scPilot: Large Language Model Reasoning Toward Automated Single-Cell Analysis and Discovery
作者: Yiming Gao, Zhen Wang, Jefferson Chen, Mark Antkowiak, Mengzhou Hu, JungHo Kong, Dexter Pratt, Jieyuan Liu, Enze Ma, Zhiting Hu, Eric P. Xing
分类: cs.AI, q-bio.GN
发布日期: 2026-02-12
备注: Accepted at NeurIPS 2025 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
scPilot:利用大语言模型推理实现自动化单细胞分析与发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单细胞分析 大语言模型 组学原生推理 自动化分析 可解释性 细胞类型注释 发育轨迹重建
📋 核心要点
- 现有单细胞分析方法缺乏可解释性和自动化能力,难以有效利用海量组学数据进行知识发现。
- scPilot通过构建组学原生推理框架,使LLM能够直接分析单细胞数据并调用生物信息学工具,实现自动化分析。
- 实验表明,scPilot在细胞类型注释和发育轨迹重建等任务上显著提升了准确率和效率,并提供了可解释的推理过程。
📝 摘要(中文)
我们提出了scPilot,这是第一个实践组学原生推理的系统框架:一个大型语言模型(LLM)以自然语言进行交互,同时直接检查单细胞RNA-seq数据和按需生物信息学工具。scPilot将核心单细胞分析(即细胞类型注释、发育轨迹重建和转录因子靶向)转换为模型必须解决、证明并在需要时用新证据修正的逐步推理问题。为了衡量进展,我们发布了scBench,这是一套由专家策划的9个数据集和评分器,用于忠实地评估scPilot关于各种LLM的组学原生推理能力。使用o1的实验表明,迭代组学原生推理将细胞类型注释的平均准确率提高了11%,而Gemini-2.5-Pro将轨迹图编辑距离比一次性提示减少了30%,同时生成透明的推理轨迹解释了标记基因的模糊性和调控逻辑。通过将LLM扎根于原始组学数据中,scPilot实现了可审计、可解释和具有诊断信息的单细胞分析。
🔬 方法详解
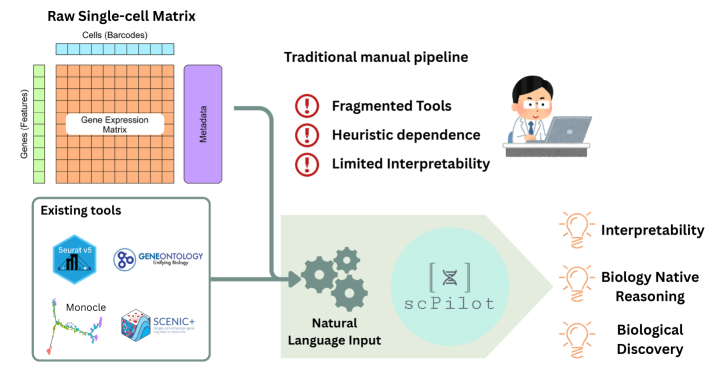
问题定义:单细胞RNA测序(scRNA-seq)数据分析面临着高维度、复杂性和异质性的挑战。现有的分析方法,如细胞类型注释、发育轨迹重建和转录因子靶向,通常需要人工干预和专业知识,缺乏自动化和可解释性,难以充分利用海量数据进行知识发现。现有方法的痛点在于无法有效整合领域知识和数据驱动的分析,导致结果的可信度和可重复性受到限制。
核心思路:scPilot的核心思路是将单细胞分析任务转化为LLM可以理解和解决的推理问题。通过将LLM与原始组学数据和生物信息学工具连接起来,scPilot使LLM能够像生物学家一样进行数据探索、假设验证和结果解释。这种组学原生推理方法旨在弥合领域知识和数据分析之间的差距,提高单细胞分析的自动化程度和可解释性。
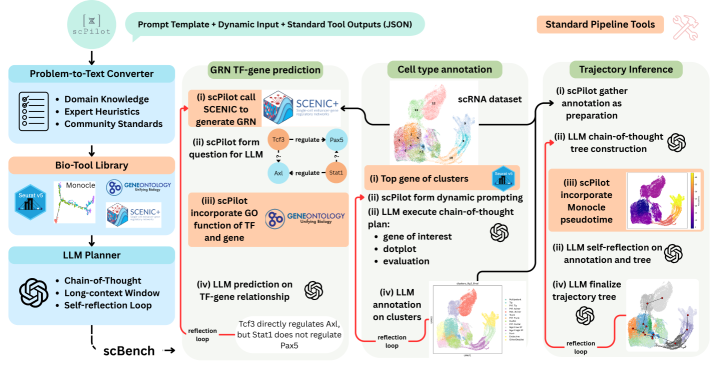
技术框架:scPilot的整体架构包括以下几个主要模块:1) 数据输入模块:负责读取和预处理scRNA-seq数据。2) LLM推理引擎:利用LLM进行逐步推理,解决单细胞分析任务。3) 生物信息学工具接口:允许LLM按需调用各种生物信息学工具,如细胞类型注释、轨迹推断和转录因子靶向工具。4) 推理结果评估模块:使用scBench数据集和评分器评估LLM的推理结果。整个流程是迭代式的,LLM可以根据中间结果和反馈进行修正和优化。
关键创新:scPilot最重要的技术创新点在于提出了组学原生推理的概念,即将LLM直接应用于原始组学数据,并允许其按需调用生物信息学工具。与现有方法相比,scPilot无需人工干预,能够自动进行单细胞分析,并提供可解释的推理过程。此外,scBench数据集的发布为评估LLM在单细胞分析中的性能提供了标准化的基准。
关键设计:在LLM推理引擎中,论文采用了逐步推理的方法,将复杂的单细胞分析任务分解为一系列简单的推理步骤。LLM需要对每个步骤进行解释和证明,并根据中间结果进行修正。此外,论文还设计了一套提示工程策略,引导LLM进行有效的推理。具体参数设置和网络结构的选择取决于所使用的LLM,例如,论文使用了o1和Gemini-2.5-Pro等模型。
🖼️ 关键图片
📊 实验亮点
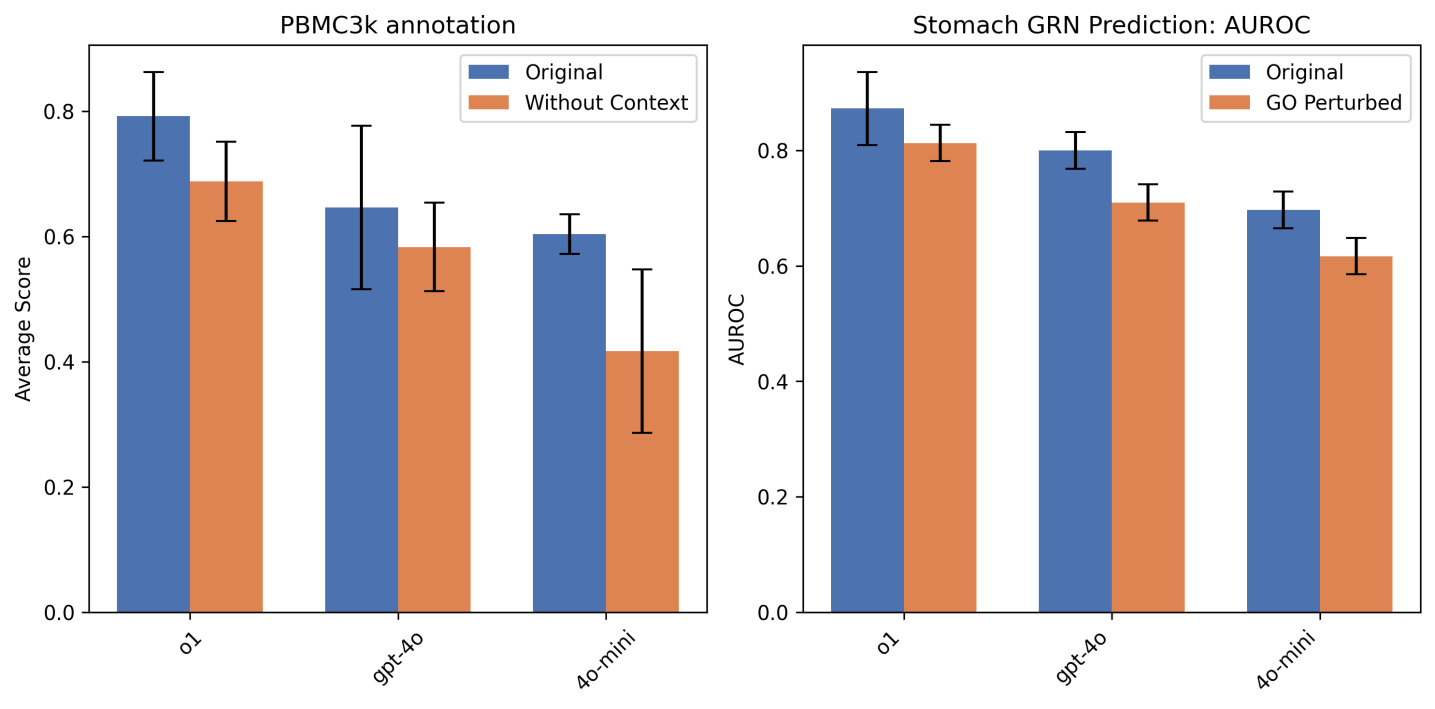
实验结果表明,scPilot在细胞类型注释任务中,通过迭代组学原生推理,平均准确率提升了11%。在发育轨迹重建任务中,Gemini-2.5-Pro模型将轨迹图编辑距离比一次性提示减少了30%。这些结果表明,scPilot能够显著提高单细胞分析的准确性和效率,并提供可解释的推理过程。
🎯 应用场景
scPilot具有广泛的应用前景,可用于加速新药研发、疾病诊断和个性化治疗。通过自动化单细胞分析,研究人员可以更快速地识别新的药物靶点、诊断生物标志物和治疗策略。此外,scPilot的可解释性推理过程有助于提高研究结果的可信度和可重复性,促进科学发现。
📄 摘要(原文)
We present scPilot, the first systematic framework to practice omics-native reasoning: a large language model (LLM) converses in natural language while directly inspecting single-cell RNA-seq data and on-demand bioinformatics tools. scPilot converts core single-cell analyses, i.e., cell-type annotation, developmental-trajectory reconstruction, and transcription-factor targeting, into step-by-step reasoning problems that the model must solve, justify, and, when needed, revise with new evidence. To measure progress, we release scBench, a suite of 9 expertly curated datasets and graders that faithfully evaluate the omics-native reasoning capability of scPilot w.r.t various LLMs. Experiments with o1 show that iterative omics-native reasoning lifts average accuracy by 11% for cell-type annotation and Gemini-2.5-Pro cuts trajectory graph-edit distance by 30% versus one-shot prompting, while generating transparent reasoning traces explain marker gene ambiguity and regulatory logic. By grounding LLMs in raw omics data, scPilot enables auditable, interpretable, and diagnostically informative single-cell analyses. Code, data, and package are available at https://github.com/maitrix-org/scPilot