Text2GQL-Bench: A Text to Graph Query Language Benchmark [Experiment, Analysis & Benchmark]
作者: Songlin Lyu, Lujie Ban, Zihang Wu, Tianqi Luo, Jirong Liu, Chenhao Ma, Yuyu Luo, Nan Tang, Shipeng Qi, Heng Lin, Yongchao Liu, Chuntao Hong
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出Text2GQL-Bench,用于评估和提升文本到图查询语言的转换性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图查询语言 Text-to-GQL 基准数据集 图数据库 大型语言模型
📋 核心要点
- 现有Text-to-GQL数据集在领域覆盖、查询语言支持和评估范围上存在局限性,阻碍了模型能力的系统性比较。
- Text2GQL-Bench通过构建多GQL数据集和可扩展的生成框架,支持在不同领域、抽象级别和GQL上进行评估。
- 提出的评估方法超越了单一指标,联合评估语法有效性、相似性、语义对齐和执行准确性,更全面地衡量模型性能。
📝 摘要(中文)
图模型在复杂关系的数据分析中至关重要。文本到图查询语言(Text-to-GQL)系统充当翻译器,将自然语言转换为可执行的图查询。这种能力使大型语言模型(LLMs)能够直接分析和操作图数据,使其成为图数据库管理系统(GDBMS)的强大代理基础设施。然而,现有数据集在领域覆盖范围、支持的图查询语言或评估范围方面通常受到限制。缺乏高质量的基准数据集和评估方法来系统地比较不同图查询语言和领域中的模型能力,阻碍了Text-to-GQL系统的发展。本文提出了Text2GQL-Bench,这是一个统一的Text-to-GQL基准,旨在解决这些限制。Text2GQL-Bench包含一个多GQL数据集,该数据集具有跨越13个领域的178,184个(问题,查询)对,以及一个可扩展的构建框架,该框架可以在不同的领域、问题抽象级别和具有异构资源的GQL中生成数据集。为了支持全面的评估,我们引入了一种评估方法,该方法超越了单一的端到端指标,而是联合报告语法有效性、相似性、语义对齐和执行准确性。我们的评估揭示了ISO-GQL生成中存在的明显方言差距:即使是强大的LLM在零样本设置中也只能达到最多4%的执行准确率(EX),尽管固定的3-shot提示将准确率提高到50%左右,但语法有效性仍低于70%。此外,经过微调的8B开放权重模型达到了45.1%的EX和90.8%的语法有效性,表明大部分性能提升是通过接触足够的ISO-GQL示例来实现的。
🔬 方法详解
问题定义:论文旨在解决Text-to-GQL领域缺乏高质量、多领域、多GQL支持的基准数据集的问题。现有数据集无法充分评估LLM在不同图查询语言和领域中的能力,阻碍了Text-to-GQL系统的发展。现有评估方法也过于简单,无法全面衡量模型性能。
核心思路:论文的核心思路是构建一个统一的Text-to-GQL基准,包含一个大规模、多领域的GQL数据集,并设计一个可扩展的生成框架,以支持在不同维度上生成数据集。同时,提出一种更全面的评估方法,从多个角度评估模型性能。
技术框架:Text2GQL-Bench包含两个主要组成部分:多GQL数据集和可扩展的构建框架。多GQL数据集包含178,184个(Question, Query)对,涵盖13个领域。可扩展的构建框架允许在不同的领域、问题抽象级别和具有异构资源的GQL中生成数据集。评估方法包括语法有效性、相似性、语义对齐和执行准确性四个指标。
关键创新:该论文的关键创新在于构建了一个统一的、多领域的Text-to-GQL基准数据集,并提出了一种更全面的评估方法。该基准数据集和评估方法可以用于系统地比较不同模型在不同图查询语言和领域中的能力。
关键设计:在数据集构建方面,论文设计了一个可扩展的生成框架,允许在不同的领域、问题抽象级别和具有异构资源的GQL中生成数据集。在评估方面,论文提出了语法有效性、相似性、语义对齐和执行准确性四个指标,以更全面地评估模型性能。论文还分析了不同prompting策略和微调对模型性能的影响。
🖼️ 关键图片
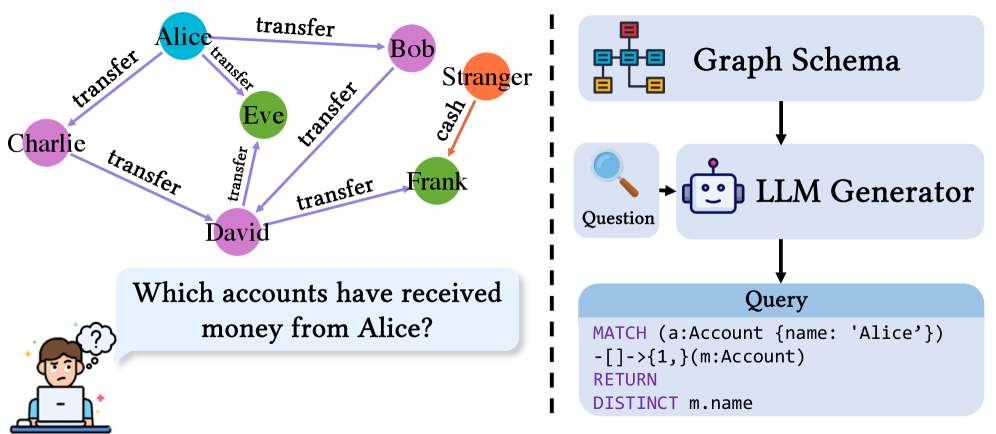
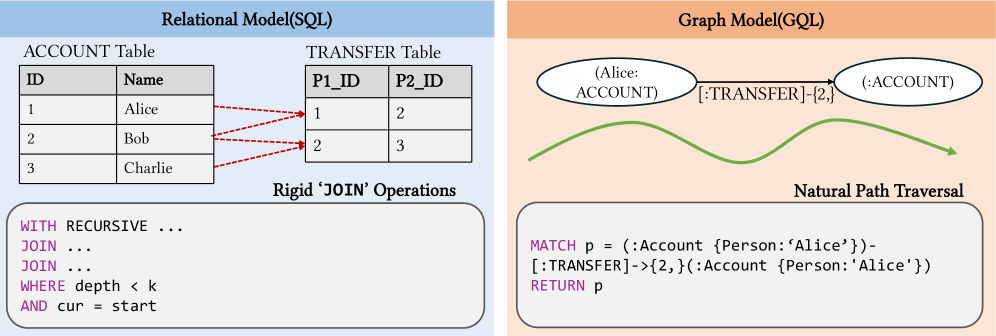
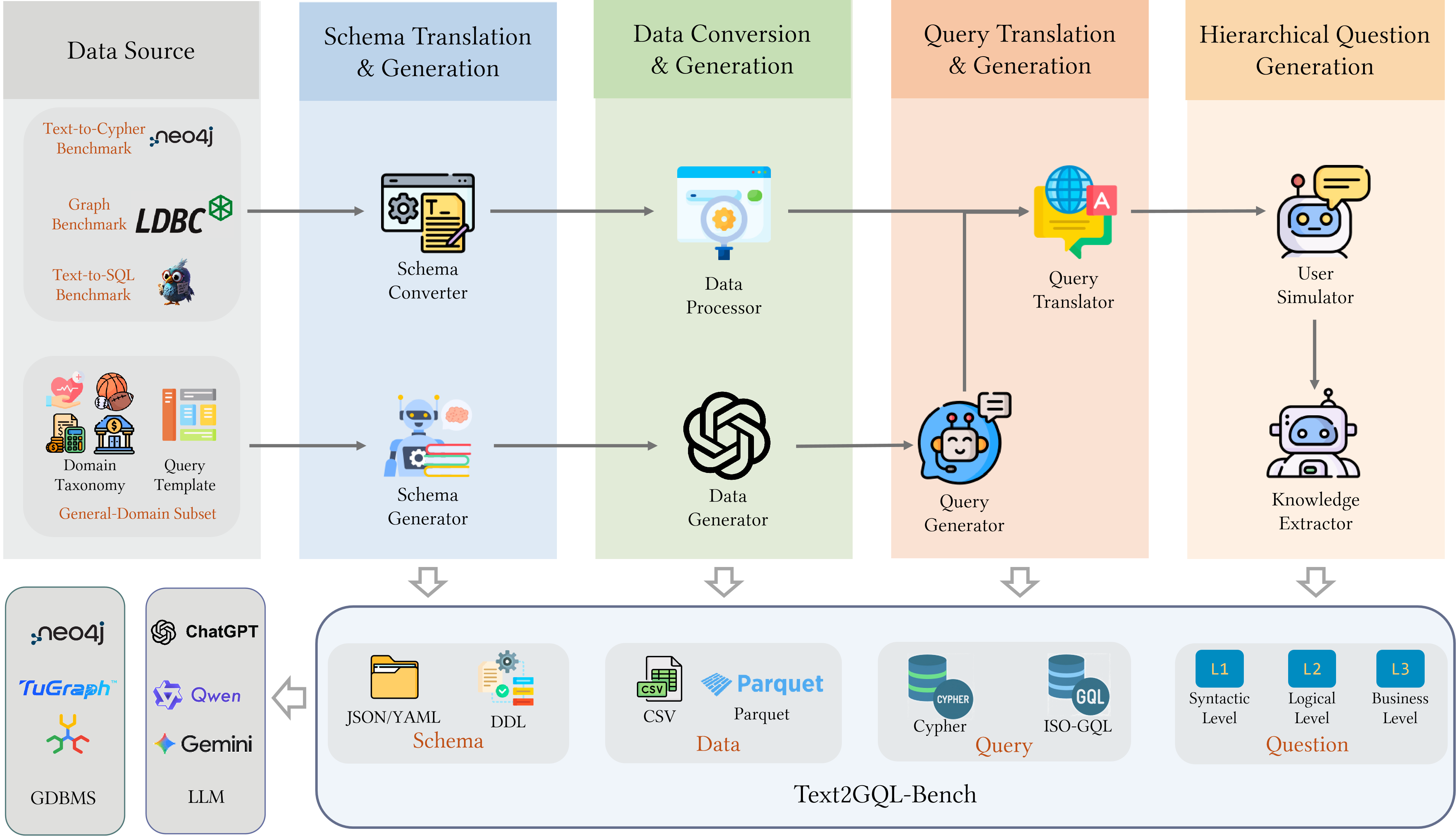
📊 实验亮点
实验结果表明,即使是强大的LLM在零样本设置下,在ISO-GQL生成中也只能达到最多4%的执行准确率。通过3-shot prompting,准确率可以提高到50%左右,但语法有效性仍然较低。经过微调的8B开放权重模型达到了45.1%的执行准确率和90.8%的语法有效性,表明通过接触足够的ISO-GQL示例可以显著提高模型性能。
🎯 应用场景
Text2GQL-Bench可用于评估和提升LLM在图数据分析和操作方面的能力,应用于智能问答、知识图谱查询、数据挖掘等领域。该基准数据集和评估方法可以促进Text-to-GQL系统的发展,并推动LLM在图数据库管理系统中的应用。
📄 摘要(原文)
Graph models are fundamental to data analysis in domains rich with complex relationships. Text-to-Graph-Query-Language (Text-to-GQL) systems act as a translator, converting natural language into executable graph queries. This capability allows Large Language Models (LLMs) to directly analyze and manipulate graph data, posi-tioning them as powerful agent infrastructures for Graph Database Management System (GDBMS). Despite recent progress, existing datasets are often limited in domain coverage, supported graph query languages, or evaluation scope. The advancement of Text-to-GQL systems is hindered by the lack of high-quality benchmark datasets and evaluation methods to systematically compare model capabilities across different graph query languages and domains. In this work, we present Text2GQL-Bench, a unified Text-to-GQL benchmark designed to address these limitations. Text2GQL-Bench couples a multi-GQL dataset that has 178,184 (Question, Query) pairs spanning 13 domains, with a scalable construction framework that generates datasets in different domains, question abstraction levels, and GQLs with heterogeneous resources. To support compre-hensive assessment, we introduce an evaluation method that goes beyond a single end-to-end metric by jointly reporting grammatical validity, similarity, semantic alignment, and execution accuracy. Our evaluation uncovers a stark dialect gap in ISO-GQL generation: even strong LLMs achieve only at most 4% execution accuracy (EX) in zero-shot settings, though a fixed 3-shot prompt raises accuracy to around 50%, the grammatical validity remains lower than 70%. Moreover, a fine-tuned 8B open-weight model reaches 45.1% EX, and 90.8% grammatical validity, demonstrating that most of the performance jump is unlocked by exposure to sufficient ISO-GQL examples.