RELATE: A Reinforcement Learning-Enhanced LLM Framework for Advertising Text Generation
作者: Jinfang Wang, Jiajie Liu, Jianwei Wu, Ziqin Luo, Zhen Chen, Chunlei Li, Biao Han, Tao Deng, Yi Li, Shuanglong Li, Lin Liu
分类: cs.AI
发布日期: 2026-02-12
备注: 10 pages, 3 figures
💡 一句话要点
提出RELATE框架,利用强化学习增强LLM,解决广告文本生成中目标不一致问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 广告文本生成 强化学习 大型语言模型 目标对齐 多维奖励
📋 核心要点
- 现有广告文本生成系统通常分两阶段进行,生成候选文本后再与点击率等指标对齐,导致优化目标不一致。
- RELATE框架通过强化学习将文本生成与目标对齐统一在一个模型中,直接在生成过程中整合性能和合规性目标。
- 实验表明,RELATE在点击转化率方面优于基线,并在实际广告平台上取得了显著提升,验证了框架的有效性。
📝 摘要(中文)
本文提出了一种基于强化学习的端到端框架RELATE,用于广告文本生成,旨在解决现有方法中生成和目标对齐分离导致的问题。RELATE通过策略学习将性能和合规性目标直接整合到生成过程中。为了更好地捕捉点击级别信号之外的最终广告商价值,该框架将转化导向的指标纳入目标,并将其与合规性约束一起建模为多维奖励,从而生成高质量的广告文本,在策略约束下提高转化效果。在大型工业数据集上的实验表明,RELATE始终优于基线方法。此外,在生产广告平台上的在线部署在严格的策略约束下,点击转化率(CTCVR)取得了显著的统计学改进,验证了所提出框架的鲁棒性和实际有效性。
🔬 方法详解
问题定义:现有在线广告文本生成系统通常采用两阶段方法,即先生成候选文本,然后根据点击率(CTR)等在线性能指标进行排序和选择。这种分离导致生成阶段的目标与最终的优化目标(如转化率)不一致,从而限制了全局最优性,降低了效率。此外,现有方法难以同时兼顾性能指标和合规性约束。
核心思路:RELATE的核心思路是将广告文本生成过程视为一个强化学习问题,通过策略学习直接优化最终的广告商价值,例如转化率。通过将性能指标(如点击率、转化率)和合规性约束建模为多维奖励,引导模型生成既能吸引用户点击,又能促进转化的广告文本,同时满足策略约束。
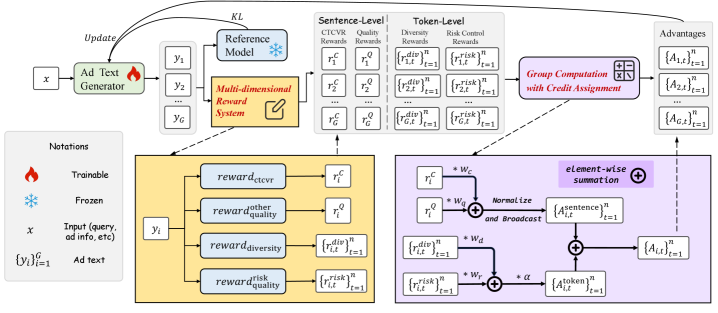
技术框架:RELATE是一个端到端的框架,包含以下主要模块:1) 基于LLM的文本生成器,作为强化学习的智能体,负责生成候选广告文本;2) 奖励函数,用于评估生成文本的质量,包括性能奖励(基于点击率、转化率等)和合规性奖励(基于策略约束);3) 强化学习算法,用于更新文本生成器的策略,使其能够生成更高质量的广告文本。整个框架通过不断迭代,优化文本生成策略,最终实现性能和合规性的平衡。
关键创新:RELATE的关键创新在于将强化学习引入广告文本生成领域,并提出了一种端到端的优化框架。与传统的两阶段方法相比,RELATE能够直接优化最终的广告商价值,避免了目标不一致的问题。此外,RELATE还能够同时兼顾性能指标和合规性约束,生成更符合要求的广告文本。
关键设计:RELATE的关键设计包括:1) 多维奖励函数的设计,需要仔细权衡不同性能指标和合规性约束的重要性;2) 强化学习算法的选择,需要考虑算法的收敛速度和稳定性;3) 文本生成器的结构设计,需要选择合适的LLM模型,并进行微调以适应广告文本生成的任务。具体而言,奖励函数可以设计为点击率、转化率和合规性得分的加权和,权重需要根据实际业务需求进行调整。强化学习算法可以选择Policy Gradient或Actor-Critic等算法。文本生成器可以使用预训练的Transformer模型,并在广告数据集上进行微调。
🖼️ 关键图片

📊 实验亮点
在大型工业数据集上的实验结果表明,RELATE框架始终优于基线方法。更重要的是,在实际的广告平台上进行在线部署后,在严格的策略约束下,RELATE在点击转化率(CTCVR)方面取得了显著的统计学改进,验证了该框架在实际应用中的有效性和鲁棒性。具体的提升幅度未知,但摘要中明确指出是“statistically significant improvements”。
🎯 应用场景
RELATE框架可应用于各种在线广告平台,用于生成高质量的广告文本,提高点击率、转化率等关键指标,并满足平台的合规性要求。该研究的成果有助于提升广告效果,为广告商带来更大的价值,并改善用户的广告体验。未来,该框架可以扩展到其他文本生成任务,例如商品描述生成、新闻标题生成等。
📄 摘要(原文)
In online advertising, advertising text plays a critical role in attracting user engagement and driving advertiser value. Existing industrial systems typically follow a two-stage paradigm, where candidate texts are first generated and subsequently aligned with online performance metrics such as click-through rate(CTR). This separation often leads to misaligned optimization objectives and low funnel efficiency, limiting global optimality. To address these limitations, we propose RELATE, a reinforcement learning-based end-to-end framework that unifies generation and objective alignment within a single model. Instead of decoupling text generation from downstream metric alignment, RELATE integrates performance and compliance objectives directly into the generation process via policy learning. To better capture ultimate advertiser value beyond click-level signals, We incorporate conversion-oriented metrics into the objective and jointly model them with compliance constraints as multi-dimensional rewards, enabling the model to generate high-quality ad texts that improve conversion performance under policy constraints. Extensive experiments on large-scale industrial datasets demonstrate that RELATE consistently outperforms baselines. Furthermore, online deployment on a production advertising platform yields statistically significant improvements in click-through conversion rate(CTCVR) under strict policy constraints, validating the robustness and real-world effectiveness of the proposed framework.