Provable Offline Reinforcement Learning for Structured Cyclic MDPs
作者: Kyungbok Lee, Angelica Cristello Sarteau, Michael R. Kosorok
分类: stat.ML, cs.AI, cs.LG, math.OC, stat.ME
发布日期: 2026-02-12
备注: 65 pages, 4 figures. Submitted to JMLR
💡 一句话要点
提出CycleFQI,解决结构化循环MDPs的离线强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 循环MDP Fitted Q-Iteration 阶段分解 1型糖尿病
📋 核心要点
- 循环MDPs的离线学习面临挑战,因为优化策略会改变后续阶段的状态分布,导致不匹配。
- CycleFQI将循环过程分解为阶段性子问题,使用阶段特定的Q函数向量,实现模块化设计和部分控制。
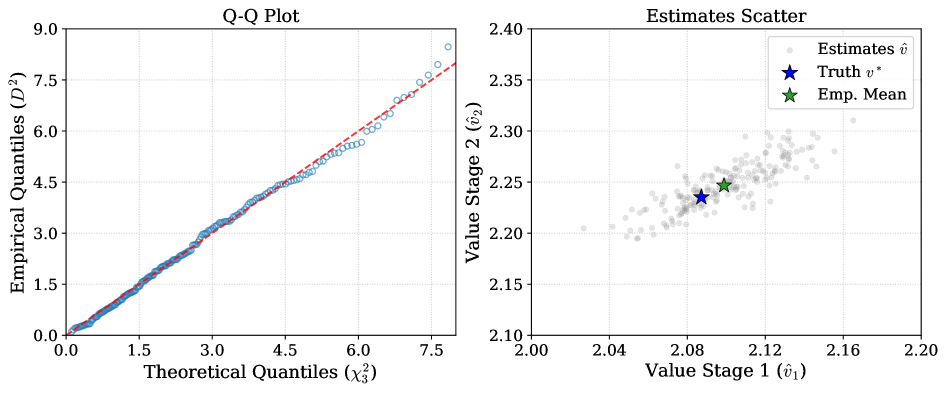
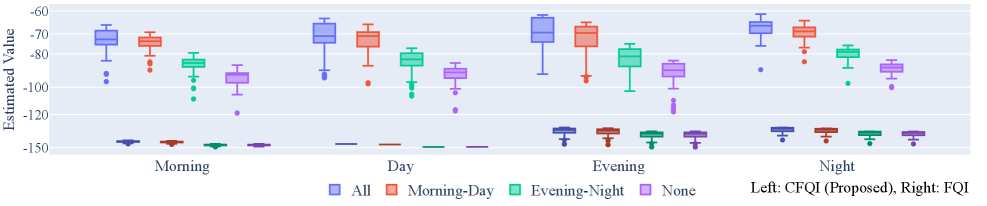
- CycleFQI在理论上具有有限样本误差界限和全局收敛速度,实验表明其在模拟和真实数据上有效。
📝 摘要(中文)
本文提出了一种新颖的循环马尔可夫决策过程(MDP)框架,用于解决具有异构阶段特定动态、转移和折扣因子的多步决策问题。在这种设置下,离线学习面临挑战:在任何阶段优化策略都会改变后续阶段的状态分布,从而导致整个循环过程中的不匹配。为了解决这个问题,我们提出了一个模块化的结构框架,将循环过程分解为阶段性的子问题。虽然该框架具有普遍适用性,但我们将其具体化为CycleFQI,它是fitted Q-iteration的扩展,支持理论分析和解释。CycleFQI使用一个阶段特定的Q函数向量,专门为每个阶段定制,以捕获阶段内的序列和阶段之间的转移。这种模块化设计实现了部分控制,允许优化某些阶段,而其他阶段遵循预定义的策略。我们建立了有限样本次优性误差界限,并在Besov正则性下推导了全局收敛速度,证明CycleFQI减轻了与单片基线相比的维度灾难。此外,我们提出了一种基于筛法的渐近推理方法,用于在边际条件下推断最优策略值。在模拟和真实世界的1型糖尿病数据集上的实验证明了CycleFQI的有效性。
🔬 方法详解
问题定义:论文旨在解决结构化循环马尔可夫决策过程(MDPs)中的离线强化学习问题。传统的强化学习方法难以处理这种循环结构,因为在一个阶段的策略改变会影响后续阶段的状态分布,导致训练不稳定和性能下降。现有的离线强化学习方法通常假设环境是静态的,无法很好地适应这种动态变化的环境。
核心思路:论文的核心思路是将循环MDP分解为一系列阶段性的子问题,每个阶段都有自己的Q函数。通过这种模块化的设计,可以独立地优化每个阶段的策略,同时考虑阶段之间的转移关系。这种分解方法能够有效地缓解策略改变带来的状态分布偏移问题,提高学习的稳定性和效率。
技术框架:CycleFQI的技术框架主要包括以下几个模块:1) 阶段分解:将循环MDP分解为多个阶段,每个阶段对应一个子问题。2) 阶段特定Q函数:为每个阶段定义一个独立的Q函数,用于评估在该阶段采取特定动作的价值。3) Fitted Q-Iteration:使用fitted Q-iteration算法迭代更新每个阶段的Q函数,利用离线数据进行学习。4) 阶段间转移:考虑阶段之间的转移关系,确保每个阶段的策略能够有效地引导状态转移到下一个阶段。
关键创新:CycleFQI的关键创新在于其模块化的结构和阶段特定的Q函数设计。与传统的单片式Q函数相比,CycleFQI能够更好地捕捉循环MDP中各个阶段的动态特性,从而提高学习的效率和性能。此外,论文还提供了理论分析,证明了CycleFQI的有限样本误差界限和全局收敛速度。
关键设计:CycleFQI的关键设计包括:1) 阶段分解策略:如何将循环MDP分解为合适的阶段,需要根据具体问题进行设计。2) Q函数的表示形式:可以使用神经网络或其他函数逼近器来表示Q函数。3) 损失函数:使用均方误差或其他合适的损失函数来训练Q函数。4) 优化算法:使用梯度下降或其他优化算法来更新Q函数的参数。5) Besov正则性假设:为了保证理论分析的有效性,论文假设Q函数满足Besov正则性条件。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CycleFQI在模拟和真实世界的1型糖尿病数据集上都取得了显著的性能提升。与单片基线方法相比,CycleFQI能够更好地适应循环MDP的动态特性,降低维度灾难的影响,并获得更优的策略。
🎯 应用场景
该研究成果可应用于具有循环特性的决策问题,例如医疗健康领域中对1型糖尿病患者的血糖控制,以及供应链管理、机器人控制等领域。通过学习历史数据,可以优化每个阶段的决策策略,从而提高整体性能和效率,具有重要的实际应用价值。
📄 摘要(原文)
We introduce a novel cyclic Markov decision process (MDP) framework for multi-step decision problems with heterogeneous stage-specific dynamics, transitions, and discount factors across the cycle. In this setting, offline learning is challenging: optimizing a policy at any stage shifts the state distributions of subsequent stages, propagating mismatch across the cycle. To address this, we propose a modular structural framework that decomposes the cyclic process into stage-wise sub-problems. While generally applicable, we instantiate this principle as CycleFQI, an extension of fitted Q-iteration enabling theoretical analysis and interpretation. It uses a vector of stage-specific Q-functions, tailored to each stage, to capture within-stage sequences and transitions between stages. This modular design enables partial control, allowing some stages to be optimized while others follow predefined policies. We establish finite-sample suboptimality error bounds and derive global convergence rates under Besov regularity, demonstrating that CycleFQI mitigates the curse of dimensionality compared to monolithic baselines. Additionally, we propose a sieve-based method for asymptotic inference of optimal policy values under a margin condition. Experiments on simulated and real-world Type 1 Diabetes data sets demonstrate CycleFQI's effectiveness.