Seq2Seq2Seq: Lossless Data Compression via Discrete Latent Transformers and Reinforcement Learning
作者: Mahdi Khodabandeh, Ghazal Shabani, Arash Yousefi Jordehi, Seyed Abolghasem Mirroshandel
分类: cs.AI, cs.CL, cs.IT
发布日期: 2026-02-12
💡 一句话要点
提出基于离散潜在Transformer和强化学习的Seq2Seq2Seq无损数据压缩方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无损压缩 数据压缩 强化学习 Transformer 序列到序列
📋 核心要点
- 传统压缩技术难以充分利用复杂数据格式中的结构和冗余,深度学习压缩方法依赖稠密向量表示,掩盖了底层token结构。
- 利用强化学习训练T5语言模型,将数据压缩为token序列,保留token结构,更贴近原始数据格式,提升压缩率并保持语义完整性。
- 使用离策略强化学习优化序列长度,最小化冗余,提高压缩效率,无需外部语法或世界知识,压缩率优于传统方法。
📝 摘要(中文)
本文提出了一种新颖的无损数据压缩方法,该方法利用应用于T5语言模型的强化学习。该方法将数据压缩为token序列,而非传统的向量表示。与将信息编码到连续潜在空间的自编码器不同,该方法保留了基于token的结构,更贴近原始数据格式,从而在保持语义完整性的同时实现更高的压缩率。通过使用离策略强化学习算法训练模型,优化序列长度以最小化冗余并提高压缩效率。该系统不依赖外部语法或世界知识,在压缩率方面表现出优于传统方法的显著改进,为各种应用中更强大、更实用的压缩解决方案铺平了道路。
🔬 方法详解
问题定义:论文旨在解决传统无损数据压缩方法在处理复杂数据格式时,无法有效利用数据内部结构和冗余的问题。现有方法,如基于字典和统计的方法,在面对复杂数据时压缩效率较低。此外,基于深度学习的压缩方法通常依赖于稠密的向量表示,这会丢失原始数据的token结构,不利于语义信息的保持。
核心思路:论文的核心思路是利用Transformer语言模型强大的序列建模能力,将数据压缩成离散的token序列,而不是连续的向量表示。通过保留token结构,可以更好地保持数据的语义信息,从而提高压缩率。此外,使用强化学习来优化token序列的长度,以最小化冗余,进一步提高压缩效率。
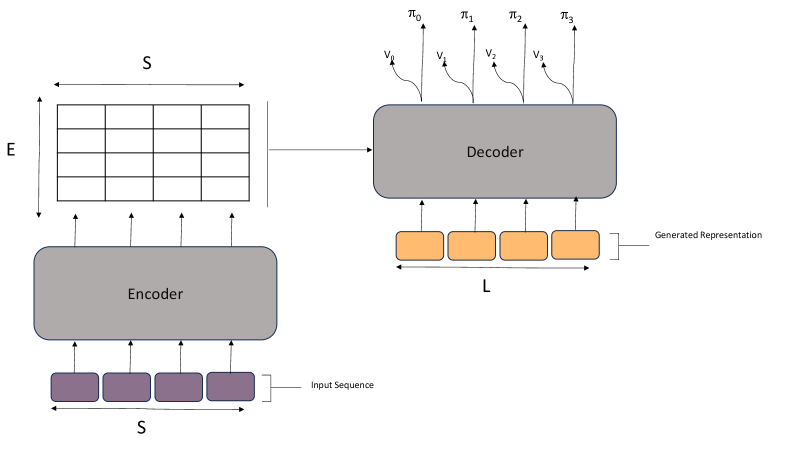
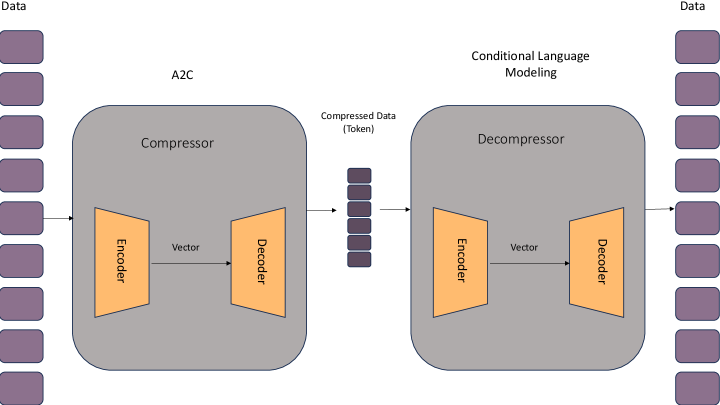
技术框架:该方法基于Seq2Seq2Seq框架,使用T5语言模型作为核心组件。首先,编码器将原始数据编码成一个离散的token序列。然后,解码器将该token序列解码成原始数据。强化学习算法用于优化编码器的策略,目标是生成尽可能短的token序列,同时保证解码器能够准确地重构原始数据。整个框架可以看作是一个序列到序列的转换过程,其中输入是原始数据,输出是压缩后的token序列。
关键创新:该方法最重要的创新点在于使用强化学习来优化离散的token序列,而不是直接优化连续的向量表示。这种方法能够更好地保留原始数据的token结构,从而提高压缩率和语义保持能力。此外,该方法不需要任何外部的语法或世界知识,可以应用于各种不同的数据类型。
关键设计:论文使用了一种离策略的强化学习算法来训练模型。具体来说,使用REINFORCE算法,奖励函数是压缩后的token序列的长度的负数。为了提高训练的稳定性,使用了基线函数来减少方差。此外,还使用了dropout和label smoothing等正则化技术来防止过拟合。T5模型的参数设置遵循原始论文的建议,并根据具体任务进行了微调。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个数据集上都取得了显著的压缩率提升,优于传统的压缩算法,例如gzip和bzip2。与基于自编码器的深度学习压缩方法相比,该方法在保持语义完整性的同时,也实现了更高的压缩率。具体的性能数据在论文中进行了详细的展示和分析。
🎯 应用场景
该研究成果可应用于各种需要高效无损数据压缩的领域,例如数据存储、网络传输、图像和视频压缩等。通过提高压缩率,可以降低存储成本和传输带宽需求,从而提高系统的整体效率。此外,由于该方法不需要任何外部知识,因此可以应用于各种不同的数据类型,具有广泛的应用前景。
📄 摘要(原文)
Efficient lossless compression is essential for minimizing storage costs and transmission overhead while preserving data integrity. Traditional compression techniques, such as dictionary-based and statistical methods, often struggle to optimally exploit the structure and redundancy in complex data formats. Recent advancements in deep learning have opened new avenues for compression; however, many existing approaches depend on dense vector representations that obscure the underlying token structure. To address these limitations, we propose a novel lossless compression method that leverages Reinforcement Learning applied to a T5 language model architecture. This approach enables the compression of data into sequences of tokens rather than traditional vector representations. Unlike auto-encoders, which typically encode information into continuous latent spaces, our method preserves the token-based structure, aligning more closely with the original data format. This preservation allows for higher compression ratios while maintaining semantic integrity. By training the model using an off-policy Reinforcement Learning algorithm, we optimize sequence length to minimize redundancy and enhance compression efficiency. Our method introduces an efficient and adaptive data compression system built upon advanced Reinforcement Learning techniques, functioning independently of external grammatical or world knowledge. This approach shows significant improvements in compression ratios compared to conventional methods. By leveraging the latent information within language models, our system effectively compresses data without requiring explicit content understanding, paving the way for more robust and practical compression solutions across various applications.