Leveraging LLMs to support co-evolution between definitions and instances of textual DSLs: A Systematic Evaluation
作者: Weixing Zhang, Bowen Jiang, Yuhong Fu, Anne Koziolek, Regina Hebig, Daniel Strüber
分类: cs.SE, cs.AI
发布日期: 2026-02-12
💡 一句话要点
利用LLM协同演化文本DSL定义与实例,系统评估其性能与局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本DSL 协同演化 软件语言工程 模型驱动工程
📋 核心要点
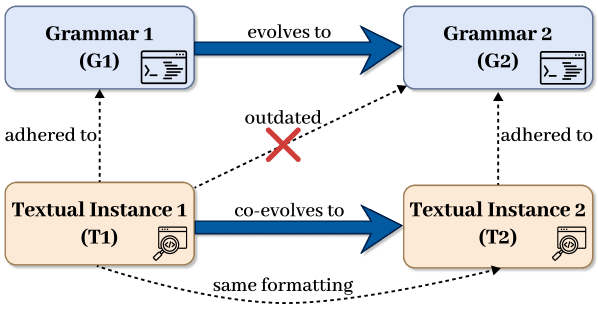
- 现有模型驱动工程方法在文本DSL协同演化中,无法有效处理布局、注释等人类相关信息。
- 利用LLM的强大能力,协同演化文本DSL的语法定义和实例,旨在保留更多人类可读信息。
- 实验表明,LLM在小规模DSL演化中表现出色,但在大规模场景中性能下降,响应时间显著增加。
📝 摘要(中文)
软件语言会随着时间推移而演变,例如添加新特性。当语法演变时,最初符合语法的文本实例可能会过时。虽然模型驱动工程提供了许多技术来协同演化模型和元模型变更,但这些方法并非为文本DSL设计,并且可能丢失人类相关的信息,如布局和注释。本研究系统地评估了大型语言模型(LLM)在协同演化文本DSL语法和实例方面的潜力。使用Claude Sonnet 4.5和GPT-5.2,在十种案例语言上分别运行十次,评估了正确性和人类导向信息的保留。结果表明,在小规模案例中表现出色(对于需要修改少于20行的实例,精确率和召回率均≥94%),但性能随规模而降低:Claude在40行时保持85%的召回率,而GPT在最大实例上失败。响应时间随着实例大小而显着增加,语法演化复杂性和删除粒度对性能的影响大于变更类型。这些发现阐明了基于LLM的协同演化何时有效,以及当前仍然存在的局限性。
🔬 方法详解
问题定义:论文旨在解决文本领域特定语言(DSL)在演化过程中,其语法定义和现有实例如何协同演化的问题。现有模型驱动工程方法虽然可以处理模型和元模型的演化,但对于文本DSL,它们往往会丢失布局、注释等对人类理解至关重要的信息,导致演化后的DSL实例难以维护和理解。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大文本处理和生成能力,将DSL语法演化和实例更新视为一个翻译或重构问题。通过提示工程,引导LLM理解DSL语法变更,并据此修改现有的DSL实例,从而实现语法和实例的协同演化,同时尽可能保留原始实例中的人类可读信息。
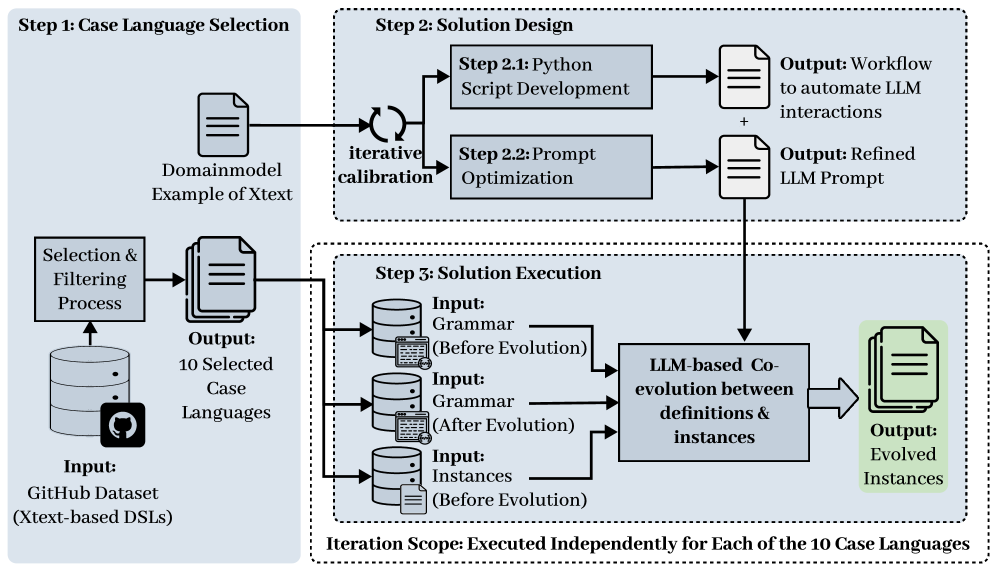
技术框架:该研究采用实验评估的方法,没有提出新的技术框架。其主要流程是:1) 选择一组具有代表性的文本DSL作为案例;2) 对这些DSL的语法进行演化(例如,添加、删除或修改语法规则);3) 使用LLM(Claude Sonnet 4.5和GPT-5.2)根据语法演化自动更新DSL实例;4) 评估LLM更新后的实例的正确性(是否符合新的语法)以及人类可读信息的保留程度。
关键创新:该研究的关键创新在于探索了LLM在文本DSL协同演化中的应用潜力,并系统地评估了其性能。与传统的模型驱动工程方法相比,LLM能够更好地处理文本DSL的特性,例如保留布局和注释。此外,该研究还揭示了LLM在不同规模和复杂度的DSL演化场景下的性能表现,为未来的研究提供了指导。
关键设计:该研究的关键设计在于实验评估的设计。研究人员选择了10种不同的文本DSL,并对每种DSL进行了10次不同的语法演化。对于每次演化,他们使用LLM自动更新DSL实例,并使用精确率和召回率等指标来评估更新后的实例的正确性和人类可读信息的保留程度。此外,他们还分析了不同因素(例如,实例大小、语法演化复杂性、变更类型)对LLM性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在小规模DSL实例演化中表现出色,精确率和召回率均高于94%(修改行数少于20行)。Claude在40行修改规模下仍能保持85%的召回率,但GPT在最大规模实例上表现不佳。响应时间随实例规模显著增加,语法演化复杂性和删除粒度对性能影响较大。
🎯 应用场景
该研究成果可应用于软件开发、领域建模等领域,帮助开发者更高效地维护和演化文本DSL。通过自动化DSL实例的更新,可以减少手动修改的工作量,降低出错风险,并提高软件系统的可维护性和可演化性。未来,该技术有望集成到DSL开发工具中,为开发者提供更智能化的支持。
📄 摘要(原文)
Software languages evolve over time for reasons such as feature additions. When grammars evolve, textual instances that originally conformed to them may become outdated. While model-driven engineering provides many techniques for co-evolving models with metamodel changes, these approaches are not designed for textual DSLs and may lose human-relevant information such as layout and comments. This study systematically evaluates the potential of large language models (LLMs) for co-evolving grammars and instances of textual DSLs. Using Claude Sonnet 4.5 and GPT-5.2 across ten case languages with ten runs each, we assess both correctness and preservation of human-oriented information. Results show strong performance on small-scale cases ($\geq$94% precision and recall for instances requiring fewer than 20 modified lines), but performance degraded with scale: Claude maintains 85% recall at 40 lines, while GPT fails on the largest instances. Response time increases substantially with instance size, and grammar evolution complexity and deletion granularity affect performance more than change type. These findings clarify when LLM-based co-evolution is effective and where current limitations remain.