GameDevBench: Evaluating Agentic Capabilities Through Game Development
作者: Wayne Chi, Yixiong Fang, Arnav Yayavaram, Siddharth Yayavaram, Seth Karten, Qiuhong Anna Wei, Runkun Chen, Alexander Wang, Valerie Chen, Ameet Talwalkar, Chris Donahue
分类: cs.AI, cs.CL, cs.SE
发布日期: 2026-02-11
💡 一句话要点
GameDevBench:通过游戏开发评估Agent能力的多模态基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 游戏开发 Agent 多模态学习 基准测试 代码生成 图像反馈 视频反馈
📋 核心要点
- 现有Agent在代码生成方面取得了快速进展,但其多模态能力相对滞后,缺乏结合软件开发复杂性和多模态理解的评估基准。
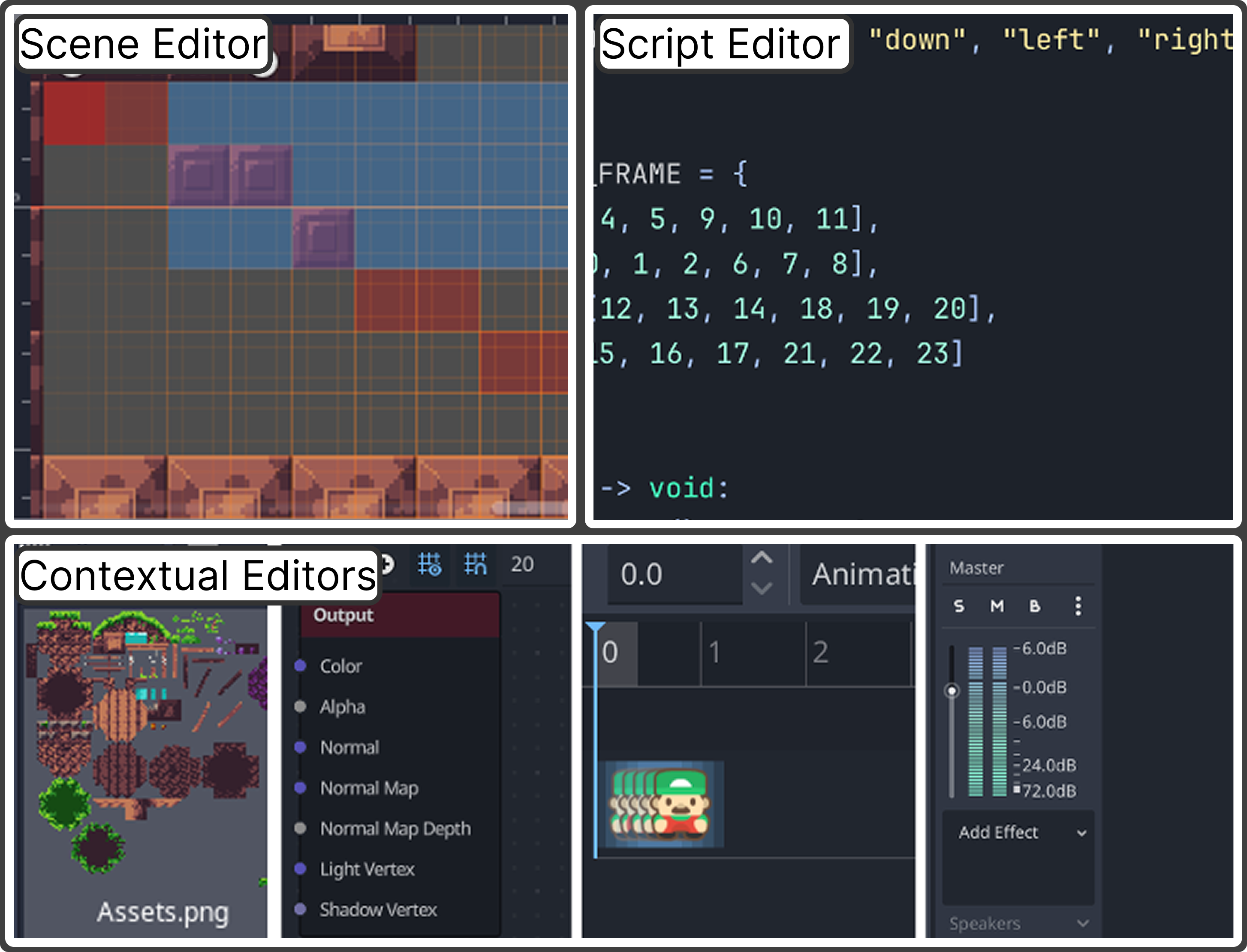
- GameDevBench通过游戏开发任务评估Agent的多模态能力,利用游戏开发中代码、图像、动画等多种模态的复杂交互。
- 实验结果表明,现有Agent在GameDevBench上表现不佳,且任务难度与多模态复杂性高度相关,引入图像/视频反馈机制可有效提升性能。
📝 摘要(中文)
本文提出了GameDevBench,这是首个用于评估Agent在游戏开发任务中表现的基准测试。游戏开发结合了软件开发的复杂性以及对深度多模态理解的需求。GameDevBench包含132个源自网络和视频教程的任务,这些任务需要显著的多模态理解,并且非常复杂——平均解决方案所需的代码行数和文件更改次数是先前软件开发基准测试的三倍以上。Agent在游戏开发方面仍然面临挑战,最佳Agent仅能解决54.5%的任务。研究发现,感知到的任务难度与多模态复杂性之间存在很强的相关性,游戏玩法导向任务的成功率从46.9%下降到2D图形任务的31.6%。为了提高多模态能力,本文为Agent引入了两种简单的基于图像和视频的反馈机制。尽管这些方法很简单,但它们始终如一地提高了性能,其中最大的变化是Claude Sonnet 4.5的性能从33.3%提高到47.7%。GameDevBench已公开发布,以支持对Agent游戏开发的进一步研究。
🔬 方法详解
问题定义:现有Agent在软件开发任务中表现出一定的能力,但缺乏针对多模态理解和操作的有效评估基准。游戏开发是一个理想的测试平台,因为它涉及复杂的代码库以及对图像、动画等多种模态资源的理解和操作。现有方法难以应对游戏开发中多模态信息的复杂性和多样性,导致Agent在游戏开发任务中表现不佳。
核心思路:本文的核心思路是构建一个专门用于评估Agent在游戏开发任务中多模态能力的基准测试,即GameDevBench。通过设计一系列源自真实游戏开发教程的任务,要求Agent理解和操作代码、图像、动画等多种模态的信息,从而全面评估Agent的多模态理解和操作能力。此外,还探索了简单的图像和视频反馈机制,以提升Agent的多模态能力。
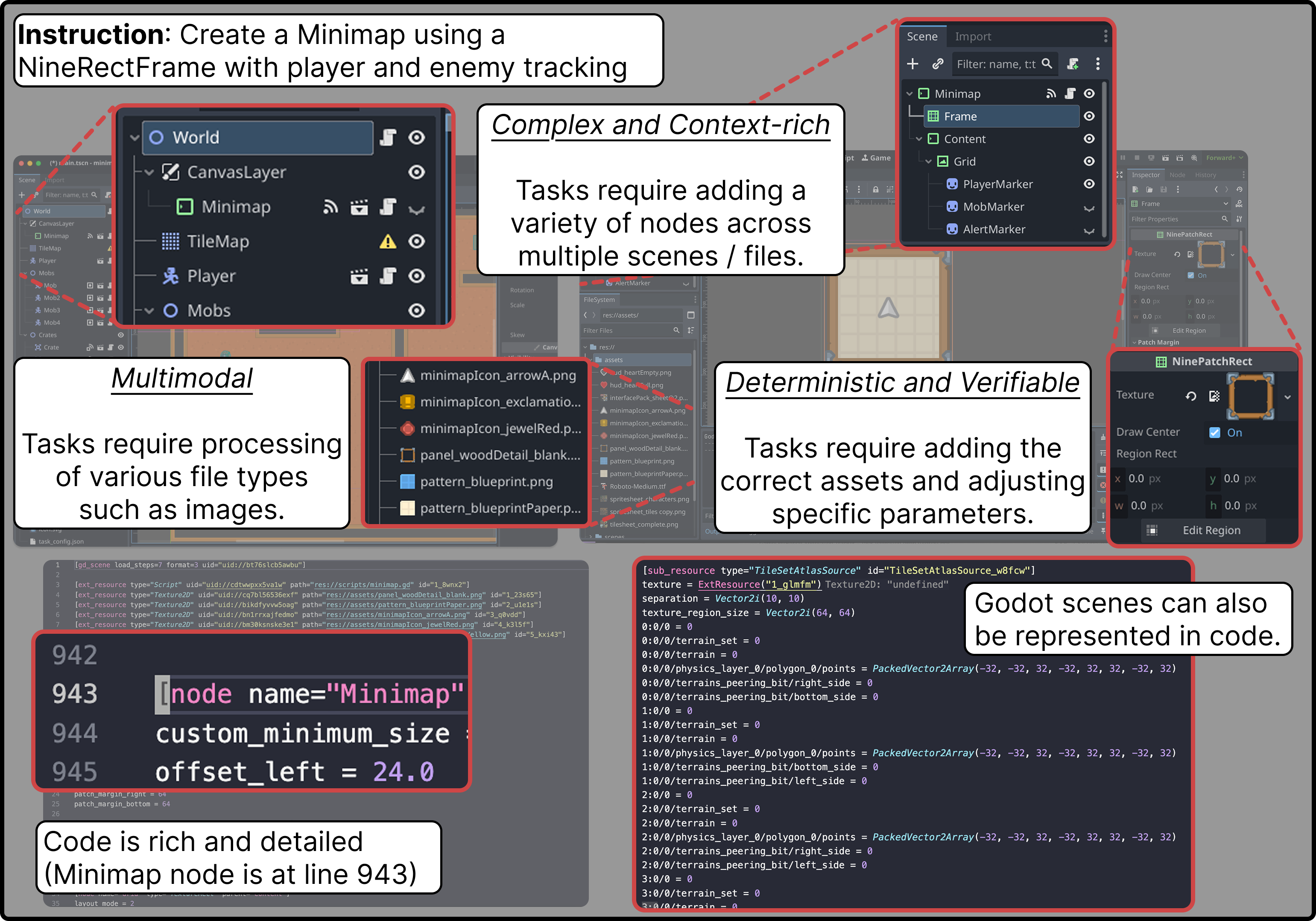
技术框架:GameDevBench包含132个游戏开发任务,这些任务源自网络和视频教程,涵盖了游戏玩法、2D图形等多个方面。每个任务都包含任务描述、代码库、资源文件等信息。Agent需要根据任务描述,修改代码库和资源文件,以完成任务。为了评估Agent的性能,本文采用了任务完成率作为指标。此外,本文还引入了两种简单的反馈机制:图像反馈和视频反馈。图像反馈是指Agent在完成任务后,可以查看游戏画面的截图,从而了解任务的完成情况。视频反馈是指Agent可以观看游戏运行的视频,从而更全面地了解任务的完成情况。
关键创新:GameDevBench是首个专门用于评估Agent在游戏开发任务中多模态能力的基准测试。与现有的软件开发基准测试相比,GameDevBench的任务更加复杂,需要Agent具备更强的多模态理解和操作能力。此外,本文还探索了简单的图像和视频反馈机制,为提升Agent的多模态能力提供了新的思路。
关键设计:GameDevBench的任务设计参考了大量的游戏开发教程,确保任务的真实性和多样性。任务的难度也经过了精心设计,既能挑战Agent的能力,又能避免任务过于困难导致Agent无法完成。图像反馈和视频反馈的设计也考虑了Agent的计算资源和时间限制,确保反馈机制的实用性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有Agent在GameDevBench上的表现仍有很大提升空间,最佳Agent仅能解决54.5%的任务。任务难度与多模态复杂性高度相关,2D图形任务的成功率明显低于游戏玩法导向任务。引入简单的图像和视频反馈机制后,Claude Sonnet 4.5的性能从33.3%显著提升至47.7%,验证了反馈机制的有效性。
🎯 应用场景
GameDevBench可用于评估和提升Agent在游戏开发、虚拟现实、人机交互等领域的应用能力。通过该基准测试,可以促进多模态Agent的研究和发展,使其能够更好地理解和操作复杂的多模态环境,从而在游戏开发中自动生成游戏内容、辅助游戏设计,甚至实现完全自主的游戏开发。
📄 摘要(原文)
Despite rapid progress on coding agents, progress on their multimodal counterparts has lagged behind. A key challenge is the scarcity of evaluation testbeds that combine the complexity of software development with the need for deep multimodal understanding. Game development provides such a testbed as agents must navigate large, dense codebases while manipulating intrinsically multimodal assets such as shaders, sprites, and animations within a visual game scene. We present GameDevBench, the first benchmark for evaluating agents on game development tasks. GameDevBench consists of 132 tasks derived from web and video tutorials. Tasks require significant multimodal understanding and are complex -- the average solution requires over three times the amount of lines of code and file changes compared to prior software development benchmarks. Agents still struggle with game development, with the best agent solving only 54.5% of tasks. We find a strong correlation between perceived task difficulty and multimodal complexity, with success rates dropping from 46.9% on gameplay-oriented tasks to 31.6% on 2D graphics tasks. To improve multimodal capability, we introduce two simple image and video-based feedback mechanisms for agents. Despite their simplicity, these methods consistently improve performance, with the largest change being an increase in Claude Sonnet 4.5's performance from 33.3% to 47.7%. We release GameDevBench publicly to support further research into agentic game development.