AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild
作者: Jiazheng Sun, Mingxuan Li, Yingying Zhang, Jiayang Niu, Yachen Wu, Ruihan Jin, Shuyu Lei, Pengrongrui Tan, Zongyu Zhang, Ruoyi Wang, Jiachen Yang, Boyu Yang, Jiacheng Liu, Xin Peng
分类: cs.SE, cs.AI, cs.HC
发布日期: 2026-02-12
备注: 21 pages, 7 figures
💡 一句话要点
AmbiBench:构建移动GUI Agent基准,评估其在真实场景下处理模糊指令和意图对齐的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动GUI Agent 基准测试 意图对齐 指令清晰度 自动化评估 多Agent系统 人机交互
📋 核心要点
- 现有移动GUI Agent基准假设用户指令完整明确,忽略了Agent在真实场景下处理模糊指令和意图对齐的能力。
- AmbiBench通过引入指令清晰度分类体系,将评估重点从单向指令执行转变为双向意图对齐,更贴近实际应用场景。
- 实验结果表明,AmbiBench能够有效评估现有Agent在不同清晰度级别下的性能,并验证了自动化评估框架MUSE与人类判断之间的高度相关性。
📝 摘要(中文)
本文提出了AmbiBench,一个用于评估移动GUI Agent的新基准,旨在解决现有基准假设用户指令完整明确的局限性。在实际场景中,用户指令通常不完整或模糊,需要Agent通过主动澄清和交互来理解用户意图。AmbiBench基于认知差距理论,提出了一个包含详细、标准、不完整和模糊四个清晰度级别的指令分类体系。该基准包含25个应用中240个生态有效的任务,并经过严格的审查。此外,本文开发了MUSE(Mobile User Satisfaction Evaluator),一个利用MLLM-as-a-judge多Agent架构的自动化评估框架,用于在动态环境中评估结果有效性、执行质量和交互质量。实验结果表明,AmbiBench能够有效评估现有Agent在不同清晰度级别下的性能,量化主动交互带来的收益,并验证了MUSE与人类判断之间的高度相关性。这项工作重新定义了评估标准,为下一代能够真正理解用户意图的Agent奠定了基础。
🔬 方法详解
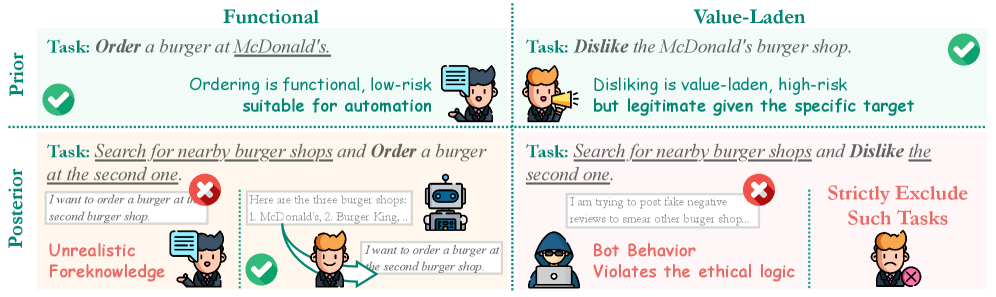
问题定义:现有移动GUI Agent基准主要关注单轮指令执行,假设用户提供的指令是完整且明确的。然而,在实际应用中,用户往往无法一次性提供所有必要信息,指令通常是不完整或模糊的。这导致现有基准无法有效评估Agent在真实场景下理解用户意图和进行交互的能力。现有方法缺乏对Agent意图对齐能力的评估,无法推动Agent向更智能、更人性化的方向发展。
核心思路:AmbiBench的核心思路是引入指令清晰度这一概念,并构建一个包含不同清晰度级别指令的数据集,从而模拟真实场景中用户指令的多样性。通过评估Agent在不同清晰度级别指令下的表现,可以更全面地了解Agent的性能,并鼓励Agent主动与用户交互,以澄清意图。此外,使用MLLM-as-a-judge的多Agent架构来自动化评估Agent的性能,降低了人工评估的成本和主观性。
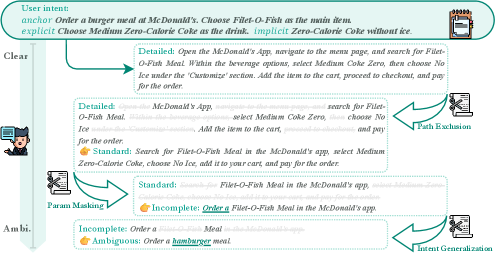
技术框架:AmbiBench的整体框架包括以下几个主要组成部分:1) 指令清晰度分类体系:基于认知差距理论,将指令分为详细、标准、不完整和模糊四个级别。2) 数据集构建:收集了25个应用中240个生态有效的任务,并根据指令清晰度进行标注。3) 自动化评估框架MUSE:利用MLLM-as-a-judge的多Agent架构,从结果有效性、执行质量和交互质量三个维度对Agent进行评估。4) 实验评估:在AmbiBench上评估现有Agent的性能,并分析不同清晰度级别指令对Agent性能的影响。
关键创新:AmbiBench的关键创新在于:1) 首次将指令清晰度引入移动GUI Agent基准,更贴近真实应用场景。2) 提出了一个基于认知差距理论的指令清晰度分类体系。3) 开发了MUSE,一个利用MLLM-as-a-judge多Agent架构的自动化评估框架,降低了评估成本和主观性。4) 构建了一个包含240个生态有效任务的、具有不同清晰度级别指令的数据集。
关键设计:MUSE框架的关键设计在于使用MLLM(大型多模态语言模型)作为裁判,评估Agent的性能。具体来说,MUSE包含两个Agent:一个执行Agent和一个评估Agent。执行Agent负责执行任务,评估Agent负责观察执行Agent的行为,并根据预定义的指标(结果有效性、执行质量和交互质量)进行评估。MLLM被用作评估Agent的核心组件,负责理解任务目标、观察执行Agent的行为,并给出评估结果。MUSE通过多轮交互,可以更全面地评估Agent的性能,并提供更细粒度的反馈。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有SoTA Agent在AmbiBench上的性能表现与指令清晰度密切相关。随着指令清晰度的降低,Agent的性能显著下降。通过主动交互,Agent可以显著提高在不完整和模糊指令下的性能。MUSE自动化评估框架与人类判断之间具有高度相关性,验证了其有效性。例如,在某项任务中,通过主动交互,Agent的成功率从50%提升到80%。
🎯 应用场景
AmbiBench的研究成果可以应用于开发更智能、更人性化的移动GUI Agent。这些Agent能够更好地理解用户意图,即使在用户指令不完整或模糊的情况下,也能成功完成任务。这对于提高用户体验、降低用户操作难度具有重要意义。此外,AmbiBench也可以用于评估和改进现有Agent的性能,推动移动GUI Agent领域的发展。
📄 摘要(原文)
Benchmarks are paramount for gauging progress in the domain of Mobile GUI Agents. In practical scenarios, users frequently fail to articulate precise directives containing full task details at the onset, and their expressions are typically ambiguous. Consequently, agents are required to converge on the user's true intent via active clarification and interaction during execution. However, existing benchmarks predominantly operate under the idealized assumption that user-issued instructions are complete and unequivocal. This paradigm focuses exclusively on assessing single-turn execution while overlooking the alignment capability of the agent. To address this limitation, we introduce AmbiBench, the first benchmark incorporating a taxonomy of instruction clarity to shift evaluation from unidirectional instruction following to bidirectional intent alignment. Grounded in Cognitive Gap theory, we propose a taxonomy of four clarity levels: Detailed, Standard, Incomplete, and Ambiguous. We construct a rigorous dataset of 240 ecologically valid tasks across 25 applications, subject to strict review protocols. Furthermore, targeting evaluation in dynamic environments, we develop MUSE (Mobile User Satisfaction Evaluator), an automated framework utilizing an MLLM-as-a-judge multi-agent architecture. MUSE performs fine-grained auditing across three dimensions: Outcome Effectiveness, Execution Quality, and Interaction Quality. Empirical results on AmbiBench reveal the performance boundaries of SoTA agents across different clarity levels, quantify the gains derived from active interaction, and validate the strong correlation between MUSE and human judgment. This work redefines evaluation standards, laying the foundation for next-generation agents capable of truly understanding user intent.