The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context
作者: Xiaoyuan Liu, Tian Liang, Dongyang Ma, Deyu Zhou, Haitao Mi, Pinjia He, Yan Wang
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出StateLM,赋予语言模型记忆管理能力,提升长文本处理和对话性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 状态语言模型 长文本处理 记忆管理 上下文学习 智能代理
📋 核心要点
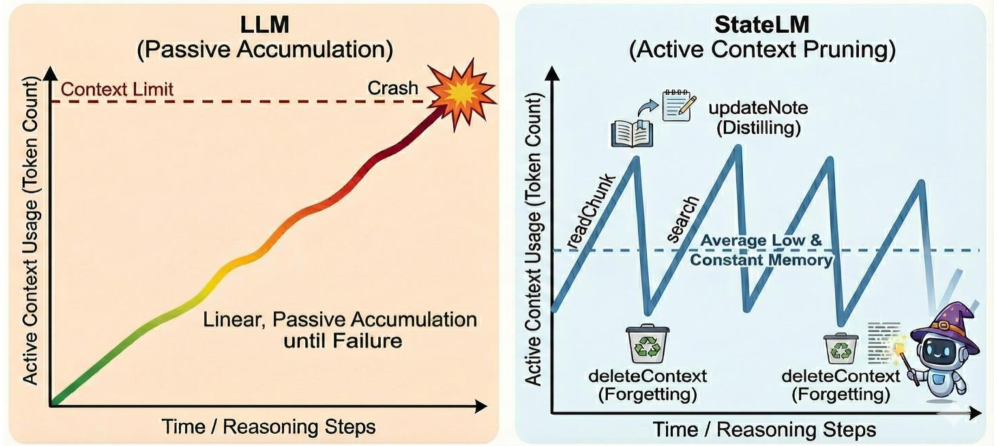
- 现有语言模型缺乏有效管理自身上下文记忆的能力,如同没有魔杖的邓布利多,只能被动接受人工构建的上下文。
- StateLM的核心思想是赋予模型内部推理循环,使其能够主动管理记忆工具,动态构建上下文,突破固定窗口限制。
- 实验表明,StateLM在长文档问答、聊天记忆和深度研究任务中显著优于标准LLM,最高提升达52%。
📝 摘要(中文)
本文介绍了一种新的基础模型类别StateLM,它具有管理自身状态的内部推理循环。该模型配备了一套记忆工具,如上下文剪枝、文档索引和笔记记录,并经过训练以主动管理这些工具。通过学习动态地构建自己的上下文,StateLM打破了固定窗口的架构限制。在各种模型规模上的实验表明,StateLM在不同场景中都非常有效。在长文档问答任务中,StateLM始终优于所有模型规模的标准LLM;在聊天记忆任务中,它们实现了10%到20%的绝对准确率提升。在深度研究任务BrowseComp-Plus上,性能差距更加明显:StateLM达到了高达52%的准确率,而标准LLM的性能仅为5%左右。最终,该方法将LLM从被动预测器转变为状态感知代理,使推理成为一个有状态且可管理的过程。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理长文本和需要长期记忆的任务时面临挑战。传统的LLM受限于固定的上下文窗口大小,无法有效地利用和管理大量的历史信息。这导致模型在长文档问答、对话记忆等任务中表现不佳,无法充分利用已有的知识和经验。
核心思路:StateLM的核心思路是赋予LLM管理自身状态的能力,使其能够像人类一样主动地组织、存储和检索记忆。通过引入内部推理循环和一系列记忆工具,StateLM可以动态地构建和维护自己的上下文,从而突破固定窗口的限制,更好地处理长文本和需要长期记忆的任务。
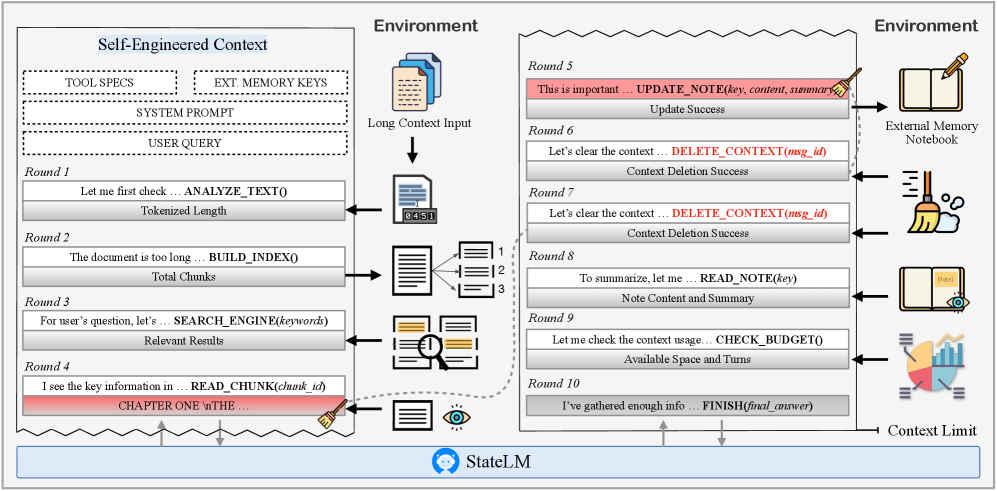
技术框架:StateLM的整体架构包含一个基础的LLM和一个记忆管理模块。记忆管理模块包含以下几个主要组件:上下文剪枝(Context Pruning),用于去除不相关的上下文信息;文档索引(Document Indexing),用于构建和维护文档的索引结构;笔记记录(Note-taking),用于记录重要的信息和结论。模型通过内部推理循环,决定何时以及如何使用这些记忆工具来管理自己的状态。
关键创新:StateLM最重要的创新在于赋予了LLM主动管理自身记忆的能力。与传统的LLM不同,StateLM不再是被动地接受人工构建的上下文,而是可以根据任务的需求,动态地构建和维护自己的上下文。这种主动的记忆管理机制使得StateLM能够更好地处理长文本和需要长期记忆的任务。
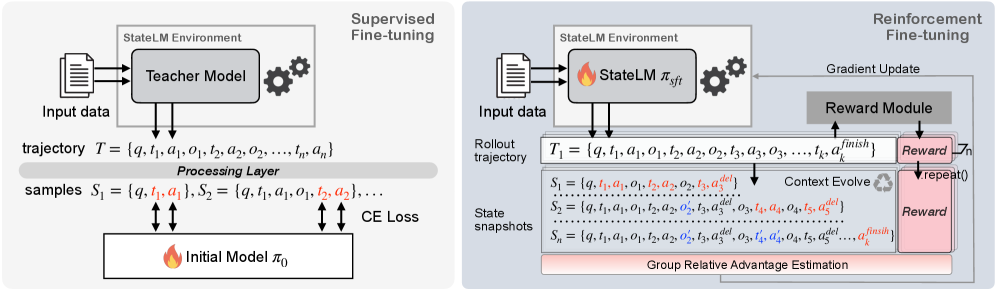
关键设计:StateLM的关键设计包括:1) 使用强化学习或模仿学习来训练模型如何使用记忆工具;2) 设计有效的上下文剪枝策略,以去除不相关的上下文信息;3) 构建高效的文档索引结构,以便快速检索相关信息;4) 设计合适的笔记记录格式,以便模型能够有效地记录和利用重要的信息。
🖼️ 关键图片
📊 实验亮点
StateLM在长文档问答任务中始终优于所有模型规模的标准LLM。在聊天记忆任务中,StateLM实现了10%到20%的绝对准确率提升。在深度研究任务BrowseComp-Plus上,StateLM达到了高达52%的准确率,而标准LLM的性能仅为5%左右。这些结果表明,StateLM在处理长文本和需要长期记忆的任务方面具有显著的优势。
🎯 应用场景
StateLM具有广泛的应用前景,包括智能客服、长文档处理、科研助手、智能写作等领域。它可以帮助用户更有效地处理和利用大量的信息,提高工作效率和创造力。未来,StateLM有望成为一种通用的智能代理,能够自主地学习、推理和解决各种复杂的问题。
📄 摘要(原文)
In the world of Harry Potter, when Dumbledore's mind is overburdened, he extracts memories into a Pensieve to be revisited later. In the world of AI, while we possess the Pensieve-mature databases and retrieval systems, our models inexplicably lack the "wand" to operate it. They remain like a Dumbledore without agency, passively accepting a manually engineered context as their entire memory. This work finally places the wand in the model's hand. We introduce StateLM, a new class of foundation models endowed with an internal reasoning loop to manage their own state. We equip our model with a suite of memory tools, such as context pruning, document indexing, and note-taking, and train it to actively manage these tools. By learning to dynamically engineering its own context, our model breaks free from the architectural prison of a fixed window. Experiments across various model sizes demonstrate StateLM's effectiveness across diverse scenarios. On long-document QA tasks, StateLMs consistently outperform standard LLMs across all model scales; on the chat memory task, they achieve absolute accuracy improvements of 10% to 20% over standard LLMs. On the deep research task BrowseComp-Plus, the performance gap becomes even more pronounced: StateLM achieves up to 52% accuracy, whereas standard LLM counterparts struggle around 5%. Ultimately, our approach shifts LLMs from passive predictors to state-aware agents where reasoning becomes a stateful and manageable process.