Tiny Recursive Reasoning with Mamba-2 Attention Hybrid
作者: Wenlong Wang, Fergal Reid
分类: cs.AI, cs.CL
发布日期: 2026-02-12
💡 一句话要点
Mamba-2混合注意力机制提升了Tiny递归推理模型在抽象推理任务上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 递归推理 Mamba-2 状态空间模型 抽象推理 ARC-AGI 混合注意力 模型优化
📋 核心要点
- 现有递归推理模型依赖Transformer块,计算成本较高,探索更高效的算子是挑战。
- 用Mamba-2混合算子替换Transformer块,利用其状态空间模型特性进行迭代优化,保持参数量不变。
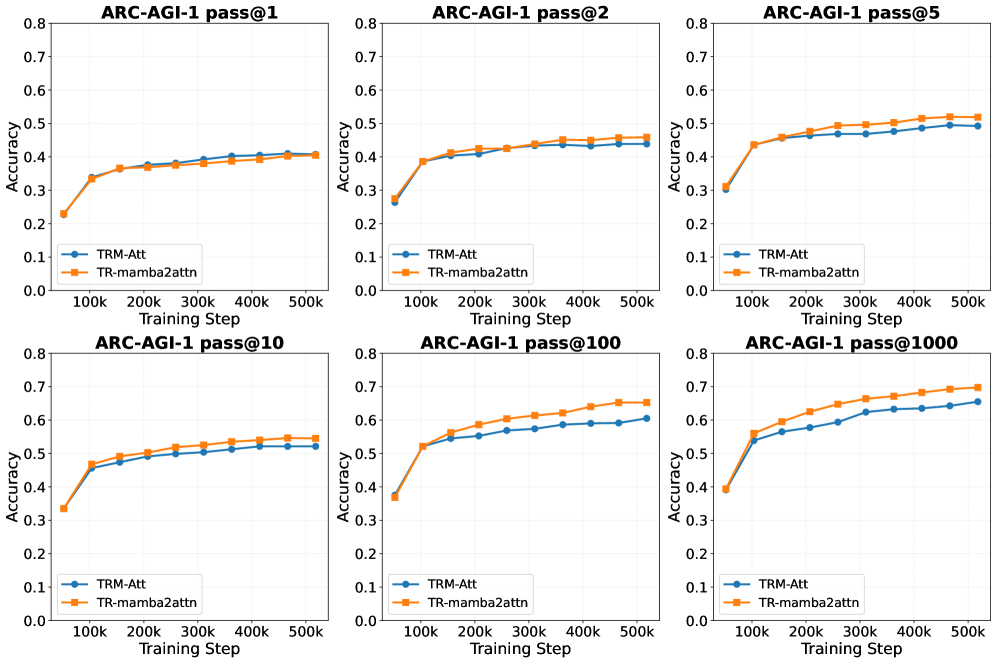
- 实验表明,该混合模型在ARC-AGI-1数据集上提升了pass@2和pass@100指标,验证了Mamba-2的有效性。
📝 摘要(中文)
本文研究了在递归推理模型(如TRM)中使用Mamba-2算子的可行性。TRM通过隐空间内的迭代优化,仅用小型网络(700万参数)即可在抽象推理任务上取得优异表现。Mamba-2的状态空间递归本身也是一种迭代优化,因此是递归推理的天然候选。本文将TRM中的Transformer块替换为Mamba-2混合算子,保持参数量基本不变(683万 vs 686万)。在ARC-AGI-1数据集上,该混合模型将pass@2指标提高了+2.0%(45.88% vs 43.88%),并且在更高的K值下始终优于基线(pass@100时+4.75%),同时保持了pass@1的性能。这表明该模型能更可靠地生成正确解,具有更好的候选覆盖率,而top-1选择能力相似。研究结果验证了Mamba-2混合算子在递归框架内保持了推理能力,证明了基于SSM的算子在递归算子设计空间中的可行性,并为理解递归推理的最佳混合策略迈出了第一步。
🔬 方法详解
问题定义:论文旨在解决递归推理模型中算子选择的问题,特别是探索能否使用更高效的Mamba-2算子替代传统的Transformer块。现有基于Transformer的递归推理模型,例如TRM,虽然在抽象推理任务上表现出色,但Transformer的计算复杂度较高,限制了其在资源受限场景下的应用。因此,寻找一种既能保持推理能力,又能降低计算成本的算子是关键。
核心思路:论文的核心思路是将TRM中的Transformer块替换为Mamba-2混合算子。Mamba-2本身具有状态空间模型的特性,可以进行迭代优化,这与递归推理的思路天然契合。通过将Mamba-2集成到递归框架中,期望能够利用Mamba-2的高效计算能力,同时保持或提升模型的推理性能。这样设计的目的是探索基于SSM的算子在递归推理中的可行性,并为未来的算子选择提供指导。
技术框架:整体框架仍然是TRM的递归推理结构,主要变化在于将TRM中的Transformer块替换为Mamba-2混合算子。该框架包含一个初始编码阶段,然后进入递归推理阶段,在隐空间内进行迭代优化,最后输出最终结果。主要模块包括:输入嵌入层、Mamba-2混合算子、残差连接和层归一化。递归推理阶段重复执行Mamba-2混合算子,每次迭代都对隐状态进行更新和优化。
关键创新:最重要的技术创新点是将Mamba-2算子引入到递归推理框架中,并验证了其可行性。与现有方法相比,该方法的主要区别在于使用了不同的算子进行迭代优化。Transformer依赖自注意力机制,计算复杂度较高,而Mamba-2基于状态空间模型,具有线性复杂度,计算效率更高。此外,Mamba-2的序列选择机制使其能够更好地处理长序列依赖关系。
关键设计:论文中关键的设计包括:保持参数量不变,以便公平比较不同算子的性能;使用Mamba-2混合算子,将Mamba-2与注意力机制相结合,以充分利用两者的优势;在ARC-AGI-1数据集上进行实验,该数据集是评估抽象推理能力的常用基准;使用pass@K作为评估指标,衡量模型生成正确解的能力。
🖼️ 关键图片
📊 实验亮点
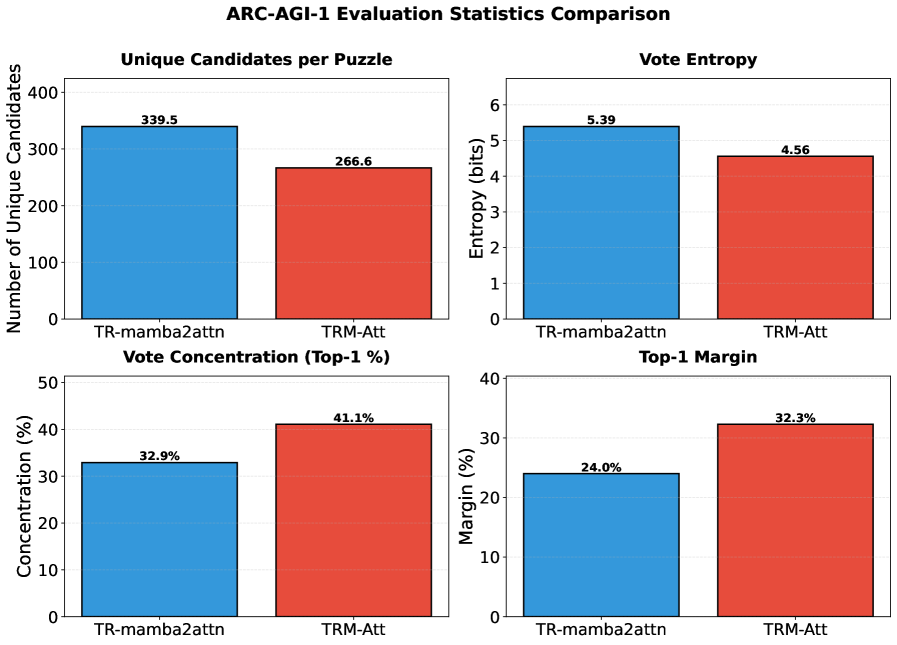
实验结果表明,将TRM中的Transformer块替换为Mamba-2混合算子后,在ARC-AGI-1数据集上,pass@2指标提高了+2.0%(45.88% vs 43.88%),pass@100指标提高了+4.75%,同时保持了pass@1的性能。这表明Mamba-2混合算子在保持推理能力的同时,提高了模型生成正确解的可靠性,具有更好的候选覆盖率。
🎯 应用场景
该研究成果可应用于资源受限的边缘设备或移动设备上的智能推理应用,例如智能机器人、自动驾驶和智能助手等。通过使用更高效的Mamba-2算子,可以在保持推理性能的同时,降低计算成本和功耗,从而扩展递归推理模型的应用范围。未来,该研究还可以促进递归推理模型在更复杂任务上的应用,例如视觉推理、自然语言理解和强化学习。
📄 摘要(原文)
Recent work on recursive reasoning models like TRM demonstrates that tiny networks (7M parameters) can achieve strong performance on abstract reasoning tasks through latent recursion -- iterative refinement in hidden representation space without emitting intermediate tokens. This raises a natural question about operator choice: Mamba-2's state space recurrence is itself a form of iterative refinement, making it a natural candidate for recursive reasoning -- but does introducing Mamba-2 into the recursive scaffold preserve reasoning capability? We investigate this by replacing the Transformer blocks in TRM with Mamba-2 hybrid operators while maintaining parameter parity (6.83M vs 6.86M parameters). On ARC-AGI-1, we find that the hybrid improves pass@2 (the official metric) by +2.0\% (45.88\% vs 43.88\%) and consistently outperforms at higher K values (+4.75\% at pass@100), whilst maintaining pass@1 parity. This suggests improved candidate coverage -- the model generates correct solutions more reliably -- with similar top-1 selection. Our results validate that Mamba-2 hybrid operators preserve reasoning capability within the recursive scaffold, establishing SSM-based operators as viable candidates in the recursive operator design space and taking a first step towards understanding the best mixing strategies for recursive reasoning.