Do MLLMs Really Understand Space? A Mathematical Reasoning Evaluation
作者: Shuo Lu, Jianjie Cheng, Yinuo Xu, Yongcan Yu, Lijun Sheng, Peijie Wang, Siru Jiang, Yongguan Hu, Run Ling, Yihua Shao, Ao Ma, Wei Feng, Lingxiao He, Meng Wang, Qianlong Xie, Xingxing Wang, Ran He, Jian Liang
分类: cs.AI
发布日期: 2026-02-12
💡 一句话要点
MathSpatial:用于评估和提升多模态大语言模型空间数学推理能力的统一框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 空间推理 数学推理 基准测试 结构化推理 模型评估 Qwen2.5-VL-7B
📋 核心要点
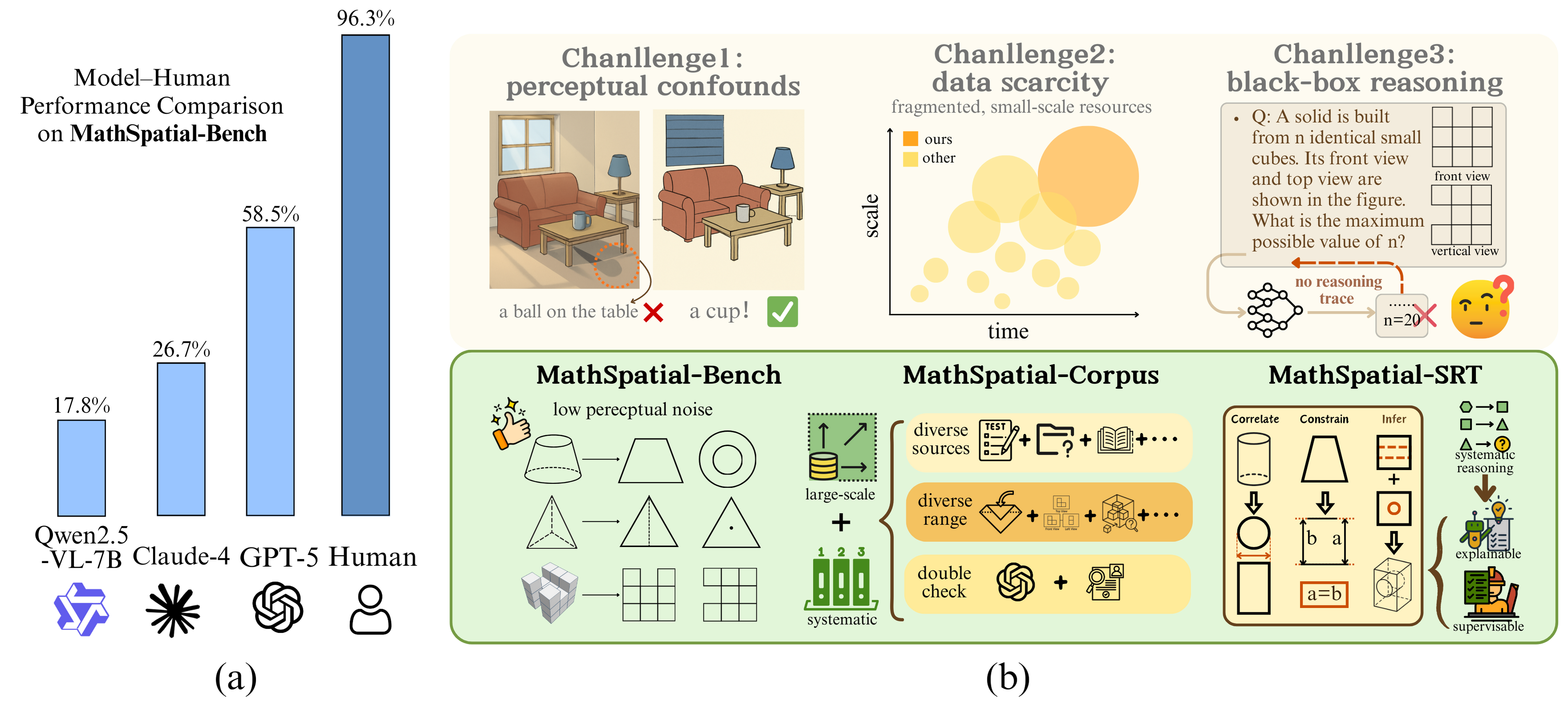
- 现有MLLMs在空间数学推理方面存在显著不足,与人类表现差距明显,难以有效解析和操作二维/三维空间关系。
- 论文提出MathSpatial框架,包含基准测试、训练数据集和结构化推理轨迹,旨在评估和提升MLLMs的空间推理能力。
- 实验表明,在MathSpatial上微调Qwen2.5-VL-7B模型,能够在保证准确率的同时,显著减少tokens的使用。
📝 摘要(中文)
多模态大语言模型(MLLMs)在感知任务上表现出色,但其执行数学空间推理的能力,即解析和操作二维和三维关系的能力,仍不清楚。人类可以轻松解决教科书式的空间推理问题,准确率超过95%,但我们发现,大多数领先的MLLMs在相同的任务上甚至无法达到60%。这种显著的差距凸显了空间推理是当前模型的一个根本弱点。为了研究这一差距,我们提出了MathSpatial,一个用于评估和改进MLLMs空间推理的统一框架。MathSpatial包括三个互补的组件:(i) MathSpatial-Bench,一个包含2K问题的基准测试,涵盖三个类别和十一个子类型,旨在将推理难度与感知噪声隔离开来;(ii) MathSpatial-Corpus,一个包含8K额外问题的训练数据集,并附有验证过的解决方案;(iii) MathSpatial-SRT,它将推理建模为由三个原子操作(关联、约束和推断)组成的结构化轨迹。实验表明,在MathSpatial上微调Qwen2.5-VL-7B可以实现具有竞争力的准确率,同时减少25%的tokens。MathSpatial提供了第一个大规模资源,将感知与推理分离,从而能够精确测量和全面理解MLLMs中的数学空间推理。
🔬 方法详解
问题定义:现有MLLMs在数学空间推理方面表现不佳,无法达到人类水平,尤其是在处理涉及二维和三维关系的问题时。现有的模型往往将感知和推理混淆,难以准确评估模型的推理能力。因此,需要一个专门的框架来隔离感知噪声,并专注于评估和提升模型的空间推理能力。
核心思路:论文的核心思路是将空间推理问题分解为一系列原子操作,包括关联(Correlate)、约束(Constrain)和推断(Infer)。通过构建结构化的推理轨迹(SRT),可以更清晰地理解模型的推理过程,并针对性地进行改进。同时,通过构建专门的基准测试和训练数据集,可以更好地评估和训练模型的空间推理能力。
技术框架:MathSpatial框架包含三个主要组成部分:MathSpatial-Bench、MathSpatial-Corpus和MathSpatial-SRT。MathSpatial-Bench是一个包含2K问题的基准测试,涵盖三个类别和十一个子类型,用于评估模型的空间推理能力。MathSpatial-Corpus是一个包含8K额外问题的训练数据集,并附有验证过的解决方案,用于训练模型。MathSpatial-SRT将推理建模为由三个原子操作(关联、约束和推断)组成的结构化轨迹,用于分析和改进模型的推理过程。
关键创新:MathSpatial的关键创新在于它提供了一个统一的框架,将感知与推理分离,从而能够精确测量和全面理解MLLMs中的数学空间推理。此外,MathSpatial-SRT通过将推理建模为结构化轨迹,可以更清晰地理解模型的推理过程,并针对性地进行改进。
关键设计:MathSpatial-Bench的设计旨在隔离推理难度与感知噪声,确保评估结果的准确性。MathSpatial-Corpus包含大量高质量的训练数据,并附有验证过的解决方案,可以有效提升模型的空间推理能力。MathSpatial-SRT的设计基于三个原子操作(关联、约束和推断),可以灵活地表示各种空间推理问题。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在MathSpatial上微调Qwen2.5-VL-7B模型,能够在保证准确率的同时,减少25%的tokens的使用。这表明MathSpatial框架可以有效提升MLLMs的空间推理能力,并提高模型的效率。此外,MathSpatial-Bench提供了一个标准化的评估平台,可以方便地比较不同模型的性能。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域,提升机器在复杂空间环境中的理解和决策能力。通过提高MLLMs的空间推理能力,可以实现更智能、更可靠的自动化系统,例如在仓库管理、物流配送和智能家居等场景中。
📄 摘要(原文)
Multimodal large language models (MLLMs) have achieved strong performance on perception-oriented tasks, yet their ability to perform mathematical spatial reasoning, defined as the capacity to parse and manipulate two- and three-dimensional relations, remains unclear. Humans easily solve textbook-style spatial reasoning problems with over 95\% accuracy, but we find that most leading MLLMs fail to reach even 60\% on the same tasks. This striking gap highlights spatial reasoning as a fundamental weakness of current models. To investigate this gap, we present MathSpatial, a unified framework for evaluating and improving spatial reasoning in MLLMs. MathSpatial includes three complementary components: (i) MathSpatial-Bench, a benchmark of 2K problems across three categories and eleven subtypes, designed to isolate reasoning difficulty from perceptual noise; (ii) MathSpatial-Corpus, a training dataset of 8K additional problems with verified solutions; and (iii) MathSpatial-SRT, which models reasoning as structured traces composed of three atomic operations--Correlate, Constrain, and Infer. Experiments show that fine-tuning Qwen2.5-VL-7B on MathSpatial achieves competitive accuracy while reducing tokens by 25\%. MathSpatial provides the first large-scale resource that disentangles perception from reasoning, enabling precise measurement and comprehensive understanding of mathematical spatial reasoning in MLLMs.