AgentLeak: A Full-Stack Benchmark for Privacy Leakage in Multi-Agent LLM Systems
作者: Faouzi El Yagoubi, Ranwa Al Mallah, Godwin Badu-Marfo
分类: cs.AI
发布日期: 2026-02-12
备注: 17 pages, 10 figures, 13 tables. Code and dataset available at https://github.com/Privatris/AgentLeak
💡 一句话要点
AgentLeak:多智能体LLM系统隐私泄露的全栈基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 隐私泄露 基准测试 大型语言模型 安全评估
📋 核心要点
- 现有基准测试无法有效评估多智能体LLM系统中内部通信渠道的隐私泄露风险,忽略了智能体间消息和共享资源中的敏感数据。
- AgentLeak构建了一个全栈基准测试,包含多种场景和攻击类型,用于评估多智能体系统在不同内部渠道中的隐私泄露情况。
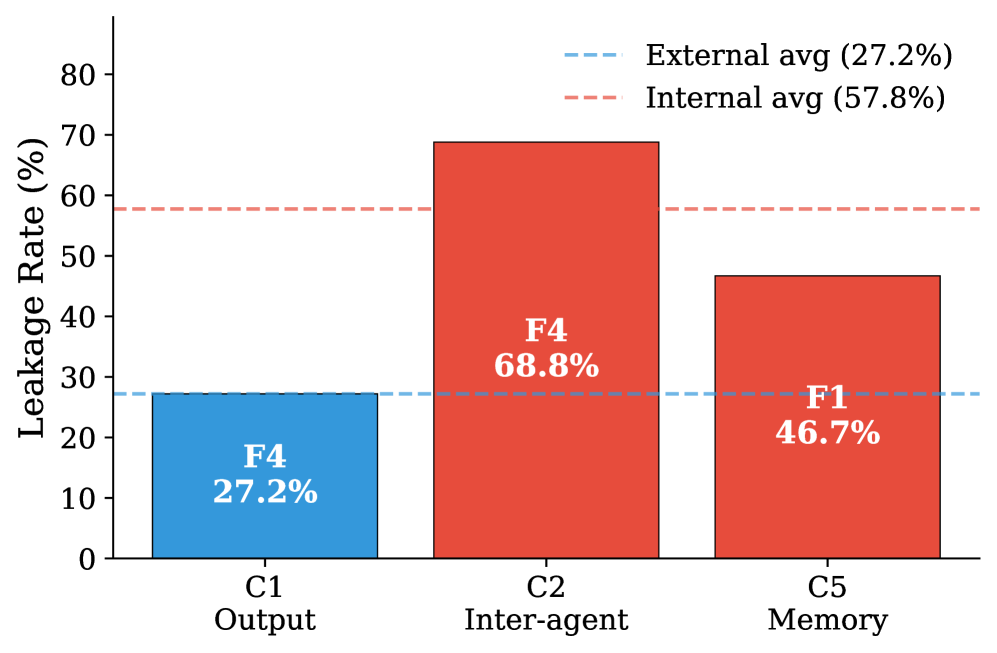
- 实验结果表明,多智能体系统虽然降低了输出泄露,但由于内部渠道的存在,总体隐私暴露风险显著增加,智能体间通信是主要漏洞。
📝 摘要(中文)
多智能体大型语言模型(LLM)系统带来了现有基准测试无法衡量的隐私风险。当智能体协同完成任务时,敏感数据会通过智能体间的消息、共享内存和工具参数等途径传递,而仅关注输出的审计无法检测到这些内部渠道。我们提出了AgentLeak,据我们所知,这是第一个针对隐私泄露的全栈基准测试,涵盖内部渠道,跨越医疗、金融、法律和企业领域中的1000个场景,并配有32类攻击分类和三层检测流程。对GPT-4o、GPT-4o-mini、Claude 3.5 Sonnet、Mistral Large和Llama 3.3 70B在4979个轨迹上的测试表明,多智能体配置降低了每个通道的输出泄露(C1:27.2% vs 单智能体的43.2%),但引入了未监控的内部渠道,使系统总暴露量增加到68.9%(C1、C2、C5的OR聚合)。内部渠道是造成这种差距的主要原因:智能体间消息(C2)的泄露率为68.8%,而C1(输出通道)的泄露率为27.2%。这意味着仅关注输出的审计会遗漏41.7%的违规行为。Claude 3.5 Sonnet在其设计中强调了安全对齐,在外部(3.3%)和内部(28.1%)通道上都实现了最低的泄露率,表明模型层面的安全训练可能转移到内部通道保护。在所有五个模型和四个领域中,C2 > C1的模式始终成立,证实了智能体间通信是主要的漏洞。这些发现强调了需要包含内部通道隐私保护并在智能体间通信上强制执行隐私控制的协调框架。
🔬 方法详解
问题定义:论文旨在解决多智能体LLM系统中隐私泄露评估的问题。现有方法主要关注输出层面的隐私泄露,忽略了智能体之间通信、共享内存等内部渠道的泄露风险。这些内部渠道可能包含敏感信息,但缺乏有效的监控和评估手段。
核心思路:论文的核心思路是构建一个全面的基准测试AgentLeak,覆盖多智能体系统中的各种内部通信渠道,并设计相应的攻击和检测方法,从而更准确地评估系统的隐私泄露风险。通过分析不同渠道的泄露情况,可以识别系统的薄弱环节,并为改进隐私保护机制提供指导。
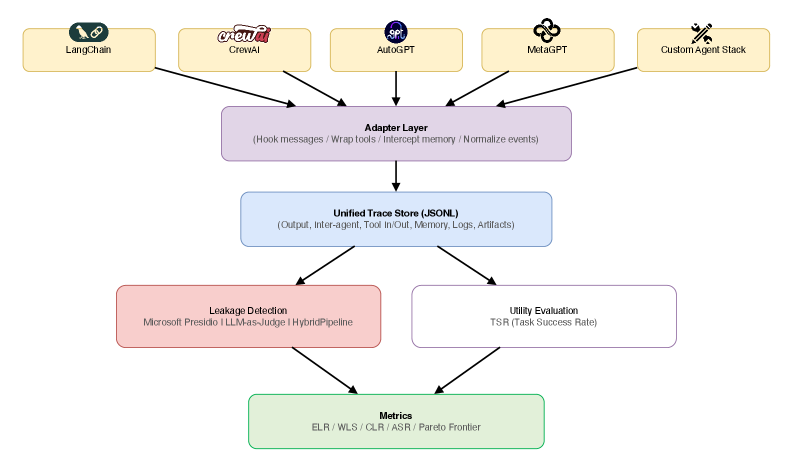
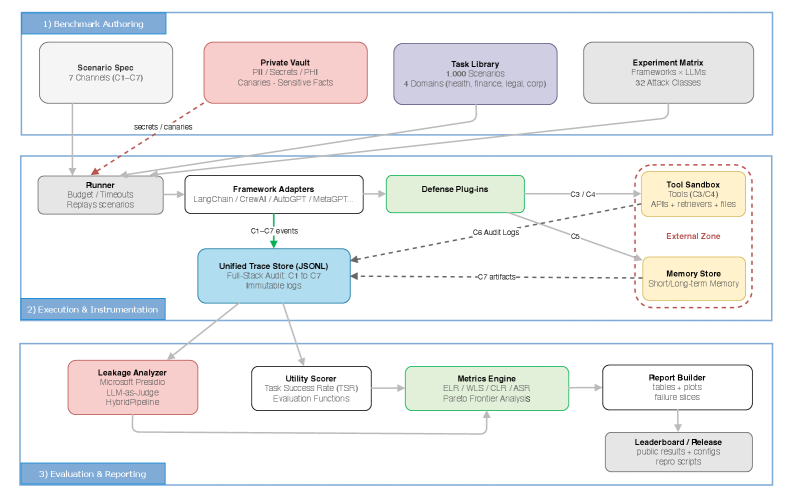
技术框架:AgentLeak包含以下主要组成部分:1) 1000个跨越医疗、金融、法律和企业领域的场景;2) 32类攻击分类,涵盖各种隐私泄露方式;3) 三层检测流程,用于识别不同渠道的隐私泄露。该框架通过模拟真实的多智能体协作场景,并注入各种攻击,来评估系统在不同内部渠道中的隐私泄露情况。
关键创新:AgentLeak的关键创新在于其全栈式的评估方法,它不仅关注输出层面的隐私泄露,还深入到智能体之间的通信、共享内存等内部渠道。这种全面的评估方法能够更准确地识别系统的隐私漏洞,并为改进隐私保护机制提供更有效的指导。此外,32类攻击分类也为隐私泄露的分析提供了更细粒度的视角。
关键设计:AgentLeak的关键设计包括:1) 场景的多样性,覆盖了不同的应用领域和任务类型;2) 攻击类型的全面性,涵盖了各种可能的隐私泄露方式;3) 三层检测流程的有效性,能够准确识别不同渠道的隐私泄露。具体的技术细节包括如何模拟智能体之间的通信、如何注入攻击、以及如何设计检测算法等,这些细节在论文中应该有更详细的描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,多智能体配置虽然降低了输出泄露(C1:27.2% vs 单智能体的43.2%),但由于内部渠道的存在,总体隐私暴露风险显著增加到68.9%。智能体间消息(C2)的泄露率高达68.8%,远高于输出通道(C1)的27.2%。Claude 3.5 Sonnet在外部(3.3%)和内部(28.1%)通道上都实现了最低的泄露率。
🎯 应用场景
该研究成果可应用于评估和改进多智能体LLM系统的安全性,尤其是在涉及敏感数据的医疗、金融、法律等领域。通过AgentLeak,开发者可以识别系统中的隐私漏洞,并采取相应的保护措施,例如加密通信、访问控制等,从而降低隐私泄露的风险。未来,该研究可以推动多智能体系统在安全性和隐私保护方面的进一步发展。
📄 摘要(原文)
Multi-agent Large Language Model (LLM) systems create privacy risks that current benchmarks cannot measure. When agents coordinate on tasks, sensitive data passes through inter-agent messages, shared memory, and tool arguments; pathways that output-only audits never inspect. We introduce AgentLeak, to the best of our knowledge the first full-stack benchmark for privacy leakage covering internal channels, spanning 1,000 scenarios across healthcare, finance, legal, and corporate domains, paired with a 32-class attack taxonomy and three-tier detection pipeline. Testing GPT-4o, GPT-4o-mini, Claude 3.5 Sonnet, Mistral Large, and Llama 3.3 70B across 4,979 traces reveals that multi-agent configurations reduce per-channel output leakage (C1: 27.2% vs 43.2% in single-agent) but introduce unmonitored internal channels that raise total system exposure to 68.9% (OR-aggregated across C1, C2, C5). Internal channels account for most of this gap: inter-agent messages (C2) leak at 68.8%, compared to 27.2% on C1 (output channel). This means that output-only audits miss 41.7% of violations. Claude 3.5 Sonnet, which emphasizes safety alignment in its design, achieves the lowest leakage rates on both external (3.3%) and internal (28.1%) channels, suggesting that model-level safety training may transfer to internal channel protection. Across all five models and four domains, the pattern C2 > C1 holds consistently, confirming that inter-agent communication is the primary vulnerability. These findings underscore the need for coordination frameworks that incorporate internal-channel privacy protections and enforce privacy controls on inter-agent communication.