MAPLE: Modality-Aware Post-training and Learning Ecosystem
作者: Nikhil Verma, Minjung Kim, JooYoung Yoo, Kyung-Min Jin, Manasa Bharadwaj, Kevin Ferreira, Ko Keun Kim, Youngjoon Kim
分类: cs.AI
发布日期: 2026-02-12
备注: 31 pages
💡 一句话要点
提出MAPLE,通过模态感知后训练提升多模态强化学习性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 强化学习 后训练 模态感知 策略优化
📋 核心要点
- 现有强化学习后训练忽略了多模态任务对不同模态的需求,导致训练效率降低和鲁棒性不足。
- MAPLE通过模态感知策略优化(MAPO)和自适应权重调整,优化不同模态组合的训练过程。
- 实验表明,MAPLE显著缩小了单/多模态准确率差距,加快了收敛速度,并提高了鲁棒性。
📝 摘要(中文)
多模态语言模型目前集成了文本、音频和视频以实现统一推理。然而,现有的强化学习后训练流程将所有输入信号视为同等重要,忽略了每个任务实际需要的模态。这种模态盲训练会增加策略梯度方差,减缓收敛速度,并降低在信号缺失、添加或重新加权的真实世界分布偏移下的鲁棒性。我们引入MAPLE,一个完整的模态感知后训练和学习生态系统,包括:(1)MAPLE-bench,第一个明确标注每个任务所需最小信号组合的基准;(2)MAPO,一个模态感知策略优化框架,通过模态需求对批次进行分层,以减少来自异构群体优势的梯度方差;(3)自适应权重和课程调度,平衡并优先考虑更难的信号组合。对损失聚合、裁剪、采样和课程设计的系统分析确立了MAPO的最佳训练策略。自适应权重和课程聚焦学习进一步提高了跨信号组合的性能。MAPLE缩小了单/多模态准确率差距30.24%,收敛速度提高了3.18倍,并在现实的减少信号访问下保持了所有模态组合的稳定性。MAPLE构成了一个可用于部署的多模态强化学习后训练完整方案。
🔬 方法详解
问题定义:现有基于强化学习的多模态模型后训练方法,通常平等对待所有模态的输入信号,忽略了不同任务对模态的依赖性。这种模态盲训练导致策略梯度方差增大,收敛速度减慢,并且在真实场景中,当某些模态缺失或噪声较大时,模型的鲁棒性会显著下降。因此,如何有效地利用不同模态的信息,并提高模型在各种模态组合下的性能,是本文要解决的核心问题。
核心思路:MAPLE的核心思路是引入模态感知机制,在强化学习的后训练过程中,显式地考虑每个任务所需的最小模态组合,并根据不同模态组合的重要性进行自适应权重调整和课程学习。通过这种方式,可以减少梯度方差,加速收敛,并提高模型在各种模态组合下的鲁棒性。
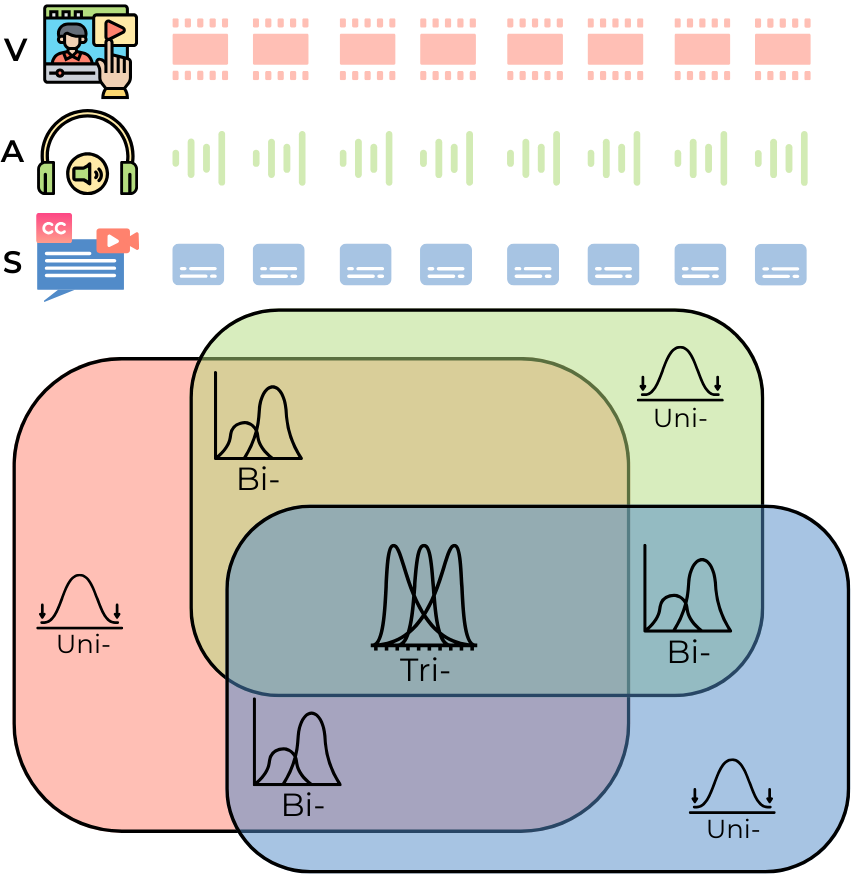
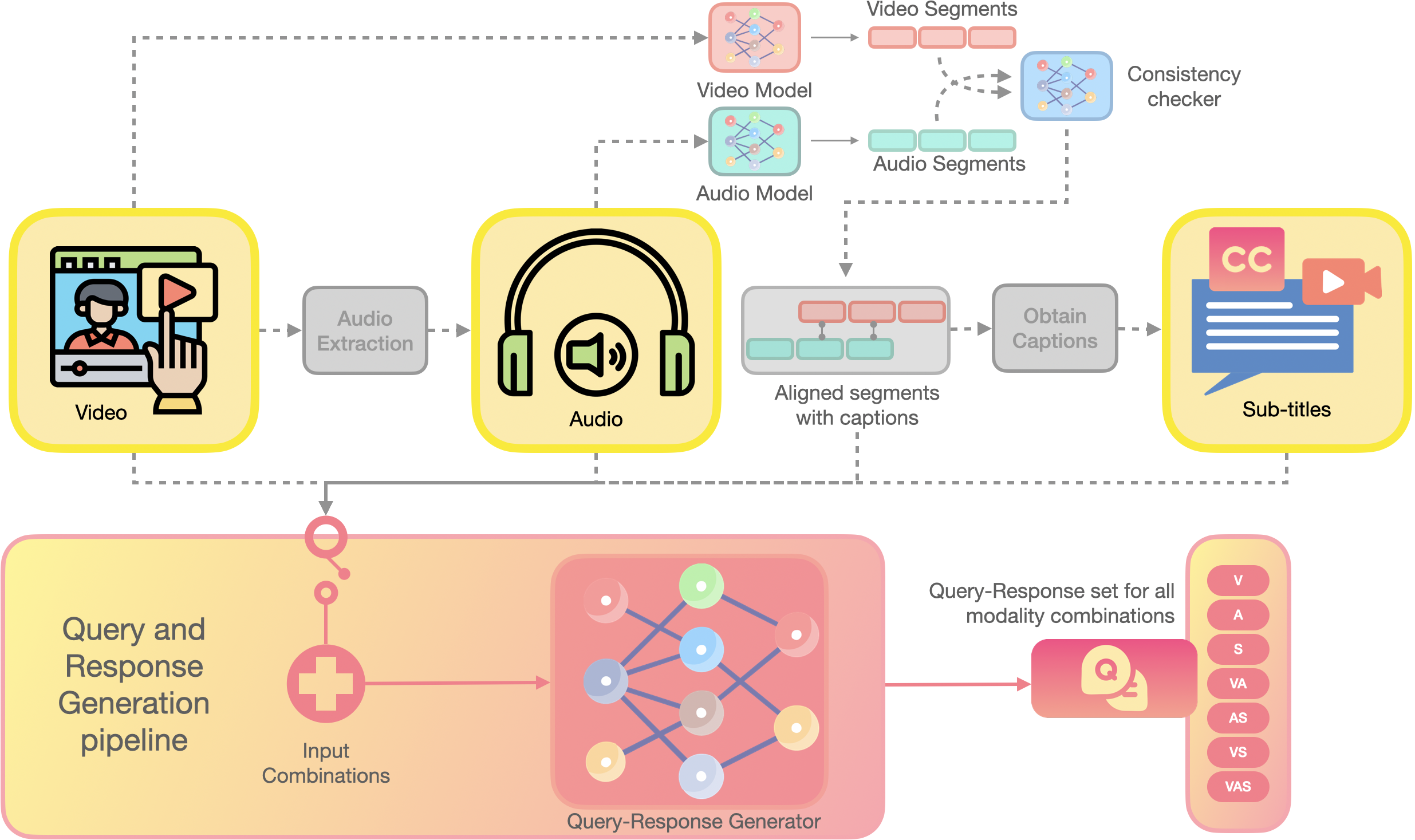
技术框架:MAPLE包含三个主要组成部分:MAPLE-bench,MAPO(Modality-Aware Policy Optimization)框架,以及自适应权重和课程调度机制。MAPLE-bench是一个基准数据集,用于评估多模态强化学习算法在不同模态组合下的性能。MAPO框架是核心的策略优化算法,它根据模态需求对批次进行分层,并使用异构群体优势来减少梯度方差。自适应权重和课程调度机制用于平衡和优先考虑更难的信号组合,从而进一步提高模型的性能。
关键创新:MAPLE的关键创新在于其模态感知的训练方法。与传统的模态盲训练方法不同,MAPLE显式地考虑了每个任务所需的最小模态组合,并根据不同模态组合的重要性进行自适应权重调整和课程学习。这种方法可以有效地减少梯度方差,加速收敛,并提高模型在各种模态组合下的鲁棒性。
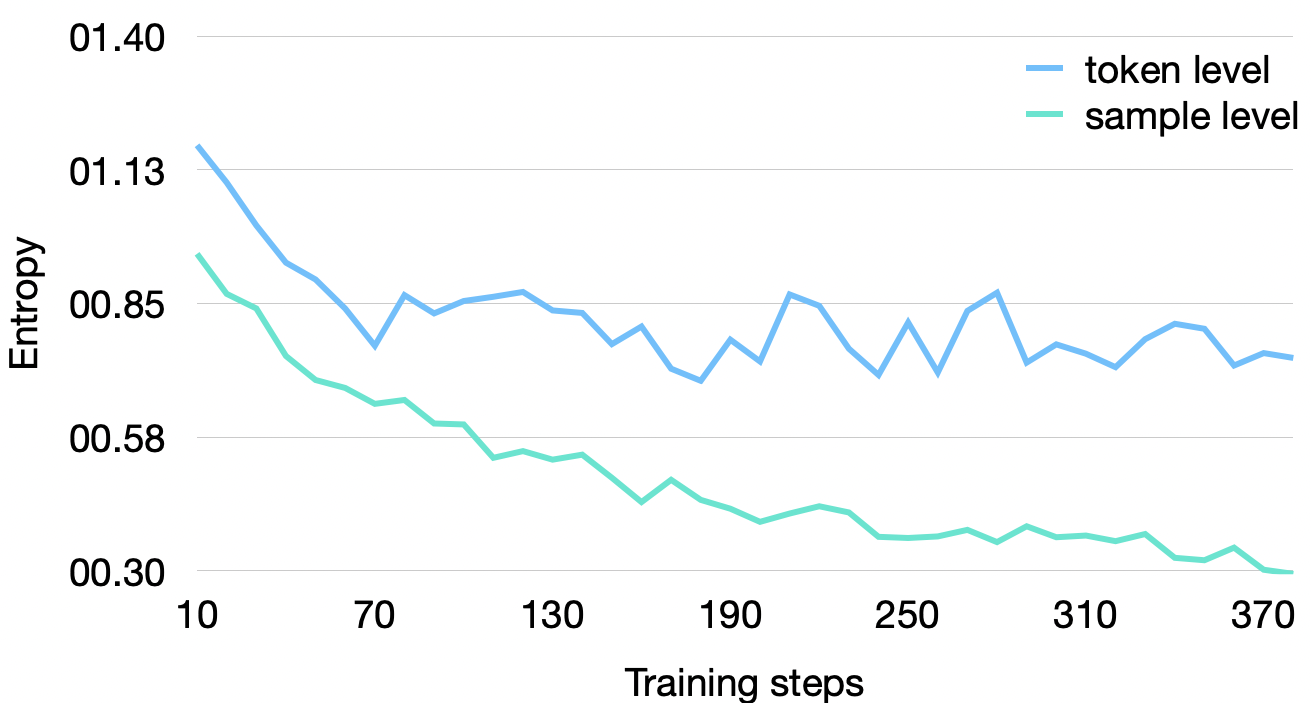
关键设计:MAPO框架的关键设计包括:(1) 模态分层批次采样,根据任务所需的模态组合对训练数据进行分层采样,确保每个批次包含具有相似模态需求的样本;(2) 异构群体优势计算,针对不同模态组合的样本,使用不同的优势函数进行计算,从而减少梯度方差;(3) 自适应权重调整,根据不同模态组合的训练难度和重要性,动态调整其权重,从而平衡不同模态组合的训练进度;(4) 课程学习,从简单的模态组合开始训练,逐渐增加难度,从而提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MAPLE在多模态强化学习任务中取得了显著的性能提升。具体来说,MAPLE缩小了单/多模态准确率差距30.24%,收敛速度提高了3.18倍,并在现实的减少信号访问下保持了所有模态组合的稳定性。这些结果表明,MAPLE是一种有效的多模态强化学习后训练方法。
🎯 应用场景
MAPLE可应用于各种需要多模态信息融合的机器人任务,例如:自动驾驶、家庭服务机器人、医疗辅助机器人等。通过提高模型在各种模态组合下的鲁棒性和泛化能力,可以使机器人在复杂的真实环境中更好地理解和执行任务。此外,该方法还可以应用于多模态对话系统、视频理解等领域。
📄 摘要(原文)
Multimodal language models now integrate text, audio, and video for unified reasoning. Yet existing RL post-training pipelines treat all input signals as equally relevant, ignoring which modalities each task actually requires. This modality-blind training inflates policy-gradient variance, slows convergence, and degrades robustness to real-world distribution shifts where signals may be missing, added, or reweighted. We introduce MAPLE, a complete modality-aware post-training and learning ecosystem comprising: (1) MAPLE-bench, the first benchmark explicitly annotating minimal signal combinations required per task; (2) MAPO, a modality-aware policy optimization framework that stratifies batches by modality requirement to reduce gradient variance from heterogeneous group advantages; (3) Adaptive weighting and curriculum scheduling that balances and prioritizes harder signal combinations. Systematic analysis across loss aggregation, clipping, sampling, and curriculum design establishes MAPO's optimal training strategy. Adaptive weighting and curriculum focused learning further boost performance across signal combinations. MAPLE narrows uni/multi-modal accuracy gaps by 30.24%, converges 3.18x faster, and maintains stability across all modality combinations under realistic reduced signal access. MAPLE constitutes a complete recipe for deployment-ready multimodal RL post-training.