Fine-Tuning GPT-5 for GPU Kernel Generation
作者: Ali Tehrani, Yahya Emara, Essam Wissam, Wojciech Paluch, Waleed Atallah, Łukasz Dudziak, Mohamed S. Abdelfattah
分类: cs.DC, cs.AI, cs.LG
发布日期: 2026-02-11
💡 一句话要点
通过强化学习微调GPT-5,显著提升GPU Kernel代码生成质量与效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GPU内核生成 强化学习 大型语言模型 代码生成 AI辅助编程
📋 核心要点
- 高效GPU内核开发对AI系统至关重要,但面临硬件复杂、优化专业性要求高等挑战,现有方法难以有效生成高质量代码。
- 论文提出使用强化学习微调GPT-5,利用Makora环境和工具,克服数据稀缺和编译器偏差等问题,提升模型在特定领域的性能。
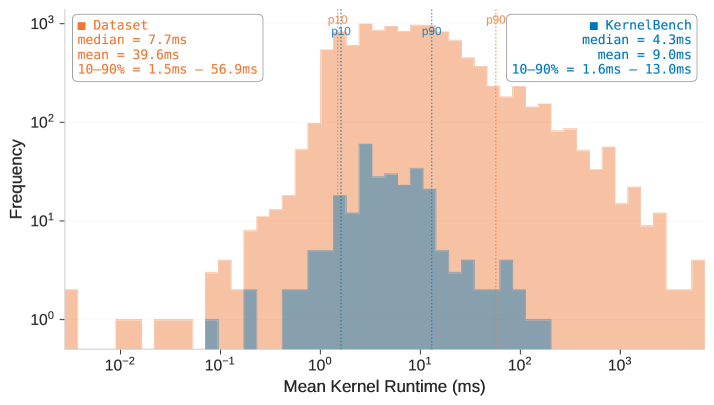
- 实验结果表明,微调后的GPT-5在内核正确率和性能上均显著提升,超越现有模型,并能有效解决KernelBench中的大量问题。
📝 摘要(中文)
开发高效的GPU内核对于扩展现代AI系统至关重要,但由于复杂的硬件架构和专业的优化知识,这项任务仍然具有挑战性。虽然大型语言模型(LLM)在通用顺序代码生成方面表现出强大的能力,但由于高质量标注训练数据的稀缺、生成合成解决方案时编译器偏差以及跨硬件世代的泛化能力有限,它们在GPU代码生成方面面临重大挑战。这使得监督微调(SFT)无法成为改进当前LLM的可扩展方法。相比之下,强化学习(RL)提供了一种数据高效且自适应的替代方案,但需要访问相关工具、仔细选择训练问题以及强大的评估环境。我们介绍了Makora的环境和工具,用于对前沿模型进行强化学习微调,并报告了我们对GPT-5进行Triton代码生成微调的结果。在单次尝试设置中,与基线GPT-5相比,我们微调后的模型将内核正确率从43.7%提高到77.0%(+33.3个百分点),并将优于TorchInductor的问题比例从14.8%提高到21.8%(+7个百分点),同时超过了KernelBench上先前的最先进模型。当集成到完整的编码代理中时,它能够解决扩展的KernelBench套件中高达97.4%的问题,在72.9%的问题上优于PyTorch TorchInductor编译器,几何平均加速比为2.12倍。我们的工作表明,通过强化学习进行有针对性的后训练可以释放LLM在高度专业化的技术领域的能力,在这些领域中,传统监督学习受到数据可用性的限制,从而为AI辅助加速器编程开辟了新的途径。
🔬 方法详解
问题定义:论文旨在解决LLM在GPU内核代码生成方面的不足。现有方法,如监督微调,受限于高质量训练数据的稀缺和编译器偏差,导致模型泛化能力差,难以生成高效、正确的GPU内核代码。
核心思路:论文的核心思路是利用强化学习(RL)对GPT-5进行微调。RL具有数据效率高和自适应性强的优点,能够克服监督学习的局限性,通过奖励机制引导模型生成更优的GPU内核代码。这种方法允许模型在与环境交互的过程中学习,从而更好地适应特定硬件和优化目标。
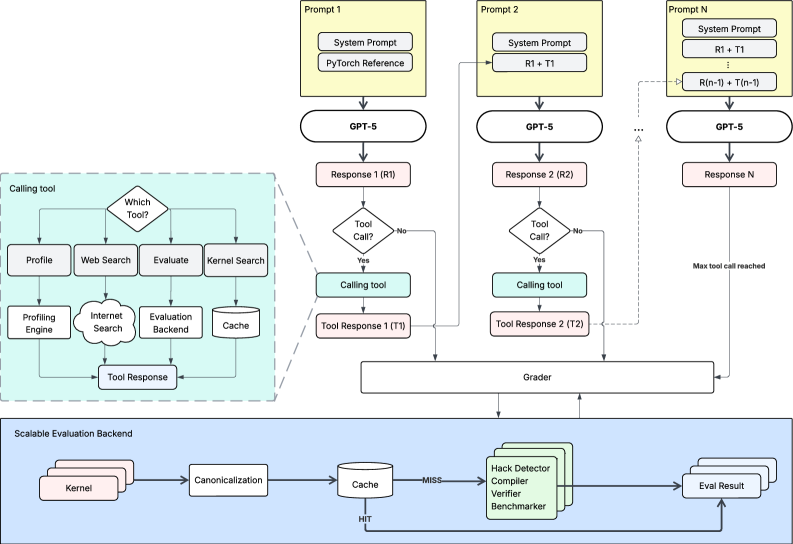
技术框架:整体框架包括以下几个主要部分:1) Makora环境:提供用于训练和评估GPU内核代码生成模型的环境,包括编译器、测试用例和性能评估工具。2) GPT-5模型:作为基础模型,通过RL进行微调。3) 强化学习算法:用于训练GPT-5模型,目标是最大化生成的GPU内核代码的性能和正确性。4) 奖励函数:根据生成的代码的性能和正确性,为模型提供奖励信号。
关键创新:最重要的技术创新点在于将强化学习应用于LLM的微调,以解决GPU内核代码生成问题。与传统的监督学习方法相比,RL能够更好地利用有限的数据,并克服编译器偏差的影响。此外,Makora环境的构建也为RL微调提供了必要的工具和平台。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构。但是,可以推断,奖励函数的设计至关重要,需要综合考虑生成的代码的性能(例如,执行速度)和正确性(例如,通过测试用例)。此外,强化学习算法的选择也可能对最终结果产生影响。具体的技术细节可能需要参考相关的强化学习文献。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过强化学习微调的GPT-5在单次尝试设置中,内核正确率从43.7%提升至77.0%,优于TorchInductor的问题比例从14.8%提升至21.8%,超过了KernelBench上的SOTA模型。集成到编码代理后,能解决97.4%的KernelBench问题,并在72.9%的问题上优于PyTorch TorchInductor编译器,几何平均加速比为2.12倍。
🎯 应用场景
该研究成果可应用于AI加速器编程领域,通过AI辅助自动生成高效的GPU内核代码,降低开发门槛,提升开发效率。这对于推动AI技术在各个领域的应用具有重要意义,尤其是在需要高性能计算的场景下,如深度学习、科学计算等。
📄 摘要(原文)
Developing efficient GPU kernels is essential for scaling modern AI systems, yet it remains a complex task due to intricate hardware architectures and the need for specialized optimization expertise. Although Large Language Models (LLMs) demonstrate strong capabilities in general sequential code generation, they face significant challenges in GPU code generation because of the scarcity of high-quality labeled training data, compiler biases when generating synthetic solutions, and limited generalization across hardware generations. This precludes supervised fine-tuning (SFT) as a scalable methodology for improving current LLMs. In contrast, reinforcement learning (RL) offers a data-efficient and adaptive alternative but requires access to relevant tools, careful selection of training problems, and a robust evaluation environment. We present Makora's environment and tools for reinforcement learning finetuning of frontier models and report our results from fine-tuning GPT-5 for Triton code generation. In the single-attempt setting, our fine-tuned model improves kernel correctness from 43.7% to 77.0% (+33.3 percentage points) and increases the fraction of problems outperforming TorchInductor from 14.8% to 21.8% (+7 percentage points) compared to baseline GPT-5, while exceeding prior state-of-the-art models on KernelBench. When integrated into a full coding agent, it is able to solve up to 97.4% of problems in an expanded KernelBench suite, outperforming the PyTorch TorchInductor compiler on 72.9% of problems with a geometric mean speedup of 2.12x. Our work demonstrates that targeted post-training with reinforcement learning can unlock LLM capabilities in highly specialized technical domains where traditional supervised learning is limited by data availability, opening new pathways for AI-assisted accelerator programming.