InjectRBP: Steering Large Language Model Reasoning Behavior via Pattern Injection
作者: Xiuping Wu, Zhao Yu, Yuxin Cheng, Ngai Wong, Liangjun Ke, Tapas Mishra, Konstantinos V. Katsikopoulos
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
InjectRBP:通过行为模式注入引导大语言模型推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理 行为模式 提示工程 强化学习
📋 核心要点
- 现有方法调整提示以增强LLM推理,但缺乏对底层行为模式的系统分析,设计较为直观。
- 论文核心思想是:通过结构化地注入从模型自身行为中学习到的推理模式,来引导和优化LLM的推理过程。
- 提出的InjectCorrect和InjectRLOpt方法无需更新模型参数,即可在推理任务上分别获得最高5.34%和8.67%的性能提升。
📝 摘要(中文)
推理能够显著提升大语言模型的性能。尽管最近的研究已经利用行为相关的提示调整来增强推理能力,但这些设计在很大程度上仍然是直观的,并且缺乏对底层行为模式的系统分析。受此启发,我们从行为模式的角度研究了模型的推理行为如何塑造推理过程。我们观察到,模型在响应特定类型的问题时,会表现出推理行为的自适应分布,并且结构化地注入这些模式可以显著影响模型推理过程和结果的质量。基于这些发现,我们提出了两种无需参数更新的优化方法:InjectCorrect和InjectRLOpt。InjectCorrect通过模仿模型自身过去正确答案中提取的行为模式来引导模型。InjectRLOpt从历史行为模式数据中学习一个价值函数,并通过我们提出的可靠性感知Softmax策略,在推理过程中生成行为注入剂来引导推理过程。我们的实验表明,这两种方法都可以在不修改模型参数的情况下提高模型在各种推理任务中的性能,分别实现了高达5.34%和8.67%的增益。
🔬 方法详解
问题定义:现有的大语言模型推理增强方法主要依赖于直观的提示工程,缺乏对模型推理过程中行为模式的深入理解和系统分析。这导致难以有效地引导模型进行高质量的推理,并且缺乏可解释性。因此,如何系统地分析和利用模型的推理行为模式,以提升推理性能,是一个亟待解决的问题。
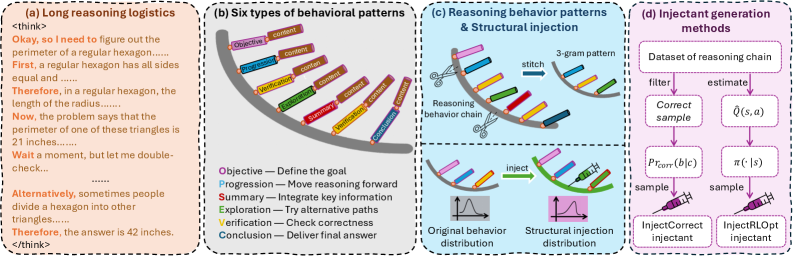
核心思路:论文的核心思路是通过观察和学习模型在推理过程中的行为模式,然后将这些模式以结构化的方式注入到模型的推理过程中,从而引导模型朝着更正确的方向进行推理。这种方法的核心在于认为模型的推理行为并非随机,而是存在一定的模式,并且这些模式与推理的质量密切相关。
技术框架:论文提出了两种主要的方法:InjectCorrect和InjectRLOpt。InjectCorrect方法通过模仿模型自身过去正确答案中提取的行为模式来引导模型。InjectRLOpt方法则利用强化学习的思想,从历史行为模式数据中学习一个价值函数,并通过可靠性感知Softmax策略生成行为注入剂,在推理过程中引导推理过程。两种方法都无需更新模型参数,属于prompt engineering的范畴。整体流程包括:1) 收集模型的推理行为数据;2) 分析并提取行为模式;3) 设计注入机制,将行为模式注入到推理过程中;4) 评估注入后的推理性能。
关键创新:论文的关键创新在于:1) 首次从行为模式的角度系统地研究了大语言模型的推理过程;2) 提出了两种无需参数更新的行为模式注入方法,能够有效地引导模型的推理过程;3) 提出了一种可靠性感知Softmax策略,用于生成更可靠的行为注入剂。与现有方法的本质区别在于,该方法不是简单地调整提示,而是深入分析模型的行为模式,并利用这些模式来引导推理。
关键设计:InjectCorrect的关键设计在于如何从历史正确答案中提取具有代表性的行为模式,并将其有效地注入到当前的推理过程中。InjectRLOpt的关键设计在于如何设计价值函数,以及如何利用可靠性感知Softmax策略生成行为注入剂。具体而言,价值函数可能基于历史行为模式的成功率进行设计,而可靠性感知Softmax策略则会考虑不同行为模式的置信度,从而选择更可靠的模式进行注入。论文中可能还涉及一些超参数的设置,例如注入强度、历史数据窗口大小等,这些参数的选择可能会影响最终的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,InjectCorrect和InjectRLOpt两种方法都能够在不修改模型参数的情况下,显著提高模型在各种推理任务上的性能。InjectCorrect方法最高可提升5.34%,InjectRLOpt方法最高可提升8.67%。这些结果表明,通过行为模式注入来引导大语言模型的推理过程是有效的。
🎯 应用场景
该研究成果可应用于各种需要大语言模型进行推理的场景,例如问答系统、知识图谱推理、代码生成等。通过注入合适的行为模式,可以提高模型在这些任务上的准确性和可靠性。此外,该研究也为理解和控制大语言模型的推理过程提供了一种新的思路,有助于开发更可信赖的人工智能系统。
📄 摘要(原文)
Reasoning can significantly enhance the performance of Large Language Models. While recent studies have exploited behavior-related prompts adjustment to enhance reasoning, these designs remain largely intuitive and lack a systematic analysis of the underlying behavioral patterns. Motivated by this, we investigate how models' reasoning behaviors shape reasoning from the perspective of behavioral patterns. We observe that models exhibit adaptive distributions of reasoning behaviors when responding to specific types of questions, and that structurally injecting these patterns can substantially influence the quality of the models' reasoning processes and outcomes. Building on these findings, we propose two optimization methods that require no parameter updates: InjectCorrect and InjectRLOpt. InjectCorrect guides the model by imitating behavioral patterns derived from its own past correct answers. InjectRLOpt learns a value function from historical behavior-pattern data and, via our proposed Reliability-Aware Softmax Policy, generates behavioral injectant during inference to steer the reasoning process. Our experiments demonstrate that both methods can improve model performance across various reasoning tasks without requiring any modifications to model parameters, achieving gains of up to 5.34% and 8.67%, respectively.