Differentially Private and Communication Efficient Large Language Model Split Inference via Stochastic Quantization and Soft Prompt
作者: Yujie Gu, Richeng Jin, Xiaoyu Ji, Yier Jin, Wenyuan Xu
分类: cs.CR, cs.AI
发布日期: 2026-02-12
💡 一句话要点
提出DEL框架,通过差分隐私随机量化和软提示实现通信高效的LLM分割推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 分割推理 差分隐私 随机量化 软提示 隐私保护 通信效率
📋 核心要点
- 现有LLM推理方法依赖服务器端处理,用户需上传查询,存在隐私泄露风险,且本地部署计算成本高昂。
- DEL框架通过嵌入投影、差分隐私随机量化降低通信开销,并利用服务端软提示补偿隐私保护带来的性能损失。
- 实验证明,DEL框架在文本生成和自然语言理解任务上,有效提升了隐私保护和模型效用之间的平衡。
📝 摘要(中文)
大型语言模型(LLM)取得了显著的性能,并受到了广泛的研究关注。然而,巨大的计算需求阻碍了在资源有限的设备上的本地部署。目前流行的LLM推理范式要求用户将查询发送给服务提供商进行处理,这引发了严重的隐私问题。现有方法建议允许用户在传输之前混淆token嵌入,并利用本地模型进行去噪。然而,传输token嵌入和部署本地模型可能会导致过度的通信和计算开销,从而阻碍实际应用。在这项工作中,我们提出了DEL,一个用于差分隐私和通信高效的LLM分割推理的框架。更具体地说,提出了一种嵌入投影模块和一种差分隐私随机量化机制,以在保护隐私的方式下减少通信开销。为了消除对本地模型的需求,我们在服务器端采用软提示来补偿由隐私引起的效用下降。据我们所知,这是第一个利用软提示来改善LLM推理中隐私和效用之间权衡的工作,并且在文本生成和自然语言理解基准上的大量实验证明了所提出方法的有效性。
🔬 方法详解
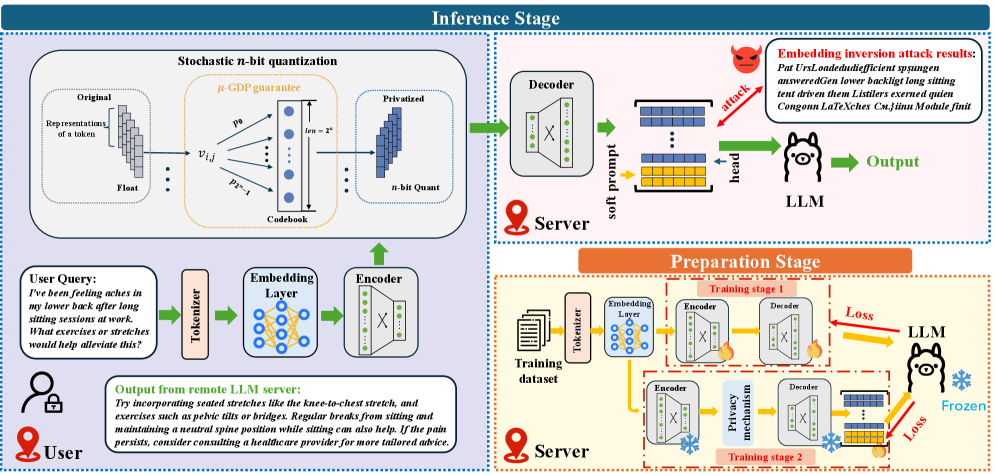
问题定义:现有LLM推理方案通常需要用户将查询发送到服务器端进行处理,这带来了严重的隐私泄露风险。同时,由于LLM模型庞大,在本地资源受限的设备上部署和运行存在计算瓶颈。现有的隐私保护方法,如混淆token嵌入和使用本地模型去噪,又引入了过高的通信和计算开销,难以实际应用。
核心思路:DEL框架的核心思路是在保护用户隐私的前提下,尽可能降低LLM分割推理过程中的通信开销,并避免在用户端部署本地模型。通过嵌入投影和差分隐私随机量化来压缩用户发送给服务器的信息,减少通信量。同时,利用服务器端的软提示技术来弥补由于隐私保护措施导致的模型性能下降。
技术框架:DEL框架主要包含以下几个模块:1) 嵌入投影模块:用于降低token嵌入的维度,减少通信量。2) 差分隐私随机量化模块:对投影后的嵌入进行量化,并添加噪声以实现差分隐私保护。3) 服务端LLM:接收量化后的嵌入,并利用软提示技术进行推理。整体流程是用户端进行嵌入投影和差分隐私量化,然后将处理后的数据发送到服务器端,服务器端利用软提示进行推理并返回结果。
关键创新:DEL框架的关键创新在于将差分隐私随机量化和软提示技术结合起来,用于LLM的分割推理。这是首次尝试使用软提示来改善LLM推理中隐私和效用之间的权衡。通过差分隐私量化保护用户隐私,并通过软提示补偿隐私保护带来的性能损失,从而在隐私保护和模型效用之间取得更好的平衡。
关键设计:嵌入投影模块可以使用线性层或非线性层实现,目标是降低嵌入维度。差分隐私随机量化模块的关键在于选择合适的量化步长和噪声水平,以在隐私保护强度和量化误差之间进行权衡。软提示模块的设计需要考虑如何有效地利用少量可学习的prompt tokens来引导LLM进行推理,例如可以通过调整prompt tokens的初始化方式和训练策略来优化性能。
🖼️ 关键图片


📊 实验亮点
论文在文本生成和自然语言理解基准上进行了大量实验,证明了DEL框架的有效性。实验结果表明,DEL框架能够在保证一定隐私保护水平的前提下,显著降低通信开销,并保持较高的模型效用。与现有方法相比,DEL框架在隐私保护和模型性能之间取得了更好的平衡。
🎯 应用场景
DEL框架适用于对隐私保护有较高要求的LLM应用场景,例如医疗诊断、金融风控、个人助手等。用户可以在本地设备上进行初步处理,保护敏感信息,同时利用云端强大的计算能力进行推理。该研究有助于推动LLM在隐私敏感领域的应用,并促进边缘计算和联邦学习的发展。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable performance and received significant research interest. The enormous computational demands, however, hinder the local deployment on devices with limited resources. The current prevalent LLM inference paradigms require users to send queries to the service providers for processing, which raises critical privacy concerns. Existing approaches propose to allow the users to obfuscate the token embeddings before transmission and utilize local models for denoising. Nonetheless, transmitting the token embeddings and deploying local models may result in excessive communication and computation overhead, preventing practical implementation. In this work, we propose \textbf{DEL}, a framework for \textbf{D}ifferentially private and communication \textbf{E}fficient \textbf{L}LM split inference. More specifically, an embedding projection module and a differentially private stochastic quantization mechanism are proposed to reduce the communication overhead in a privacy-preserving manner. To eliminate the need for local models, we adapt soft prompt at the server side to compensate for the utility degradation caused by privacy. To the best of our knowledge, this is the first work that utilizes soft prompt to improve the trade-off between privacy and utility in LLM inference, and extensive experiments on text generation and natural language understanding benchmarks demonstrate the effectiveness of the proposed method.