FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
作者: Qixing Zhou, Jiacheng Zhang, Haiyang Wang, Rui Hao, Jiahe Wang, Minghao Han, Yuxue Yang, Shuzhe Wu, Feiyang Pan, Lue Fan, Dandan Tu, Zhaoxiang Zhang
分类: cs.SE, cs.AI
发布日期: 2026-02-11
备注: Accepted by ICLR 2026
💡 一句话要点
FeatureBench:面向复杂特性开发的Agentic Coding基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic Coding 基准测试 软件开发 大型语言模型 自动化测试
📋 核心要点
- 现有Agentic Coding基准测试任务范围有限,依赖非执行评估,缺乏自动化更新,难以全面评估Agent的编码能力。
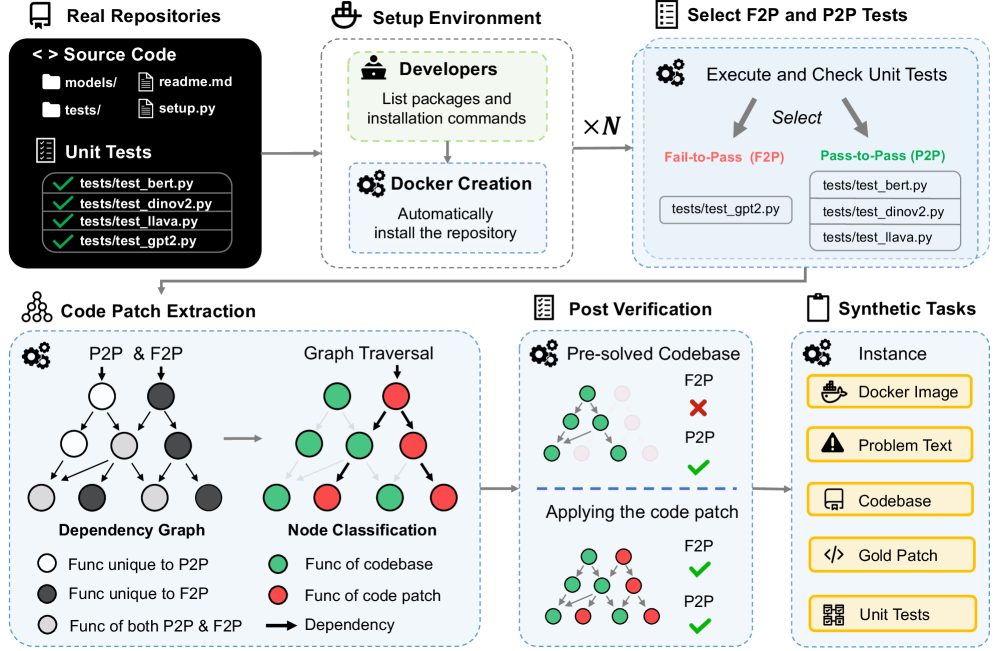
- FeatureBench通过追踪单元测试的依赖关系,自动从代码仓库中提取特性级别的编码任务,并构建可执行的评估环境。
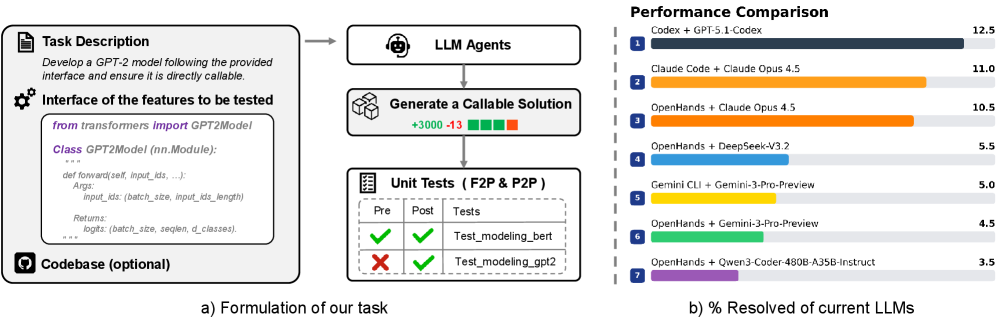
- 实验表明,即使是强大的Agent模型在FeatureBench上的表现也远低于现有基准,揭示了Agentic Coding的巨大提升空间。
📝 摘要(中文)
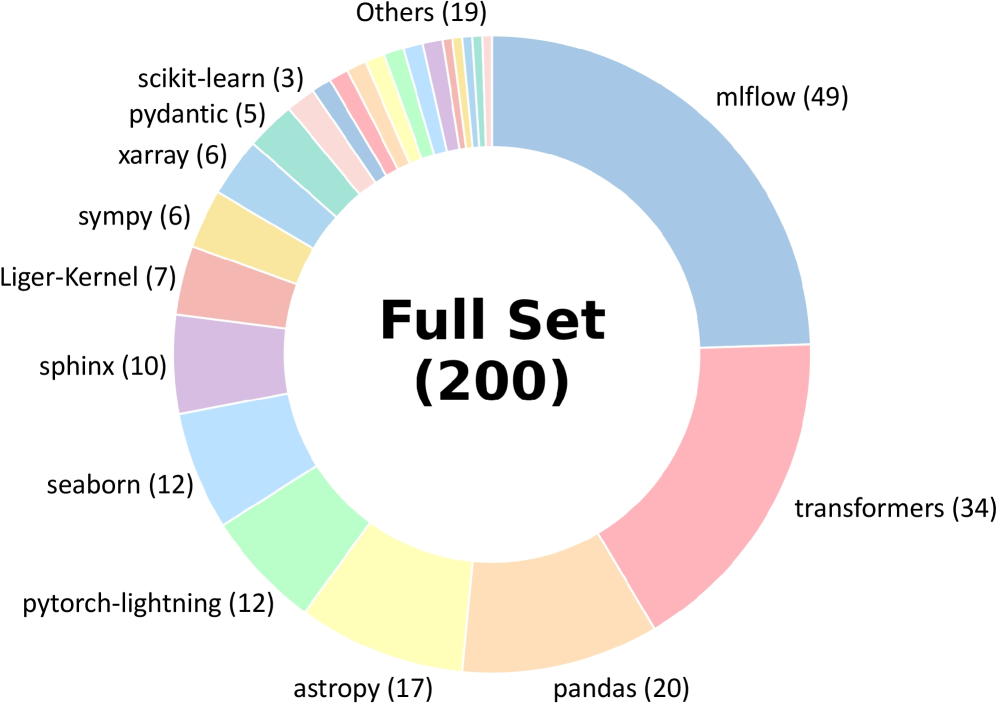
大型语言模型驱动的Agent越来越多地应用于软件行业,它们以合作者甚至自主开发者的身份贡献代码。随着它们影响力的增长,评估当前Agent编码能力的边界变得至关重要。然而,现有的Agentic Coding基准测试覆盖的任务范围有限,例如,单个PR中的错误修复,并且通常依赖于不可执行的评估或缺乏自动化的方法来持续更新评估覆盖范围。为了解决这些问题,我们提出了FeatureBench,一个旨在评估Agentic Coding在端到端、面向特性的软件开发中性能的基准测试。FeatureBench包含一个基于执行的评估协议和一个可扩展的测试驱动方法,该方法以最小的人工工作量自动地从代码仓库中派生任务。通过沿着依赖关系图从单元测试进行追踪,我们的方法可以识别跨越多个提交和PR、分散在开发时间线上的特性级编码任务,同时确保分离后其他功能的正常运行。使用这个框架,我们在基准测试的第一个版本中从24个开源仓库中整理了200个具有挑战性的评估任务和3825个可执行环境。实证评估表明,最先进的Agentic模型,如Claude 4.5 Opus,在SWE-bench上达到了74.4%的解决率,但在我们的测试中仅成功解决了11.0%的任务,这为推进Agentic Coding开辟了新的机会。此外,受益于我们的自动化任务收集工具包,FeatureBench可以随着时间的推移轻松扩展和更新,以减轻数据泄露。构建环境的固有可验证性也使我们的方法可能对Agent训练有价值。
🔬 方法详解
问题定义:现有Agentic Coding基准测试主要关注简单的bug修复或单个PR内的任务,缺乏对复杂特性开发的全面评估。这些基准测试往往依赖于人工评估或非可执行的测试,难以保证评估的客观性和可扩展性。此外,数据泄露也是一个潜在的问题,因为基准测试的数据集可能被Agent模型提前学习。
核心思路:FeatureBench的核心思路是通过自动化地从真实的代码仓库中提取特性级别的编码任务,并构建可执行的评估环境,从而更全面、客观地评估Agentic Coding的能力。通过追踪单元测试的依赖关系,可以识别跨越多个提交和PR的复杂任务,并确保任务的独立性和可执行性。
技术框架:FeatureBench的整体框架包括以下几个主要模块:1) 任务提取模块:该模块通过分析代码仓库的依赖关系图,从单元测试开始追踪,识别与特定特性相关的代码变更。2) 环境构建模块:该模块负责构建可执行的评估环境,包括必要的依赖项和测试数据。3) 评估模块:该模块运行Agent生成的代码,并根据单元测试的结果评估Agent的性能。4) 数据管理模块:该模块负责管理和更新基准测试的数据集,以减轻数据泄露的风险。
关键创新:FeatureBench最重要的技术创新点在于其自动化的任务提取方法。与现有基准测试相比,FeatureBench无需人工标注或干预,即可从真实的代码仓库中提取具有挑战性的编码任务。这种自动化方法不仅提高了基准测试的可扩展性,而且保证了任务的客观性和真实性。
关键设计:FeatureBench的关键设计包括:1) 基于依赖关系图的任务提取算法,该算法可以有效地识别与特定特性相关的代码变更。2) 可执行的评估环境,该环境可以确保Agent生成的代码能够被正确执行和评估。3) 自动化的数据更新机制,该机制可以定期更新基准测试的数据集,以减轻数据泄露的风险。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是最先进的Agentic模型(如Claude 4.5 Opus)在FeatureBench上的表现也远低于现有基准测试(如SWE-bench)。Claude 4.5 Opus在SWE-bench上达到了74.4%的解决率,但在FeatureBench上仅成功解决了11.0%的任务。这表明现有Agentic模型在处理复杂特性开发任务时仍然面临很大的挑战,FeatureBench为未来的研究提供了新的方向。
🎯 应用场景
FeatureBench可用于评估和改进Agentic Coding模型在复杂软件开发任务中的性能。它能够帮助研究人员和开发者更好地了解Agent的优势和局限性,并开发更有效的Agentic Coding工具。此外,FeatureBench还可以作为Agent训练的数据集,提高Agent在真实软件开发场景中的适应性。
📄 摘要(原文)
Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.