Compiler-Guided Inference-Time Adaptation: Improving GPT-5 Programming Performance in Idris
作者: Minda Li, Bhaskar Krishnamachari
分类: cs.PL, cs.AI
发布日期: 2026-02-12
💡 一句话要点
编译器指导的推理时自适应:提升GPT-5在Idris编程中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编译器反馈 迭代提示 低资源编程 Idris 程序合成
📋 核心要点
- 大型语言模型在低资源编程语言上的表现有待提升,缺乏针对性优化。
- 利用编译器反馈进行迭代提示,引导模型逐步学习和改进代码。
- 实验表明,结合本地编译错误能显著提升GPT-5在Idris编程中的问题解决能力。
📝 摘要(中文)
GPT-5作为OpenAI先进的大型语言模型,在Python、C++和Java等常用编程语言中表现出强大的性能。然而,它在低资源或不太常用的语言中的能力仍未被充分探索。本研究探讨了GPT-5是否可以通过迭代的、反馈驱动的提示,有效地掌握一种不熟悉的函数式编程语言Idris。首先,我们建立了一个基线,表明在零样本提示下,该模型仅解决了Exercism平台上56个Idris练习中的22个,相对于高资源语言(Python中50个中的45个,Erlang中47个中的35个)表现不佳。然后,我们评估了几种改进策略,包括基于平台反馈的迭代提示、使用文档和错误分类指南增强提示,以及使用本地编译错误和失败的测试用例进行迭代提示。在这些方法中,结合本地编译错误产生了最显著的改进。通过这种结构化的、错误指导的改进循环,GPT-5的性能提高到了令人印象深刻的56个问题中的54个。这些结果表明,虽然大型语言模型最初可能在低资源环境中挣扎,但结构化的编译器级别反馈可以在释放其能力方面发挥关键作用。
🔬 方法详解
问题定义:论文旨在解决GPT-5等大型语言模型在低资源或不常用编程语言(如Idris)中表现不佳的问题。现有方法缺乏针对这些语言的优化,导致模型难以有效学习和应用。痛点在于模型无法充分利用编译器的反馈信息进行自我改进。
核心思路:论文的核心思路是利用编译器提供的错误信息,构建一个迭代的、反馈驱动的提示循环。通过将编译错误作为提示的一部分,引导模型逐步修正代码,从而提高其在Idris编程中的性能。这种方法模拟了人类程序员在学习新语言时,通过编译器的反馈进行调试的过程。
技术框架:整体流程包括以下几个主要步骤:1) 使用零样本提示让GPT-5尝试解决Idris编程问题;2) 收集编译器的错误信息(例如类型错误、语法错误);3) 将错误信息添加到提示中,再次让GPT-5尝试解决问题;4) 重复步骤2和3,直到问题解决或达到最大迭代次数。该框架的核心在于错误信息的提取和利用。
关键创新:最重要的技术创新点在于将编译器反馈(特别是编译错误)融入到大型语言模型的提示中,形成一个闭环的自适应学习过程。与传统的零样本或少量样本学习相比,这种方法能够更有效地利用外部信息,引导模型逐步逼近正确的解决方案。
关键设计:关键设计包括:1) 如何有效地提取和组织编译错误信息,使其能够被模型理解和利用;2) 如何设计提示,将错误信息与原始问题相结合,引导模型进行修正;3) 迭代次数的设置,需要在性能提升和计算成本之间进行权衡。论文中具体采用的错误信息包括类型错误和语法错误,提示设计上将错误信息放在问题描述之后,迭代次数设置为一个合理的上限。
🖼️ 关键图片
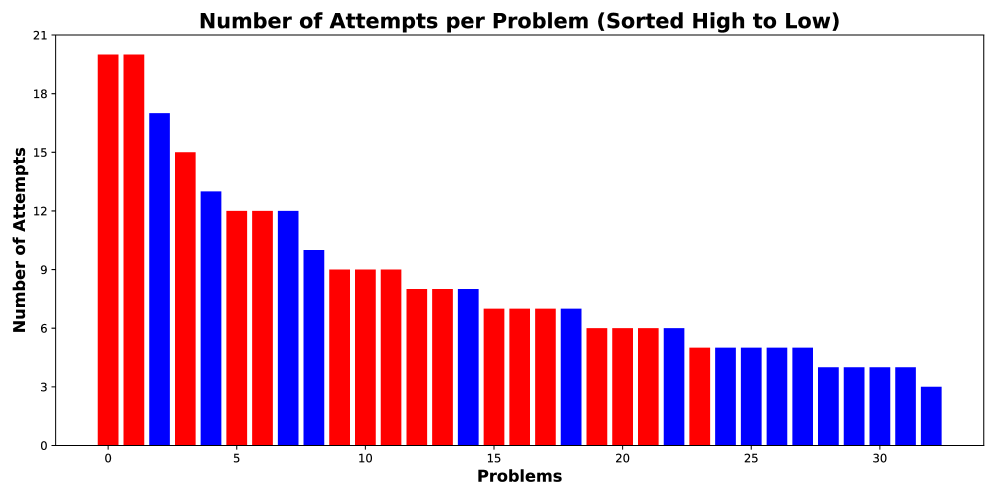
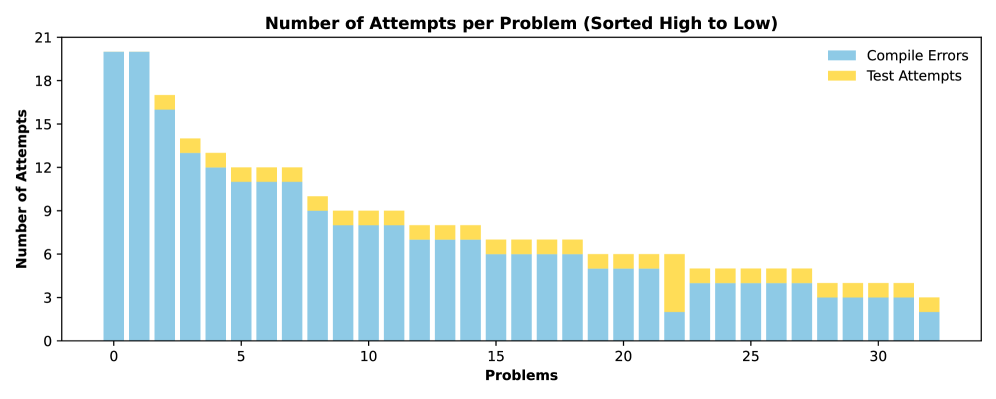
📊 实验亮点
实验结果表明,通过结合本地编译错误进行迭代提示,GPT-5在Idris编程中的问题解决能力得到了显著提升,从最初的56个问题中解决22个,提高到解决54个。相比之下,其他改进策略(如基于平台反馈的迭代提示、使用文档和错误分类指南增强提示)的提升效果相对有限。这一结果突显了编译器反馈在提升大型语言模型在低资源编程语言中的性能方面的关键作用。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种低资源编程语言中的性能,降低开发成本,并促进这些语言的普及。此外,该方法也可推广到其他领域,例如利用领域知识或专家反馈来指导模型的学习过程,提高其在特定任务上的表现。未来,可以探索更复杂的编译器反馈信息,例如性能瓶颈分析,以进一步优化代码。
📄 摘要(原文)
GPT-5, a state of the art large language model from OpenAI, demonstrates strong performance in widely used programming languages such as Python, C++, and Java; however, its ability to operate in low resource or less commonly used languages remains underexplored. This work investigates whether GPT-5 can effectively acquire proficiency in an unfamiliar functional programming language, Idris, through iterative, feedback driven prompting. We first establish a baseline showing that with zero shot prompting the model solves only 22 out of 56 Idris exercises using the platform Exercism, substantially underperforming relative to higher resource languages (45 out of 50 in Python and 35 out of 47 in Erlang). We then evaluate several refinement strategies, including iterative prompting based on platform feedback, augmenting prompts with documentation and error classification guides, and iterative prompting using local compilation errors and failed test cases. Among these approaches, incorporating local compilation errors yields the most substantial improvements. Using this structured, error guided refinement loop, GPT-5 performance increased to an impressive 54 solved problems out of 56. These results suggest that while large language models may initially struggle in low resource settings, structured compiler level feedback can play a critical role in unlocking their capabilities.