From Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders
作者: Yifan Luo, Yang Zhan, Jiedong Jiang, Tianyang Liu, Mingrui Wu, Zhennan Zhou, Bin Dong
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出HSAE,通过分层稀疏自编码器构建结构化特征森林,挖掘LLM中的多尺度概念结构。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分层稀疏自编码器 大型语言模型 特征提取 可解释性 结构化表示
📋 核心要点
- 现有稀疏自编码器提取的LLM特征通常是孤立的,忽略了LLM中内在的分层结构。
- 提出分层稀疏自编码器(HSAE),联合学习一系列SAEs及其特征间的父子关系,以捕获LLM中的分层结构。
- 实验表明,HSAE能恢复语义上有意义的层次结构,同时保持重建保真度和可解释性。
📝 摘要(中文)
稀疏自编码器(SAEs)已被证明能有效地从大型语言模型(LLMs)中提取单义特征,但这些特征通常是孤立地识别的。然而,大量证据表明,LLMs捕获了自然语言的内在结构,其中“特征分裂”现象尤其表明这种结构是分层的。为了捕获这一点,我们提出了分层稀疏自编码器(HSAE),它联合学习一系列SAEs以及它们特征之间的父子关系。HSAE通过两种新颖的机制加强了父特征和子特征之间的对齐:结构约束损失和随机特征扰动机制。在各种LLMs和层上的大量实验表明,HSAE始终如一地恢复语义上有意义的层次结构,这得到了定性案例研究和严格的定量指标的支持。同时,HSAE在不同的字典大小下,保留了标准SAEs的重建保真度和可解释性。我们的工作提供了一个强大且可扩展的工具,用于发现和分析嵌入在LLM表示中的多尺度概念结构。
🔬 方法详解
问题定义:现有方法使用稀疏自编码器从LLM中提取特征,但这些特征是孤立的,没有考虑到LLM内部固有的层次结构。这种孤立的特征表示方式无法充分利用LLM所学习到的复杂语义关系,限制了对LLM内部机制的理解。
核心思路:论文的核心思路是构建一个分层的稀疏自编码器(HSAE),通过联合学习多个SAE以及它们特征之间的父子关系,来显式地建模LLM中存在的层次结构。通过这种方式,HSAE能够捕获LLM中不同粒度的语义信息,并揭示特征之间的依赖关系。
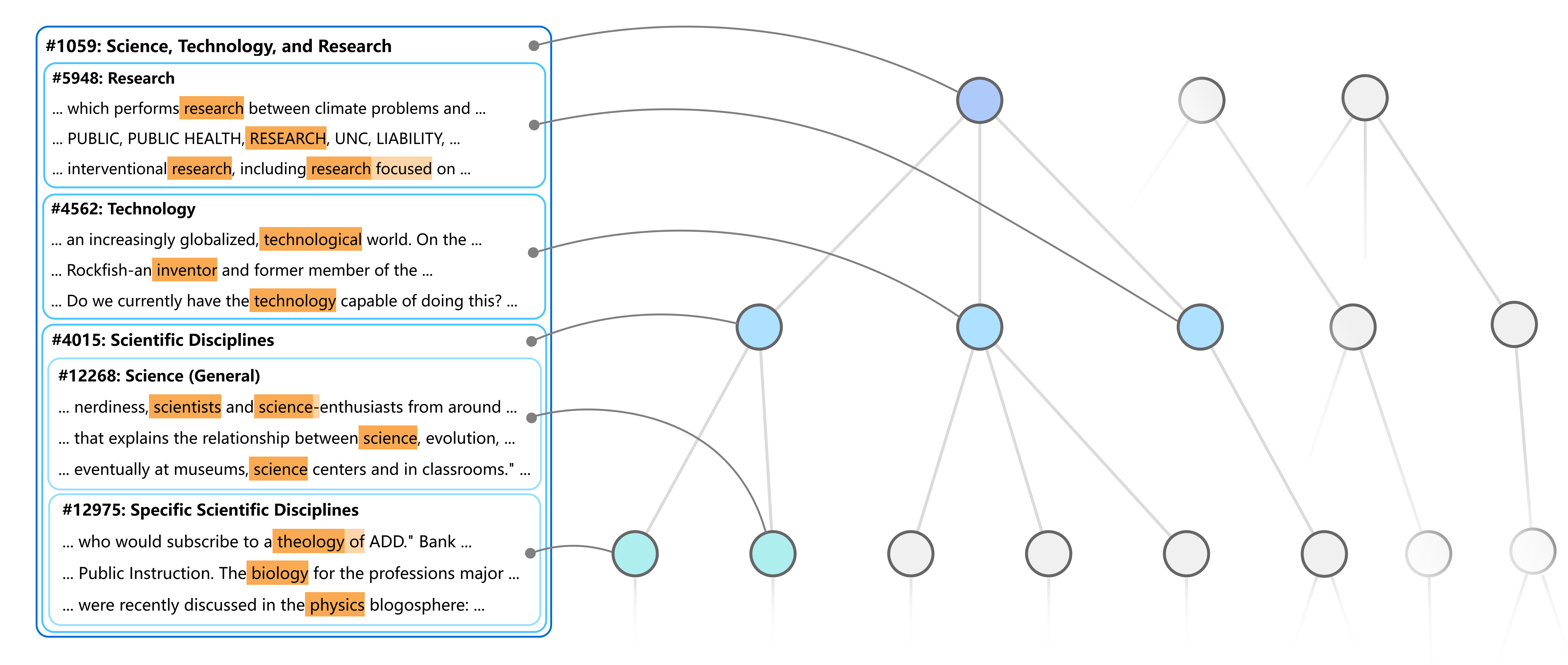
技术框架:HSAE包含多个层级的SAE,每个层级的SAE负责提取不同抽象程度的特征。底层SAE提取细粒度的特征,而高层SAE则提取更抽象、更概括的特征。这些SAE通过父子关系连接起来,形成一个树状结构。训练过程中,HSAE同时优化所有SAE的参数以及父子关系。
关键创新:HSAE的关键创新在于引入了结构约束损失和随机特征扰动机制,以加强父特征和子特征之间的对齐。结构约束损失鼓励父特征能够重建其子特征,而随机特征扰动机制则通过在训练过程中随机扰动特征,来提高模型的鲁棒性和泛化能力。
关键设计:HSAE使用L1正则化来保证特征的稀疏性。结构约束损失定义为父特征重建其子特征的均方误差。随机特征扰动机制通过以一定概率将特征置零来实现。父子关系的确定可以通过计算特征之间的相关性或者使用注意力机制来实现。模型的训练采用交替优化的方式,先训练SAE的参数,然后更新父子关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HSAE能够有效地恢复LLM中语义上有意义的层次结构。定性案例研究表明,HSAE能够发现LLM学习到的概念之间的父子关系,例如,“狗”是“宠物”的子概念。定量指标表明,HSAE在重建保真度和可解释性方面与标准SAE相当,同时能够更好地捕获LLM中的分层结构。
🎯 应用场景
该研究成果可应用于分析和理解大型语言模型的内部工作机制,例如,可以用于发现LLM学习到的概念层次结构,或者用于诊断LLM的潜在问题。此外,该方法还可以用于改进LLM的训练和微调,例如,可以通过引入分层结构来提高LLM的泛化能力。
📄 摘要(原文)
Sparse autoencoders (SAEs) have proven effective for extracting monosemantic features from large language models (LLMs), yet these features are typically identified in isolation. However, broad evidence suggests that LLMs capture the intrinsic structure of natural language, where the phenomenon of "feature splitting" in particular indicates that such structure is hierarchical. To capture this, we propose the Hierarchical Sparse Autoencoder (HSAE), which jointly learns a series of SAEs and the parent-child relationships between their features. HSAE strengthens the alignment between parent and child features through two novel mechanisms: a structural constraint loss and a random feature perturbation mechanism. Extensive experiments across various LLMs and layers demonstrate that HSAE consistently recovers semantically meaningful hierarchies, supported by both qualitative case studies and rigorous quantitative metrics. At the same time, HSAE preserves the reconstruction fidelity and interpretability of standard SAEs across different dictionary sizes. Our work provides a powerful, scalable tool for discovering and analyzing the multi-scale conceptual structures embedded in LLM representations.