowledge is introduced with controlled, gradual difficulty increments. Extensive experiments using LLaMA-3.1/3.2 and Qwen2.5 as student models demonstrate that IOA achieves significant improvements over baseline distillation methods, with student models retaining 94.7% of teacher performance on DollyEval while using less than 1/10th of the parameters. Our framework particularly excels in complex reasoning tasks, showing 19.2% improvement on MATH and 22.3% on HumanEval compared with state-of-the-art baselines.