TSR: Trajectory-Search Rollouts for Multi-Turn RL of LLM Agents
作者: Aladin Djuhera, Swanand Ravindra Kadhe, Farhan Ahmed, Holger Boche
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-02-12
💡 一句话要点
TSR:用于LLM Agent多轮RL的轨迹搜索Rollout方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 多轮交互 轨迹搜索 Rollout生成 大型语言模型
📋 核心要点
- 多轮强化学习面临奖励稀疏、环境随机等挑战,传统轨迹采样易导致探索不足和模式崩溃。
- TSR通过在训练时进行轨迹搜索,选择高分动作构建高质量轨迹,提升rollout质量并稳定学习。
- 实验表明,TSR与PPO和GRPO结合,在多个任务上实现了显著的性能提升和更稳定的学习。
📝 摘要(中文)
大型语言模型(LLM)的进步正推动着使用强化学习(RL)来训练智能体,使其能够通过跨任务的迭代、多轮交互来学习。然而,多轮RL仍然具有挑战性,因为奖励通常是稀疏或延迟的,并且环境可能是随机的。在这种情况下,简单的轨迹采样会阻碍探索并导致模式崩溃。我们提出了TSR(轨迹搜索Rollout),这是一种训练时方法,它重新利用测试时缩放的思想来改进每轮rollout的生成。TSR执行轻量级的树状搜索,通过使用特定于任务的反馈选择每一轮中的高分动作来构建高质量的轨迹。这提高了rollout质量并稳定了学习,同时保持了底层优化目标不变,使TSR与优化器无关。我们将TSR实例化为best-of-N、beam和浅层前瞻搜索,并将其与PPO和GRPO配对,在Sokoban、FrozenLake和WebShop任务上实现了高达15%的性能提升和更稳定的学习,同时仅增加了一次性的训练计算量。通过将搜索从推理时间转移到训练的rollout阶段,TSR为更强大的多轮智能体学习提供了一种简单而通用的机制,是对现有框架和拒绝采样式选择方法的补充。
🔬 方法详解
问题定义:论文旨在解决多轮强化学习中,由于奖励稀疏或延迟以及环境随机性,导致传统轨迹采样方法在探索和利用方面表现不佳的问题。现有方法容易陷入局部最优,难以有效学习到长期策略。
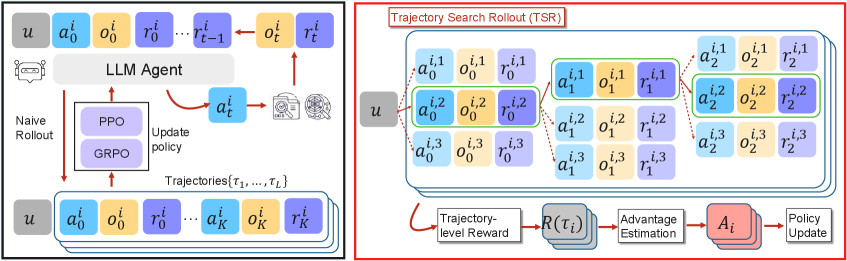
核心思路:论文的核心思路是在训练阶段引入轨迹搜索,通过轻量级的树状搜索,在每一步选择更有希望的动作,从而生成更高质量的训练轨迹。这样可以更有效地探索环境,避免模式崩溃,并加速学习过程。
技术框架:TSR方法主要包含以下几个阶段:1) 在每个时间步,智能体根据当前策略生成多个候选动作;2) 使用任务特定的反馈(例如奖励或价值函数)对这些动作进行评分;3) 通过best-of-N、beam search或shallow lookahead search等搜索策略,选择得分最高的动作;4) 将选择的动作加入到轨迹中,用于后续的策略优化。整个框架与底层优化器(如PPO、GRPO)解耦,可以灵活地与不同的优化算法结合使用。
关键创新:TSR的关键创新在于将搜索过程从推理阶段转移到训练阶段的rollout生成阶段。这种做法的优势在于,可以在训练时利用更多的计算资源来探索更好的轨迹,从而提高学习效率和最终性能。与传统的拒绝采样方法相比,TSR通过搜索来主动构建高质量轨迹,而不是被动地筛选轨迹。
关键设计:TSR的具体实现包括以下几个关键设计:1) 搜索策略的选择:论文尝试了best-of-N、beam search和shallow lookahead search等不同的搜索策略,以平衡计算复杂度和搜索效果;2) 任务特定反馈的设计:论文强调使用任务特定的反馈信号来指导搜索过程,例如奖励函数或价值函数;3) 与现有优化算法的集成:TSR被设计成与现有的强化学习优化算法(如PPO、GRPO)兼容,可以方便地集成到现有的训练流程中。
🖼️ 关键图片

📊 实验亮点
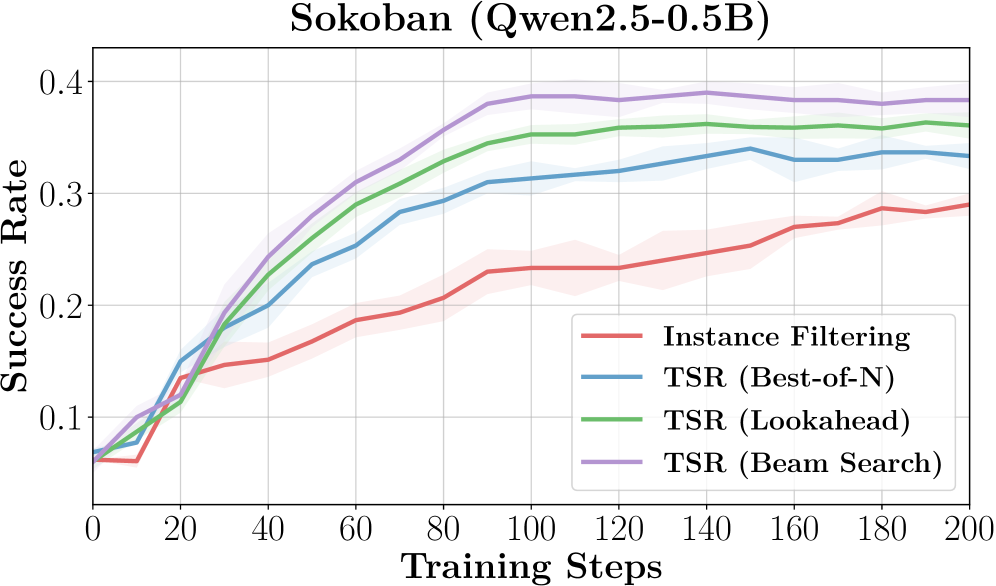
实验结果表明,TSR在Sokoban、FrozenLake和WebShop等多个任务上均取得了显著的性能提升。例如,在某些任务上,TSR可以将性能提高高达15%。此外,TSR还能够提高学习的稳定性,减少训练过程中的波动。这些结果表明,TSR是一种有效的多轮强化学习训练方法。
🎯 应用场景
TSR方法具有广泛的应用前景,可以应用于各种需要多轮交互的强化学习任务,例如机器人控制、游戏AI、对话系统和推荐系统等。通过提高训练效率和最终性能,TSR可以帮助开发更智能、更可靠的智能体,从而在实际应用中发挥更大的作用。
📄 摘要(原文)
Advances in large language models (LLMs) are driving a shift toward using reinforcement learning (RL) to train agents from iterative, multi-turn interactions across tasks. However, multi-turn RL remains challenging as rewards are often sparse or delayed, and environments can be stochastic. In this regime, naive trajectory sampling can hinder exploitation and induce mode collapse. We propose TSR (Trajectory-Search Rollouts), a training-time approach that repurposes test-time scaling ideas for improved per-turn rollout generation. TSR performs lightweight tree-style search to construct high-quality trajectories by selecting high-scoring actions at each turn using task-specific feedback. This improves rollout quality and stabilizes learning while leaving the underlying optimization objective unchanged, making TSR optimizer-agnostic. We instantiate TSR with best-of-N, beam, and shallow lookahead search, and pair it with PPO and GRPO, achieving up to 15% performance gains and more stable learning on Sokoban, FrozenLake, and WebShop tasks at a one-time increase in training compute. By moving search from inference time to the rollout stage of training, TSR provides a simple and general mechanism for stronger multi-turn agent learning, complementary to existing frameworks and rejection-sampling-style selection methods.