Predicting LLM Output Length via Entropy-Guided Representations
作者: Huanyi Xie, Yubin Chen, Liangyu Wang, Lijie Hu, Di Wang
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出基于熵引导表征的LLM输出长度预测框架,提升推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 长度预测 熵引导 Token池化 渐进式预测 序列生成 模型优化
📋 核心要点
- 现有LLM长度预测方法依赖辅助模型,存在开销大、泛化性差等问题,难以应对随机生成场景。
- 提出一种轻量级框架,复用LLM内部隐藏状态,通过熵引导Token池化和渐进式长度预测实现高效预测。
- 在ForeLen基准测试中,该方法显著降低了长度预测的MAE,并提升了端到端吞吐量。
📝 摘要(中文)
大型语言模型(LLM)服务和强化学习(RL)采样中,序列长度的长尾分布导致批量推理中因过度填充而产生显著的计算浪费。现有方法依赖辅助模型进行静态长度预测,但开销高、泛化性差,且在随机“一对多”采样场景中失效。本文提出一种轻量级框架,复用主模型的内部隐藏状态以实现高效的长度预测。该框架包含两个核心组件:1) 熵引导Token池化(EGTP),利用即时激活和token熵进行高精度静态预测,成本可忽略不计;2) 渐进式长度预测(PLP),在每个解码步骤动态估计剩余长度,以处理随机生成。为了验证该方法,构建并发布了ForeLen,一个包含长序列、思维链和RL数据的综合基准。在ForeLen上,EGTP实现了最先进的精度,MAE比最佳基线降低了29.16%。将该方法与长度感知调度器集成,可显著提高端到端吞吐量。该工作为高效LLM推理提供了一个新的技术和评估基线。
🔬 方法详解
问题定义:论文旨在解决LLM推理过程中,由于序列长度长尾分布导致的计算资源浪费问题。现有方法主要依赖于额外的辅助模型进行长度预测,这些模型通常计算开销大,泛化能力有限,并且难以处理像强化学习采样这类随机性较强的“一对多”生成场景。因此,需要一种更高效、更准确的长度预测方法,以减少填充,提高推理效率。
核心思路:论文的核心思路是复用LLM自身内部的隐藏状态信息,避免引入额外的模型开销。通过分析LLM在生成过程中的token激活和熵值,提取与序列长度相关的特征,并利用这些特征进行长度预测。这种方法不仅轻量高效,而且能够更好地适应LLM的生成特性。
技术框架:该框架主要包含两个核心模块:熵引导Token池化(EGTP)和渐进式长度预测(PLP)。EGTP用于静态长度预测,即在生成开始前预测序列的总长度。PLP则在解码过程中动态地估计剩余长度,从而处理随机生成的情况。整个流程是,首先使用EGTP进行初始长度预测,然后在解码的每个步骤,利用PLP更新剩余长度的估计,最终得到更准确的长度预测结果。
关键创新:该论文的关键创新在于提出了熵引导Token池化(EGTP)和渐进式长度预测(PLP)两种方法。EGTP利用token的熵值作为权重,对LLM的隐藏状态进行池化,从而提取与长度相关的特征。PLP则通过动态估计剩余长度,解决了传统方法难以处理的随机生成问题。与现有方法相比,该方法无需额外的辅助模型,并且能够更好地适应LLM的生成特性。
关键设计:EGTP的关键设计在于使用token的熵值作为池化权重。熵值反映了token的不确定性,高熵值的token通常包含更多的信息。通过使用熵值作为权重,可以更加关注那些对长度预测有重要影响的token。PLP的关键设计在于在每个解码步骤更新剩余长度的估计。这可以通过一个简单的线性模型或更复杂的神经网络来实现。损失函数可以选择均方误差(MSE)或平均绝对误差(MAE),以衡量预测长度与实际长度之间的差异。
🖼️ 关键图片
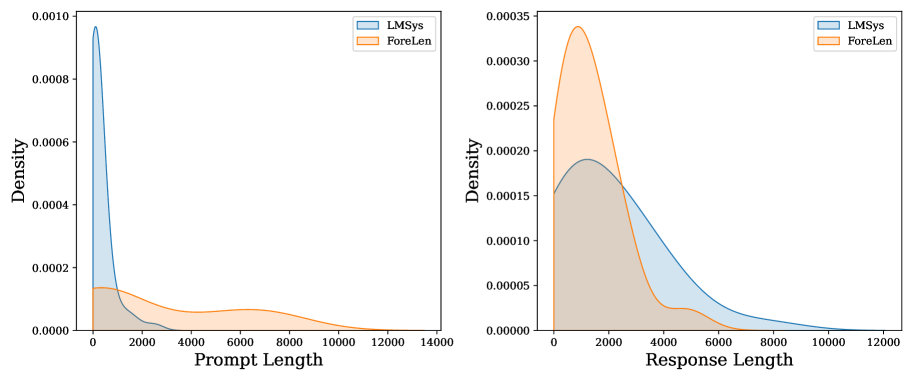
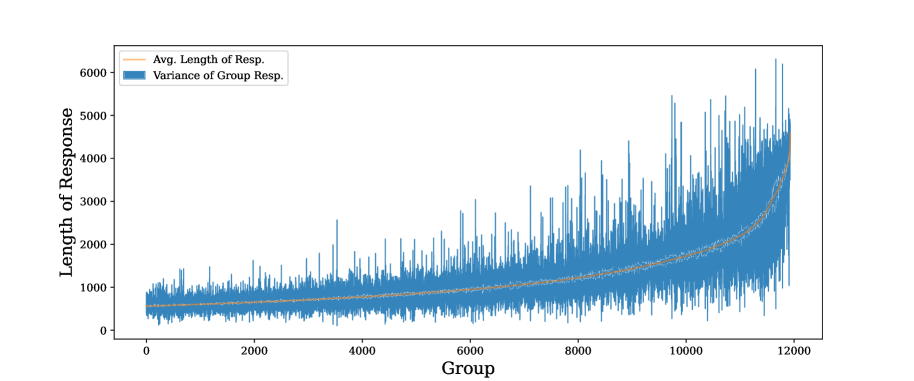

📊 实验亮点
实验结果表明,该方法在ForeLen基准测试中取得了显著的性能提升。EGTP在长度预测精度上达到了最先进水平,MAE比最佳基线降低了29.16%。此外,将该方法与长度感知调度器集成后,端到端吞吐量也得到了显著提高。这些结果验证了该方法在实际应用中的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于LLM的在线服务和强化学习训练中,通过更精确的长度预测,减少不必要的计算开销,提高资源利用率和系统吞吐量。特别是在需要处理大量长序列或随机生成任务的场景下,该方法具有显著的优势。未来,该技术可以进一步推广到其他序列生成模型,并与其他优化技术相结合,实现更高效的AI应用。
📄 摘要(原文)
The long-tailed distribution of sequence lengths in LLM serving and reinforcement learning (RL) sampling causes significant computational waste due to excessive padding in batched inference. Existing methods rely on auxiliary models for static length prediction, but they incur high overhead, generalize poorly, and fail in stochastic "one-to-many" sampling scenarios. We introduce a lightweight framework that reuses the main model's internal hidden states for efficient length prediction. Our framework features two core components: 1) Entropy-Guided Token Pooling (EGTP), which uses on-the-fly activations and token entropy for highly accurate static prediction with negligible cost, and 2) Progressive Length Prediction (PLP), which dynamically estimates the remaining length at each decoding step to handle stochastic generation. To validate our approach, we build and release ForeLen, a comprehensive benchmark with long-sequence, Chain-of-Thought, and RL data. On ForeLen, EGTP achieves state-of-the-art accuracy, reducing MAE by 29.16\% over the best baseline. Integrating our methods with a length-aware scheduler yields significant end-to-end throughput gains. Our work provides a new technical and evaluation baseline for efficient LLM inference.